Quand devez-vous utiliser HDInsight Interactive Query ?
En tant qu’analyste d’entreprise, vous devez déterminer le type de cluster HDInsight le plus approprié à créer pour générer votre solution. Les clusters Interactive Query fournissent un certain nombre de fonctionnalités et d’options d’interopérabilité qui les rendent particulièrement intéressants pour les analystes d’entreprise qui connaissent bien le langage SQL. Ces clusters sont parfaits pour les utilisateurs qui souhaitent travailler avec des outils décisionnels et qui ont besoin d’exécuter des requêtes interactives rapides. Ils présentent d’autres avantages, notamment la prise en charge d’une grande diversité de formats de fichier, de la concurrence et des transactions atomiques, cohérentes, isolées et durables (ACID). Qui plus est, ils s’intègrent avec Apache Ranger pour un contrôle granulaire des données au niveau des lignes et des colonnes.
Notes
Le contenu de ce module concerne les clusters Interactive Query créés pour HDInsight 4,0, qui utilisent Hive 3.1 et LLAP (également appelé Hive LLAP).
Vous disposez d’un jeu de données volumineux qui est prêt à être interrogé.
Les clusters Interactive Query conviennent idéalement aux jeux de données volumineux qui peuvent être interrogés tels quels, ou moyennant des transformations minimales. Ils conviennent dans les situations où vous êtes amené à effectuer une série de requêtes sur des données et où vous avez besoin de réponses immédiates. Les clusters Interactive Query ne sont pas optimisés pour effectuer des calculs par lots sur de longues périodes. Interactive Query prend en charge les formats de fichier suivants : ORC, Parquet, CSV, Avro, JSON, texte et TSV.
Vous avez besoin de fonctionnalités de type SQL
Lorsque vous avez besoin d’exécuter des requêtes interactives et ad hoc à une latence inférieure à une seconde sur des Big Data hébergés dans votre stockage Azure et dans Azure Data Lake Storage, et que vous préférez une expérience de type SQL, les clusters Azure HDInsight Interactive Query sont un excellent choix. En tant qu’analyste d’entreprise, vous êtes très familiarisé avec les tables SQL et savez parfaitement créer des requêtes en langage SQL. Apache Hadoop est un puissant outil qui permet d’effectuer des analyses Big Data. Le fait qu’Apache Hadoop utilise l’infrastructure MapReduce et ses API Java peut être bloquant si vos compétences en programmation Java sont un peu rouillées. Dans ce cas, HDInsight Interactive Query est mieux adapté, car il s’appuie sur Apache Hadoop, tout en restant plus simple à utiliser pour quiconque a un minimum d’expérience de SQL. Interactive Query utilise des tables Hive de type SQL pour traiter les données et un langage de requête de type SQL, appelé HiveQL, pour interroger les données. L’utilisation de Hive est moins complexe que le traitement des données à l’aide de MapReduce dans Apache Hadoop. Hive permet de déployer des solutions dans votre entreprise plus rapidement et plus efficacement.
Requêtes interactives rapides avec mise en cache intelligente
Les clusters Interactive Query utilisent des techniques de mise en cache intelligente pour hiérarchiser les données sur la RAM dynamique, un disque SSD du nœud de cluster local et des systèmes de stockage distants tels que Azure Blob et Azure Data Lake Storage pour obtenir des résultats de requête interactifs et rapides sur le Big Data. Un bon exemple de technique de mise en cache avancée est le cache de texte dynamique, qui convertit à la volée les données CSV en un format en mémoire optimisé, de manière à obtenir une mise en cache dynamique et à permettre aux requêtes de déterminer quelles données sont mises en cache. Avec cette fonctionnalité, vous n’avez pas besoin de charger et de transformer vos données au préalable. Vous pouvez charger les données vers le stockage Azure dans leur format d’origine et commencer immédiatement à les interroger. Cela signifie également que les requêtes sont plus performantes lors de leur deuxième exécution. La première fois qu’une requête est exécutée, les données sont lues à partir de la couche de stockage des données d’entreprise dans le stockage Azure ou dans Azure Data Lake Gen2. Les données sont ensuite mises en cache dans le cache en mémoire partagé du cluster. Lors de l’exécution suivante de la requête, les données sont simplement récupérées à partir du cache en mémoire partagé, ce qui permet de gagner du temps en évitant d’avoir à récupérer les données dans la couche de stockage distante.
Exécuter des requêtes à l’aide d’outils populaires
Interactive Query facilite l’utilisation du Big Data à l’aide des outils décisionnels que vous connaissez, tels que Microsoft Power BI et Tableau. Dans l’analytique Big Data, les organisations craignent de plus en plus que leurs utilisateurs finaux n’obtiennent pas suffisamment de valeur des systèmes d’analyse, car ils sont souvent trop difficiles et supposent d’utiliser des outils peu familiers et difficiles à prendre en main. HDInsight Interactive Query résout ce problème en limitant au minimum la formation des nouveaux utilisateurs pour leur permettre de dériver des insights de leurs données. Les utilisateurs peuvent écrire des requêtes HiveQL de type SQL dans les outils qu’ils utilisent déjà. Ces outils incluent Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio et Hive ODBC. Vous ne pouvez pas exécuter de requêtes sur votre cluster Interactive Query à l’aide de la console Hive, de Templeton, de l’interface de commande Azure Classic ou d’Azure PowerShell.
Vous avez besoin d’une cohérence et d’une concurrence des transactions
Avec l’introduction d’une fonction de gestion des ressources fine, de la préemption et du partage des données mises en cache sur l’ensemble des requêtes et des utilisateurs, Interactive Query prend en charge très facilement les utilisateurs simultanés. HDInsight prend en charge la création de plusieurs clusters sur un stockage Azure partagé. Le metastore Hive permet d’obtenir un niveau de concurrence élevé. Vous pouvez mettre à l’échelle la concurrence en ajoutant des nœuds de cluster ou en ajoutant des clusters qui pointent vers les mêmes métadonnées et données sous-jacentes. Interactive Query prend également en charge les transactions de base de données atomiques, cohérentes, isolées et durables (ACID). Les transactions ACID permettent de contenir une transaction dans une seule unité, même si cette transaction contient plusieurs opérations. Ainsi, en cas d’échec d’une opération isolée au niveau de la transaction, la totalité de l’opération peut être restaurée, ce qui garantit la cohérence et la précision des données.
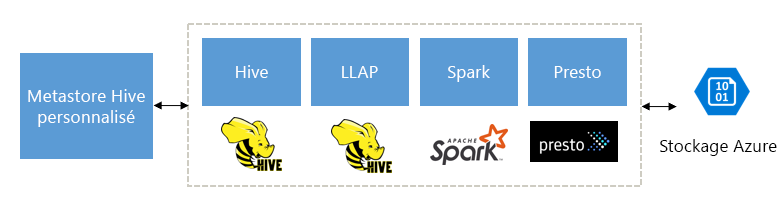
Conçu pour compléter Spark, Hive, Presto et d’autres moteurs de Big Data
HDInsight Interactive Query est conçu pour fonctionner correctement avec les moteurs de Big Data aussi populaires que Apache Spark, Hive, Presto, etc. Ce type de requête est particulièrement utile, car vos utilisateurs peuvent choisir l’un de ces outils pour exécuter leur analyse. Avec l’architecture de métadonnées et de données partagées de HDInsight pour les tables externes, les utilisateurs peuvent créer plusieurs clusters avec un moteur identique ou différent pointant vers les mêmes métadonnées et données sous-jacentes. Cette fonctionnalité est un concept puissant, car vous n’êtes plus limité par une technologie d’analyse donnée.