Exercice - Stream de données Kafka vers un notebook Jupyter et fenêtrage des données
Le cluster Kafka écrit à présent des données dans son journal, qui peuvent être traitées via Spark Structured streaming.
Un bloc-notes Spark est inclus dans l’exemple que vous avez cloné. vous devez donc charger ce Notebook sur le cluster Spark pour l’utiliser.
Charger le bloc-notes Python sur le cluster Spark
Dans le portail Azure, cliquez sur Accueil > Clusters HDInsight, puis sélectionnez le cluster Spark que vous venez de créer (pas le cluster Kafka).
Dans le volet tableaux de bord du cluster, cliquez sur bloc-notes Jupyter.

Lorsque vous êtes invité à entrer vos informations d’identification, entrez un nom d’utilisateur administrateur, puis entrez le mot de passe que vous avez créé lors de la création des clusters. Le site Web Jupyter s’affiche.
Cliquez sur PySpark, puis dans la page PySpark, cliquez sur Télécharger.
Accédez à l’emplacement où vous avez téléchargé l’exemple à partir de GitHub, sélectionnez le fichier RealTimeStocks. ipynb, puis cliquez sur Ouvrir, sur Télécharger, puis sur Actualiser dans le navigateur Internet.
Une fois le bloc-notes chargé dans le dossier PySpark, cliquez sur RealTimeStocks. ipynb pour ouvrir le bloc-notes dans le navigateur.
Exécutez la première cellule du bloc-notes en plaçant votre curseur dans la cellule, puis en cliquant sur Maj + Entrée pour exécuter la cellule.
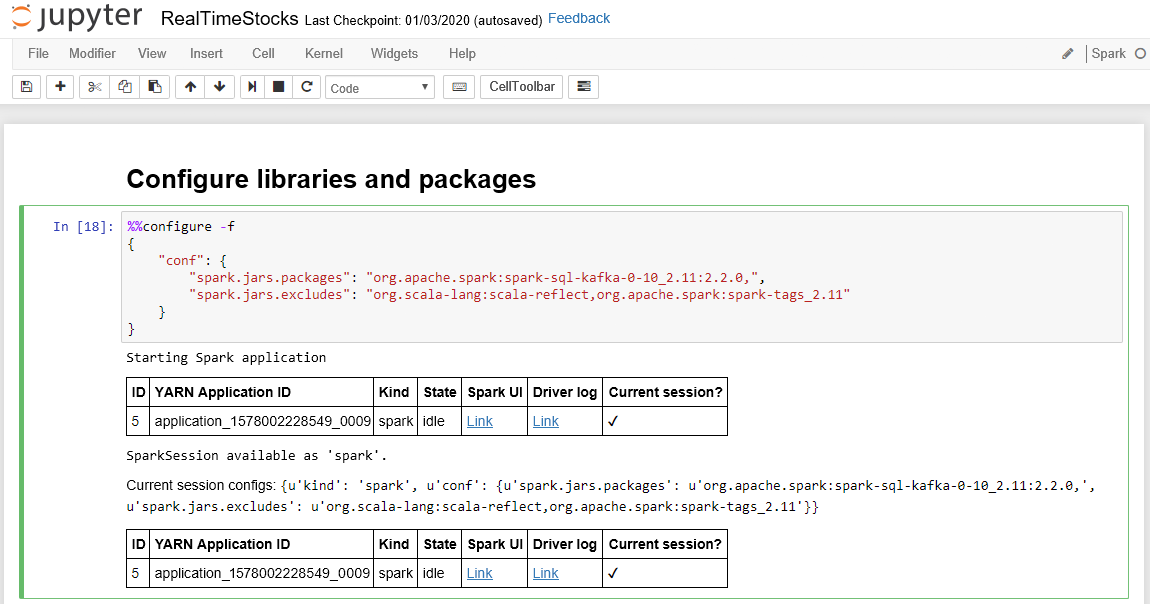
La cellule Configurer des bibliothèques et des packages se termine avec succès lorsqu’elle affiche le message d’application Spark de départ et des informations supplémentaires, comme indiqué dans la légende d’écran suivante.
