Outils d’exploration de données dans Azure Databricks
Après avoir ingéré des données à partir de vos sources, vous pouvez utiliser la plateforme Azure Databricks pour explorer et analyser vos données de manière collaborative.
Examinons les outils que vous utilisez pour travailler avec des données dans Azure Databricks.
Collaborer et exécuter du code avec des notebooks
Vous pouvez utiliser des notebooks dans Azure Databricks pour écrire du code Python, SQL, Scala ou R afin d’explorer et de visualiser des données. Les notebooks prennent en charge l’exploration interactive des données et peuvent être partagés entre les membres de l’équipe. Ils prennent également en charge les fonctionnalités de profilage des données permettant aux scientifiques des données de comprendre la forme et le contenu des données.

Vous pouvez utiliser les visualisations intégrées pour comprendre rapidement les distributions, les tendances et les modèles des données. En plus des fonctionnalités intégrées, Azure Databricks vous permet d’intégrer des bibliothèques open source couramment utilisées comme Matplotlib, Seaborn ou D3.js pour des visualisations plus complexes.
Utiliser des DataFrames Spark
Lorsque vous utilisez des données dans des notebooks, vous utilisez des DataFrames Spark basés sur Apache Spark. Les DataFrames vous permettent de manipuler efficacement des jeux de données volumineux.
Pour créer un DataFrame simple, vous pouvez exécuter le code suivant :
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
Les DataFrames prennent en charge les opérations telles que le filtrage, l’agrégation et la jointure, qui sont essentielles pour l’exploration des données.
Par exemple, vous pouvez filtrer un DataFrame :
filtered_df = df.filter(df["Age"] > 30)
Azure Databricks prend également en charge SQL en permettant de basculer entre les opérations DataFrame et les requêtes SQL pour interagir avec les données d’une manière plus naturelle.
Pour filtrer le DataFrame à l’aide d’une requête SQL, vous créez d’abord une vue temporaire :
df.createOrReplaceTempView("people")
sql_df = spark.sql("SELECT Name, Age FROM people WHERE Age > 30")
Conseil
Pour plus d’informations, découvrez comment charger et transformer des données à l’aide de DataFrames Apache Spark.
Explorer les données à l’aide de bibliothèques et d’API
Selon ce que vous souhaitez faire avec vos données, vous devez utiliser des bibliothèques et des API spécifiques qui vous fournissent les fonctionnalités nécessaires pour effectuer les opérations de traitement de données souhaitées.
Installer des bibliothèques open source
En tant qu’analyste données, ingénieur données ou scientifique des données, vous pouvez utiliser vos bibliothèques open source préférées pour explorer et traiter les données. Azure Databricks vous permet d’installer des bibliothèques Python telles que Pandas, NumPy ou Scikit-learn pour obtenir des fonctionnalités d’analyse de données supplémentaires.
Utiliser MLlib pour les charges de travail Machine Learning
Vous pouvez former des modèles Machine Learning pour vous aider à explorer et à traiter vos données. Avec MLlib de Spark, vous utilisez de manière optimale les clusters de calcul distribués attachés à vos notebooks. Avec la bibliothèque MLlib, vous pouvez appliquer des techniques de Machine Learning telles que le clustering, la régression et la classification, ce qui vous aide à découvrir des modèles cachés et complexes dans vos données.
Visualiser des données avec des outils de visualisation externes
Outre les options de graphique intégrées, Azure Databricks s’intègre à des outils de visualisation externes tels que Tableau ou Power BI via des API de visualisation de données pour des fonctionnalités de tableau de bord améliorées.
Conseil
En savoir plus sur l’utilisation des bibliothèques.
Gérer vos clusters de calcul
Lorsque vous souhaitez exécuter du code dans des notebooks, vous devez attacher un notebook à un cluster de calcul pour accéder à la puissance de traitement nécessaire.
