Implémenter des contrôles de compatibilité pour les données sensibles
Il est important d’implémenter des contrôles de conformité après la migration de votre base de données pour garantir que vos données restent sécurisées et conformes aux réglementations en vigueur. La migration vers un nouvel environnement, tel que Azure SQL, donne accès à de nouvelles fonctionnalités de sécurité.
Explorer l’audit du serveur et de la base de données
L'audit Azure SQL effectue le suivi des événements de base de données et les enregistre dans un journal d'audit dans votre compte de stockage Azure, dans l’espace de travail Log Analytics ou dans Event Hubs. En outre, il facilite la maintenance de la conformité réglementaire, l’analyse des modèles d’activité et la détection des écarts susceptibles d’indiquer des violations de sécurité.
Vous pouvez définir des stratégies au niveau du serveur et de la base de données. Les stratégies de serveur couvrent automatiquement les bases de données nouvelles et existantes dans Azure.
- L’activation de l’audit du serveur déclenche l’audit de la base de données, quels que soient ses propres paramètres d’audit.
- Vous pouvez activer l’audit au niveau de la base de données, ce qui permet de faire coexister simultanément les règles liées au serveur et à la base de données.
- L’audit est activé automatiquement sur les réplicas en lecture seule.
Il est préférable de ne pas activer l’audit de serveur et l’audit de base de données en même temps, sauf dans les scénarios suivants :
Vous avez besoin d’un compte de stockage distinct, d’une période de rétention ou d’un espace de travail Log Analytics pour une base de données déterminée.
Un audit est nécessaire pour une base de données spécifique, distincte des autres sur le serveur, et comportant des types d’événements ou des catégories uniques.
Pour tous les autres cas de figure, il est conseillé d’activer uniquement l’audit au niveau du serveur et de laisser l’audit au niveau de la base de données désactivé pour toutes les bases de données.
La stratégie d’audit par défaut pour SQL Database inclut l’ensemble suivant de groupes d’actions :
| Groupe d’actions | Définition |
|---|---|
| BATCH_COMPLETED_GROUP | Audite toutes les requêtes et les procédures stockées exécutées sur la base de données. |
| SUCCESSFUL_DATABASE_AUTHENTICATION_GROUP | Cela indique qu’un principal réussit à se connecter à la base de données. |
| FAILED_DATABASE_AUTHENTICATION_GROUP | Cela indique qu’un principal n’a pas pu se connecter à la base de données. |
Pour activer l’audit pour toutes les bases de données sur un serveur Azure SQL, sélectionnez Audit dans la section Sécurité du panneau principal de votre serveur.
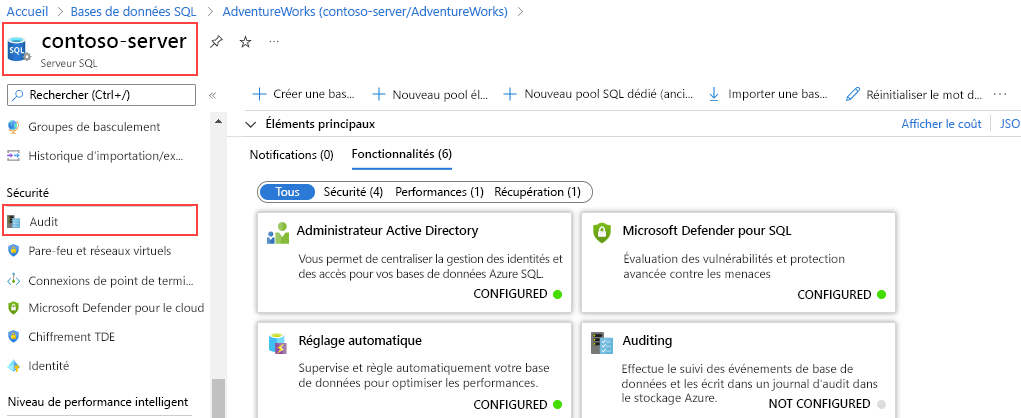
La page Audit vous permet de définir la destination du journal d’audit et de choisir d’effectuer le suivi des opérations de l’ingénieur du support Microsoft sur la même destination de journal que l’audit Azure SQL ou d’en sélectionner une autre.