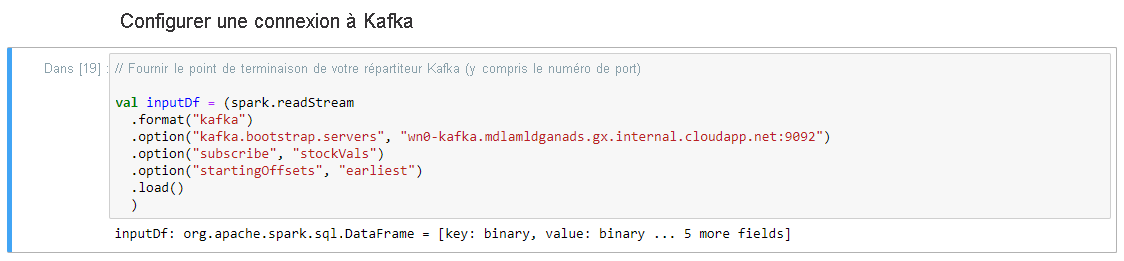
Dans la cellule Configurer la connexion à Kafka , sur la ligne .option ("Kafka. bootstrap. Servers", ""), entrez le répartiteur Kafka entre le deuxième ensemble de guillemets. Par exemple, .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), puis cliquez sur Maj+Entrée pour exécuter la cellule.
La connexion d’installation à la cellule Kafka se termine correctement lorsqu’elle affiche le message inputDf: org.apache.spark.sql.DataFrame = [clé : binaire, valeur : binaire... 5 champs supplémentaires]. Spark utilise l’API readStream pour lire les données.
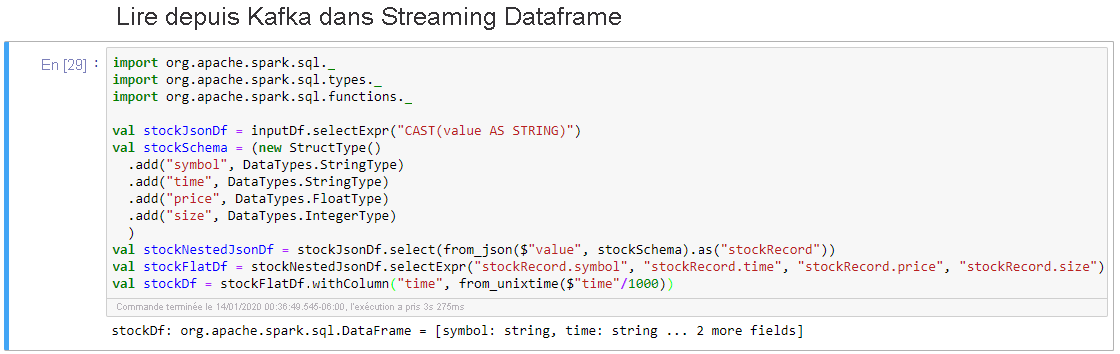
Sélectionnez la cellule Lire depuis Kafka dans Streaming Dataframe, puis cliquez sur Shift + Entrée pour exécuter la cellule.