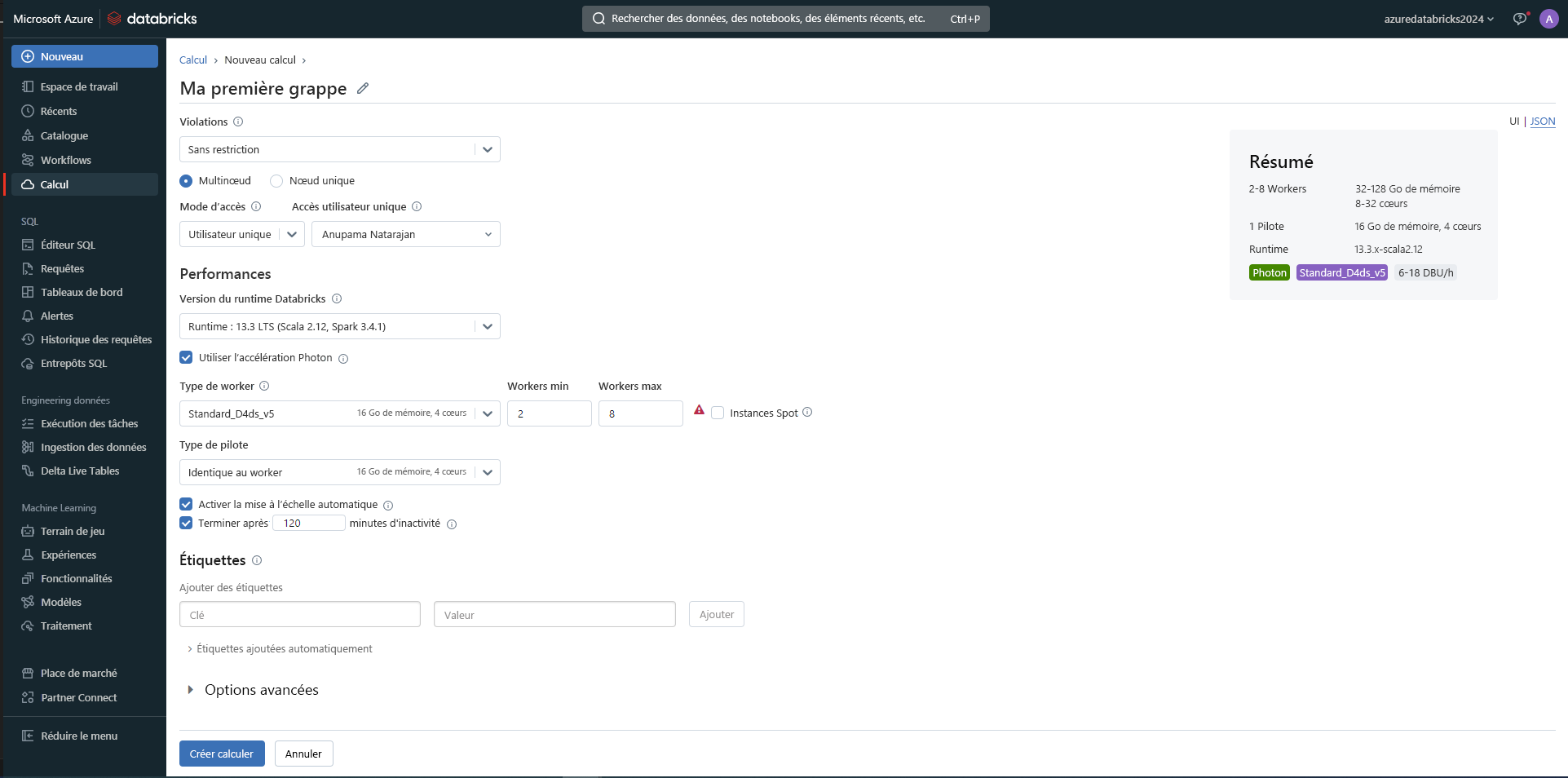
Il existe deux avantages à gérer vos clusters de calcul dans Azure Databricks :
- Mise à l’échelle automatique des clusters : Vous pouvez mettre automatiquement à l’échelle vos ressources de calcul en fonction de la charge de travail, ce qui vous permet d’optimiser les coûts et les performances pendant la phase d’exploration.
- Clusters managés : Vous pouvez simplifier la gestion de votre cluster, car Azure Databricks gère la configuration et la maintenance.
Conseil
En savoir plus sur la gestion du calcul
Ces outils permettent font d’Azure Databricks une plateforme flexible pour l’exploration des données, en gérant tout, du simple nettoyage des données aux projets de Machine Learning avancés.