Répliquer des données vers un cluster secondaire
Kafka est souvent déployé dans plusieurs environnements pour la récupération d’urgence, la haute disponibilité et les scénarios hybrides local à Cloud. Ces scénarios requièrent la réplication des données d’une instance Kafka à l’autre à l’aide de la fonctionnalité de mise en miroir d’Apache Kafka. La mise en miroir peut être exécutée sous la forme d’un processus continu ou être utilisée par intermittence comme une méthode de migration des données d’un cluster à l’autre.
La mise en miroir ne doit pas être considérée comme un moyen de bénéficier d’une tolérance de pannes. Le décalage aux éléments d’un sujet diffère entre le cluster principal et le cluster secondaire : les clients ne peuvent donc pas utiliser indifféremment les deux.
Comment la mise en miroir fonctionne-t-elle ?
La mise en miroir se fait à l’aide de l’outil MirrorMaker (qui fait partie d’Apache Kafka). Cet outil permet d’utiliser les enregistrements de rubriques du cluster principal et de créer une copie locale sur le cluster secondaire. MirrorMaker utilise un (ou plusieurs) consommateurs qui lisent le cluster principal, ainsi qu’un producteur qui écrit dans le cluster local (secondaire).
Le programme de mise en miroir le plus utile en cas de récupération d'urgence utilise des clusters Kafka dans différentes régions Azure. Pour ce faire, les réseaux virtuels abritant les clusters sont appairés.
Le diagramme suivant illustre le processus de mise en miroir et le flux de communication entre les clusters :
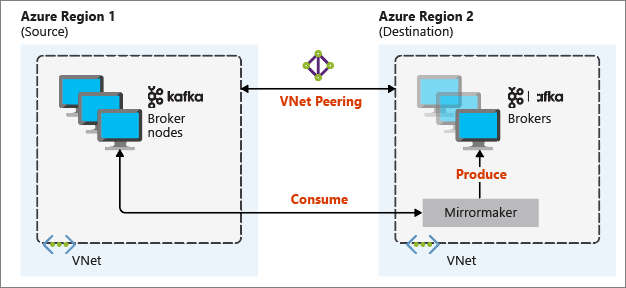
Le cluster principal et le cluster secondaire peuvent comporter un nombre différent de nœuds et de partitions, et les décalages dans les sujets ne sont pas forcément les mêmes. La mise en miroir conserve la valeur clé utilisée pour le partitionnement afin de préserver l’ordre d’enregistrement en fonction de la clé.
Mise en miroir au-delà des limites réseau
Si vous avez besoin d’effectuer une mise en miroir entre des clusters Kafka sur des réseaux différents, vous devez tenir compte des points suivants :
- Passerelles : les réseaux doivent être capables de communiquer au niveau TCP/IP.
-
Adressage du serveur : Vous pouvez choisir d'adresser vos nœuds de cluster à l’aide de leurs adresses IP ou noms de domaine complets.
- Adresses IP : Si vous configurez vos clusters Kafka pour la publication d'adresses IP, vous pouvez configurer la mise en miroir à l'aide des adresses IP des nœuds Broker et Zookeeper.
- Noms de domaine : Si vous ne configurez pas vos clusters Kafka pour la publication d’adresses IP, vos clusters doivent pouvoir se connecter entre eux à l’aide de noms de domaine complets (FQDN). Cela implique la configuration d’un serveur DNS (Domain Name System) dans chaque réseau pour l’acheminement des demandes vers les autres réseaux. Lorsque vous créez un réseau virtuel Azure, au lieu d’utiliser le DNS automatique fourni avec le réseau, vous devez spécifier un serveur DNS personnalisé et l’adresse IP du serveur. Après avoir créé le réseau virtuel, vous devez ensuite créer une machine virtuelle Azure qui utilise cette adresse IP, puis y installer et configurer le logiciel DNS.
Avertissement
Créez et configurez le serveur DNS personnalisé avant d’installer HDInsight sur le réseau virtuel. Aucune configuration supplémentaire n’est requise pour HDInsight dans le cadre de l’utilisation du serveur DNS configuré pour le réseau virtuel.