La cellule s’exécute correctement quand elle affiche le message suivant : stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 autres champs]
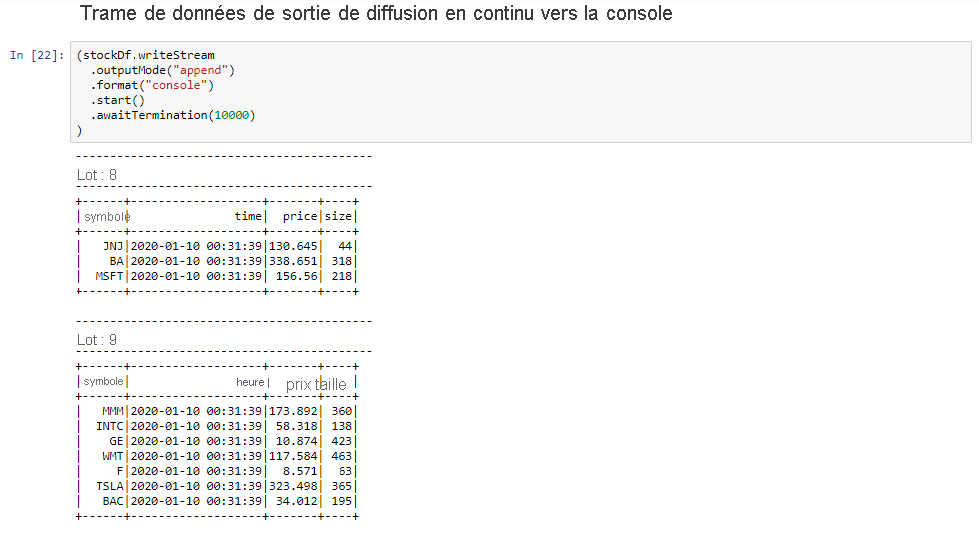
Sélectionnez la celluleSortie d’un tableau de diffusion en continu vers une console, puis cliquez sur Shift + Entrée pour exécuter la cellule.
La cellule se termine avec succès lorsqu’elle affiche des informations semblables à ce qui suit. La sortie affiche la valeur de chaque cellule telle qu’elle a été transmise dans le micro-lot, et il y a un lot par seconde.
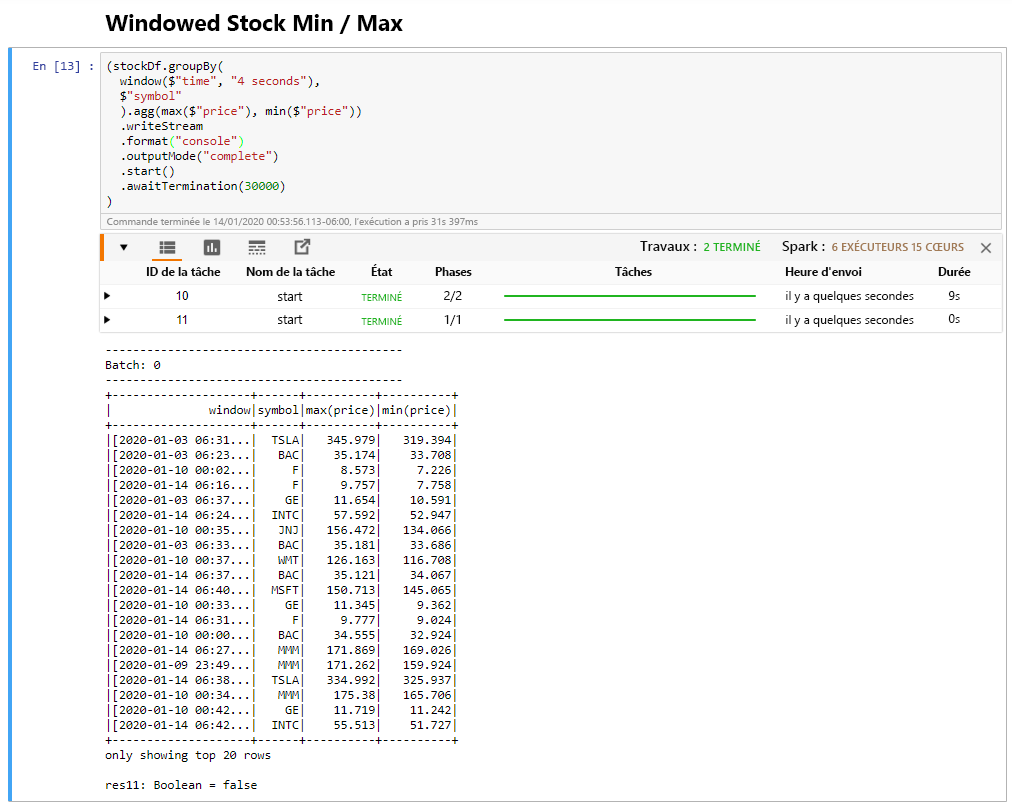
Sélectionnez la cellule Windowed Stock Min / Max, puis cliquez sur Shift + Enter pour exécuter la cellule.