Vous pouvez passer en revue les journaux d’audit des opérations de Support Microsoft dans votre espace de travail Log Analytics en exécutant la requête suivante :
AzureDiagnostics
| where Category == "DevOpsOperationsAudit"
Important
les services d’audit de Azure SQL Database et de Azure SQL Managed Instance ont été affinés pour optimiser la disponibilité et le niveau de performances. Toutefois, il convient de noter que dans des conditions d’activité exceptionnellement élevée ou en cas de congestion importante du réseau, certains événements audités peuvent ne pas être consignés.
Auditer les étiquettes sensibles
En cas de combinaison avec la classification des données, vous pouvez également surveiller l’accès aux données sensibles. L’audit Azure SQL a été amélioré pour inclure un nouveau champ nommé data_sensitivity_information dans le journal d’audit.
En journalisant les étiquettes de confidentialité des données retournées par une requête, ce champ offre un moyen plus simple de suivre l’accès aux colonnes classifiées.

L’audit se compose du suivi et de l’enregistrement des événements qui se produisent dans le moteur de base de données. L’audit Azure SQL simplifie les étapes de configuration requises pour l’activer, ce qui facilite le suivi des activités de base de données pour SQL Database et SQL Managed Instance.
Masquage dynamique des données
Dynamic Data Masking fonctionne en masquant les données afin de limiter leur exposition. Cela permet aux utilisateurs qui n’ont pas besoin d’accéder à des informations sensibles de voir la colonne, mais pas les données réelles. Notez que Dynamic Data Masking fonctionne sur la couche de présentation et que les données non masquées sont toujours visibles pour les utilisateurs disposant d’un niveau d’autorisation élevé.
Dynamic Data Masking offre l’avantage de nécessiter une modification minimale de votre application ou base de données. Vous pouvez le configurer via le Portail Azure ou à l’aide de T-SQL.
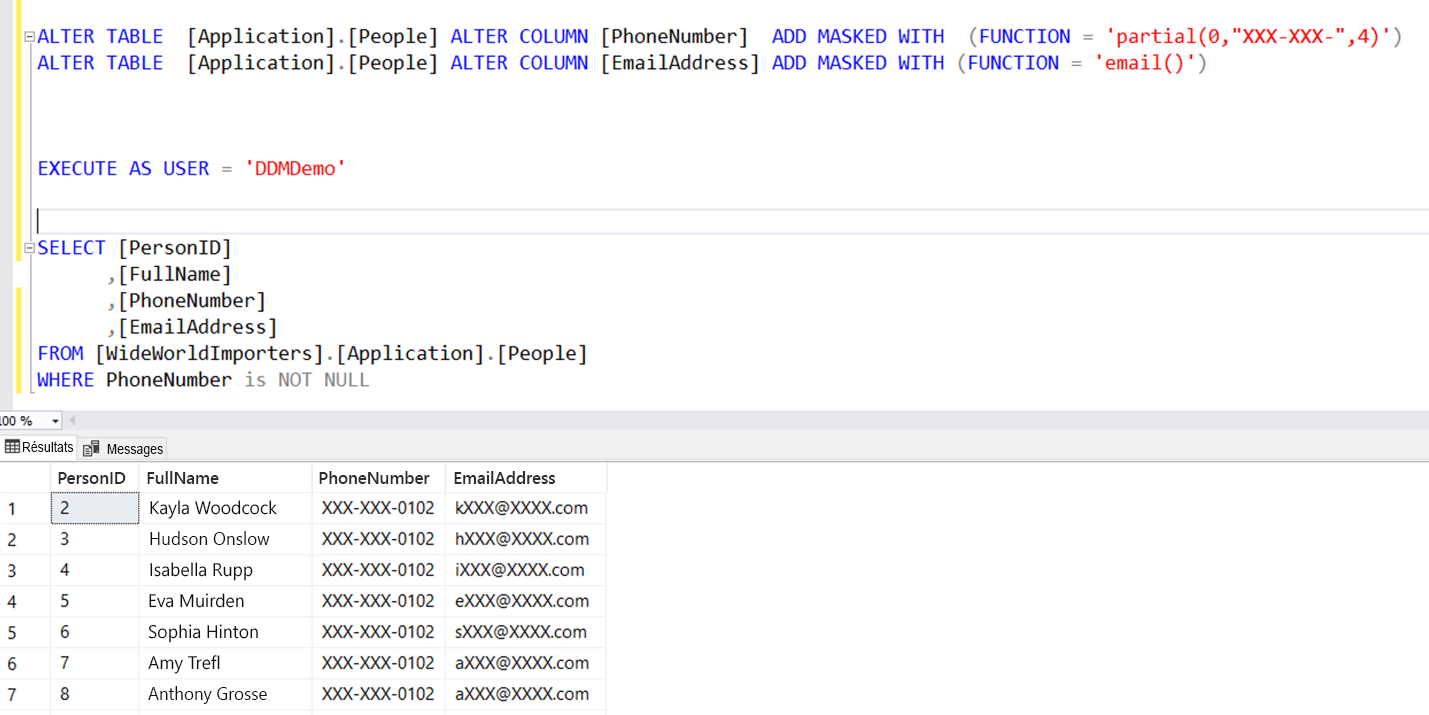
Dans l’exemple ci-dessus, les colonnes PhoneNumber et EmailAddress ne sont pas visibles pour l’utilisateur DDMDemo qui dispose uniquement d’une autorisation SELECT sur la table. L’utilisateur est autorisé à voir seulement les quatre derniers chiffres du numéro de téléphone. Celui-ci est masqué à l’aide d’une fonction partielle qui remplace tous les chiffres à l’exception des quatre derniers dans la colonne. Ce masquage est considéré comme une fonction personnalisée. En complément de T-SQL, si vous utilisez Azure SQL Database, vous pouvez créer des règles de masquage dynamique dans le Portail Azure.
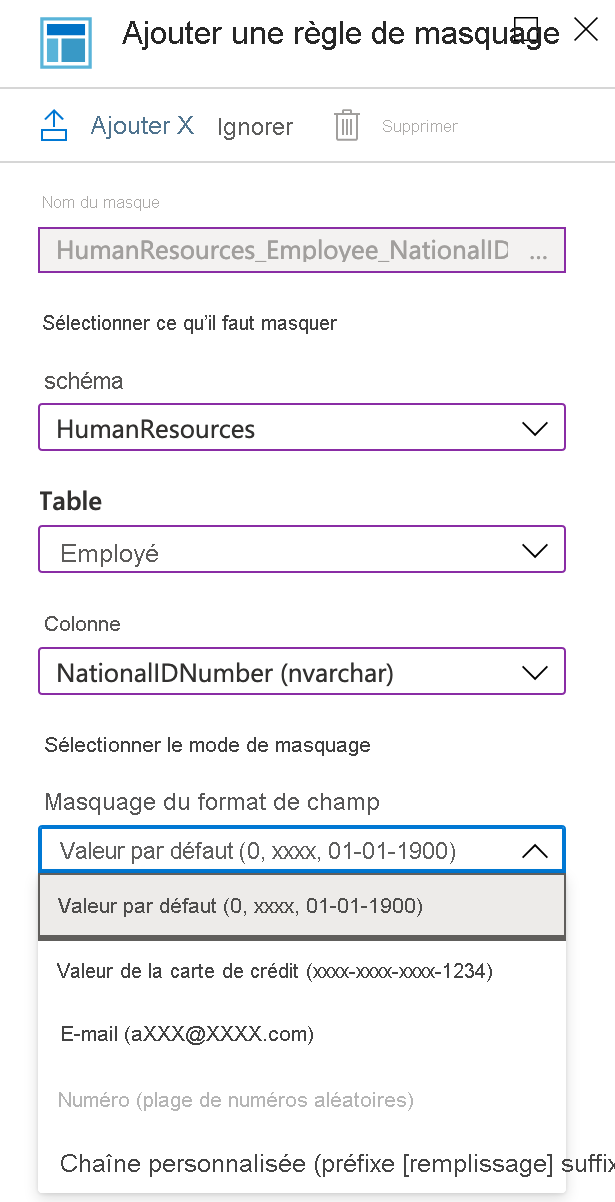
Pour ajouter une règle de masquage, vous pouvez accéder à votre base de données dans le Portail Microsoft Azure et sélectionner Dynamic Data Masking dans la section Sécurité du volet principal de votre base de données.
