Introduction
En matière de machine learning, les modèles sont formés pour prédire des étiquettes inconnues pour les nouvelles données en fonction des corrélations entre les étiquettes connues et les fonctionnalités figurant dans les données de formation. Selon l’algorithme utilisé, vous devrez peut-être spécifier des hyperparamètres pour configurer la façon dont le modèle est formé.
Par exemple, l’algorithme de régression logistique utilise un hyperparamètre de taux de régularisation pour contrecarrer le surajustement. et les techniques de deep learning pour les réseaux neuronaux convolutifs (CNN) utilisent des hyperparamètres tels que le taux de formation pour contrôler la façon dont les pondérations sont ajustées lors de la formation et la taille de lot pour déterminer le nombre d’éléments de données inclus dans chaque lot de formation.
Notes
Le machine learning est un champ universitaire avec sa propre terminologie particulière. Les scientifiques des données font référence aux valeurs déterminées à partir des caractéristiques d’entraînement en tant que paramètres. Un autre terme est donc nécessaire pour les valeurs qui permettent de configurer le comportement d’entraînement, mais qui ne sont pas dérivées des données d’entraînement. Il s’agit du terme hyperparamètre.
Le choix de valeurs d’hyperparamètre peut affecter de manière significative le modèle résultant, ce qui rend important la sélection des meilleures valeurs possibles pour vos données et objectifs de performance prédictifs spécifiques.
Optimisation des hyperparamètres
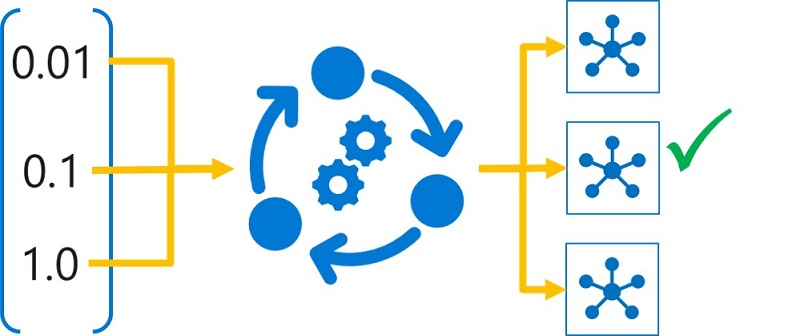
Le réglage d’hyperparamètres s’effectue en entraînant les différents modèles, en utilisant les mêmes données d’algorithme et d’entraînement, mais avec des valeurs d’hyperparamètre différentes. Le modèle résultant de chaque exécution de formation est ensuite évalué pour déterminer les mesures de performance pour lesquelles vous souhaitez optimiser (par exemple, la précision), et le modèle le plus performant est sélectionné.
Dans Azure Machine Learning, vous pouvez régler les hyperparamètres en exécutant un script en tant que travail de balayage. Un travail de balayage exécute un essai pour chaque combinaison d’hyperparamètres à tester. Chaque essai utilise un script d’apprentissage avec des valeurs d’hyperparamètres paramétrées pour l’apprentissage d’un modèle et consigne les métriques de performance cible obtenue par le modèle entraîné.
Objectifs d’apprentissage
Dans ce module, vous allez découvrir comment :
- Définir un espace de recherche des hyperparamètres.
- Configurer l’échantillonnage des hyperparamètres.
- Sélectionner une stratégie d’arrêt anticipé.
- Exécuter un travail de balayage.