La cellule se termine correctement lorsqu’elle fournit le prix max. et min. pour chaque action dans la fenêtre 4 secondes, qui est définie dans la cellule. Comme indiqué dans une unité précédente, le fait de fournir des informations sur des fenêtres de temps spécifiques est l’un des avantages que vous procure Spark Structured Streaming.
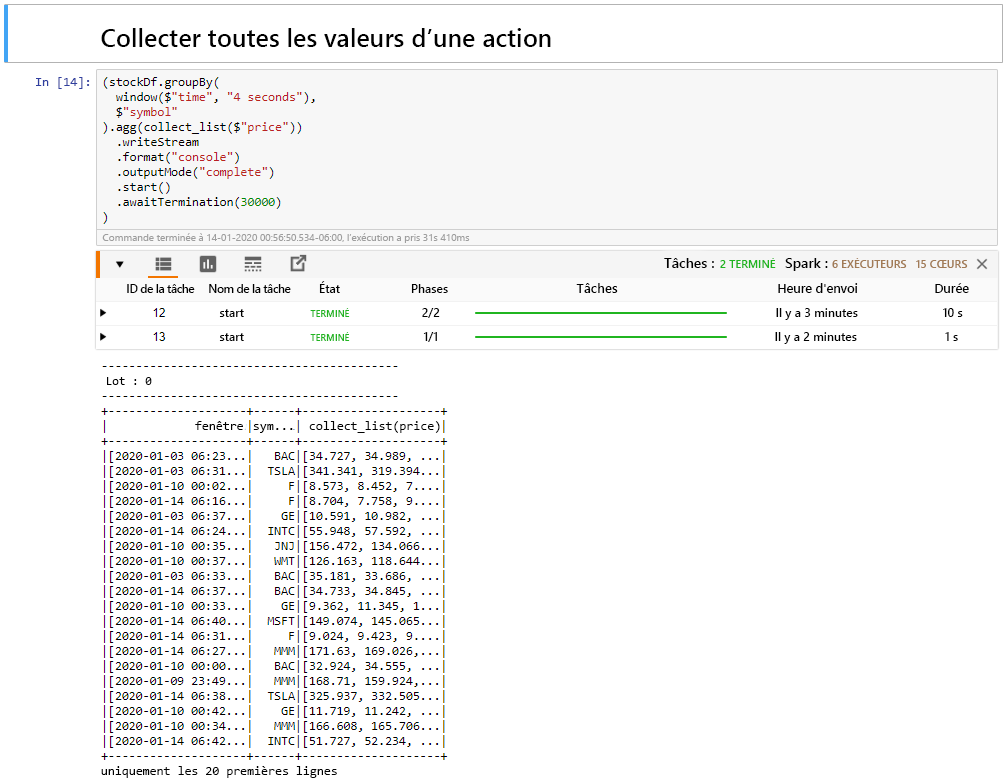
Sélectionnez la cellule collecter toutes les valeurs des actions dans une fenêtre, puis cliquez sur Shift + Entrée pour exécuter la cellule.
La cellule se termine avec succès lorsqu’elle fournit un tableau des valeurs des actions dans la table. Le mode Sortie est terminé, de sorte que toutes les données sont affichées.
Dans cette unité, vous avez chargé un bloc-notes Jupyter sur un cluster Spark, vous l’avez connecté à votre cluster Kafka, vous avez créé les données de streaming créées par le fichier du producteur Python dans le bloc-notes Spark, défini une fenêtre pour les données de diffusion en continu et affiché les cours élevés et faibles dans cette fenêtre, et affiché toutes les valeurs du stock dans la table. Félicitations, vous avez correctement effectué la diffusion en continu structurée à l’aide de Spark et Kafka !