Le masquage de données dynamiques prend en charge les modèles de masquage suivants :
| Fonction de masquage | Définition | Exemple T-SQL |
|---|---|---|
| Par défaut | Masque entièrement les données dans la colonne sans exposer une partie des valeurs à l’utilisateur. L’utilisateur voit XXXX pour les valeurs de caîne, 0 pour les nombres et 01.01.1900 pour les valeurs de date. | ALTER TABLE [Customer] ALTER COLUMN Address ADD MASKED WITH (FUNCTION = 'default()') |
| Carte de crédit | Masque tous les caractères à l’exception des quatre derniers, ce qui permet aux utilisateurs d’afficher les quatre derniers chiffres. Ce type de masque peut être utile pour des agents de service client qui doivent afficher les quatre derniers chiffres d’un numéro de carte de crédit, mais qui n’ont pas besoin de voir le nombre entier. Les données sont affichées au format habituel d’un numéro de carte de crédit XXXX-XXXX-XXXX-1234. | ALTER TABLE [Customer] ALTER COLUMN Address ADD MASKED WITH (FUNCTION = 'partial(0,"XXXX-XXXX-XXXX-",4)') |
| Seule la première lettre du domaine et le suffixe de fin ne sont pas masqués ; par exemple, « aXXX@XXXXXXX.com » | ALTER TABLE [Customer] ALTER COLUMN Email ADD MASKED WITH (FUNCTION = 'email()') |
|
| Nombre | Ce format de masquage doit être utilisé sur les colonnes numériques. Il affiche un nombre aléatoire comme valeur masquée au lieu de la valeur réelle. Avec chaque requête, un nombre différent est affiché. | ALTER TABLE [Customer] ALTER COLUMN [Month] ADD MASKED WITH (FUNCTION = 'random(1, 12)') |
| Chaîne personnalisée | Cette option permet de masquer le texte avec n’importe quelle valeur et d’afficher un nombre personnalisé de caractères à chaque extrémité de la valeur masquée. Si la longueur de la valeur masquée est inférieure ou égale au nombre de caractères spécifiés dans le masque partiel, seuls les caractères masqués apparaissent. | ALTER TABLE [Customer] ALTER COLUMN [PhoneNumber] ADD MASKED WITH (FUNCTION = 'partial(1,"XXXXXXX",0)') |
Pour permettre aux utilisateurs de récupérer des données non masquées à partir des colonnes où le masquage est défini, vous devez accorder explicitement l’autorisation UNMASK.
Remarque
Il est possible d’identifier les données masquées à l’aide de l’inférence en fonction des résultats. Si vous utilisez le masquage des données, vous devez également limiter la capacité de l’utilisateur à exécuter des requêtes ad hoc.
Pour cette raison, nous vous recommandons de combiner le masquage dynamique avec d’autres fonctionnalités de sécurité telles que l’audit, le chiffrement des données et la sécurité au niveau des lignes pour améliorer la protection des données sensibles.
Cas d’usage
Le masquage des données est une fonctionnalité simple et légère qui est idéale pour de nombreux de scénarios tels que :
Masquer les données des utilisateurs de l’application qui n’ont pas d’accès direct à la base de données.
Restreindre les informations privées à un groupe d’utilisateurs.
Fournir des données masquées aux fournisseurs externes, où vous devez protéger les informations sensibles tout en conservant les relations entre les éléments des données.
Permettre à un utilisateur qui n’a pas d’autorisation
UNMASK.d’exporter une copie de votre base de données de production vers un environnement inférieur à des fins de développement. Les données seront alors exportées dans un format masqué.
Importer et exporter des données
La copie de données d’une colonne masquée dans une autre table à l’aide de SELECT INTO ou INSERT INTO a pour effet de masquer les données dans la table cible.
Lorsqu’un utilisateur sans privilège UNMASK exécute les fonctionnalités Importer et exporter sur SQL Server, le fichier de données exporté contient des données masquées et la base de données importée contient des données masquées inactives.