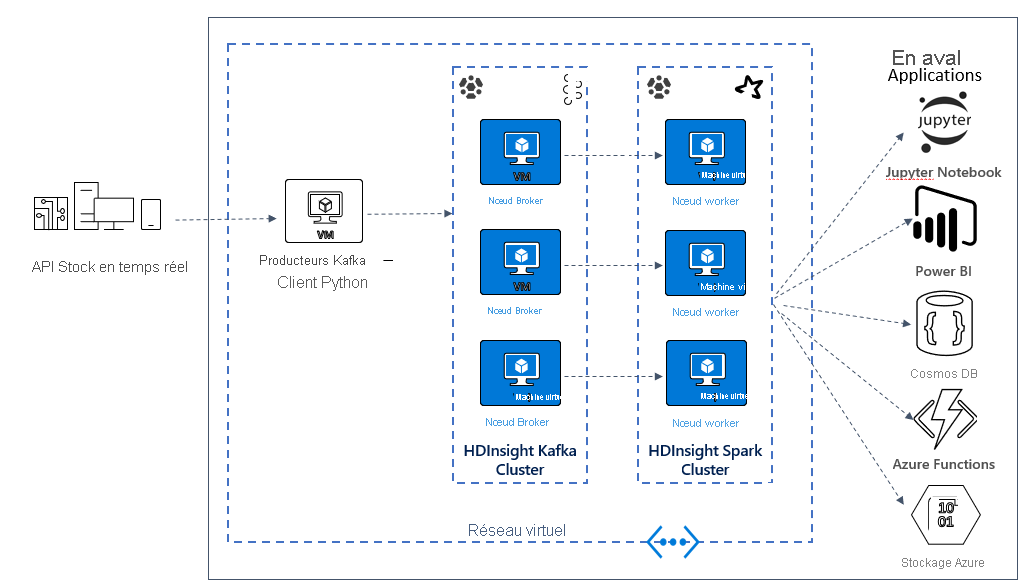
Créer une architecture Kafka et Spark
Pour utiliser Kafka et Spark ensemble dans Azure HDInsight, vous devez les placer dans le même réseau virtuel ou associer les réseaux virtuels afin que les clusters fonctionnent avec la résolution de noms DNS.
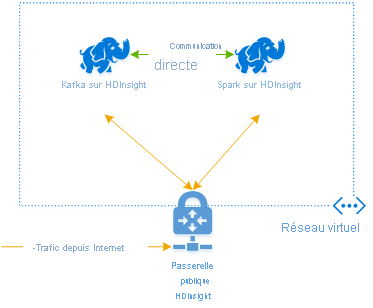
Pour créer des clusters dans le même réseau virtuel, la procédure est la suivante :
- Créer un groupe de ressources
- Ajouter un réseau virtuel au groupe de ressources
- Ajoutez un cluster Kafka et un cluster Spark au même réseau virtuel ou bien le réseau virtuel dans lequel ces services opèrent avec la résolution de noms DNS.
La méthode recommandée pour connecter le cluster HDInsight Kafka et Spark est le connecteur Spark-Kafka natif, qui permet au cluster Spark d’accéder à des partitions de données individuelles au sein du cluster Kafka, ce qui augmente le parallélisme dont vous disposez dans votre travail de traitement en temps réel et fournit un débit très élevé.
Lorsque les deux clusters se trouvent dans le même réseau virtuel, vous pouvez également utiliser des noms de domaine complets Kafka Broker dans le code Spark streaming et vous pouvez créer des règles NSG sur le réseau virtuel pour la sécurité de l’entreprise.
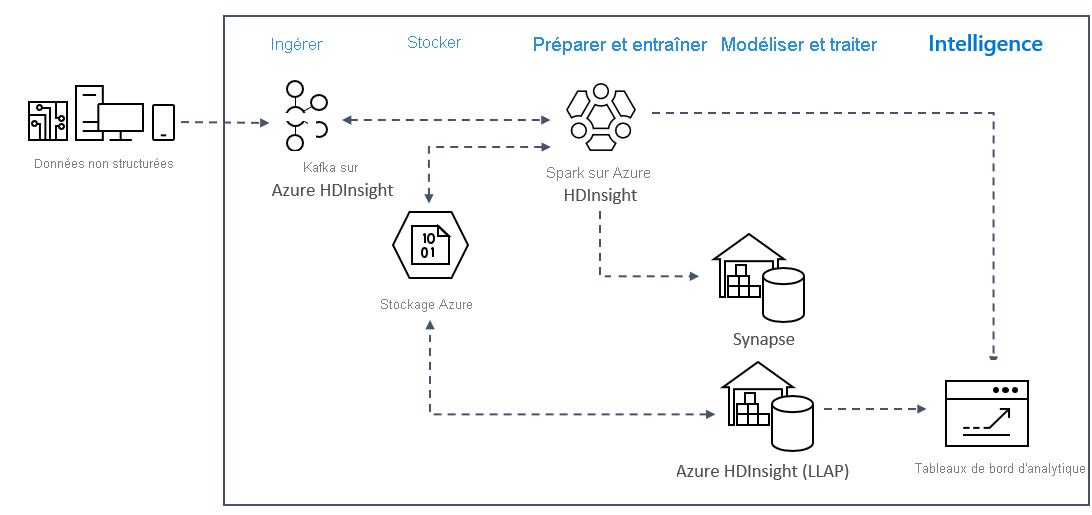
Architecture de solution
Les modèles d’analyse de diffusion en continu en temps réel sur Azure utilisent généralement l’architecture de solution suivante.
- Réception: les données structurées ou non structurées sont ingérées dans un cluster Kafka sur Azure HDInsight.
- Préparer et former: les données sont préparées et formées avec Spark sur HDInsight.
- Modèle et service : les données sont placées dans un entrepôt de données, tel qu’Azure Synapse ou HDInsight interactive Query.
- Intelligence: les données sont fournies au tableau de bord d’analyse, par exemple Power bi ou Tableau.
- Stockage : les données sont placées dans une solution de stockage à froid, telle qu’Azure Storage, et sont fournies plus tard.
Architecture du test du scénario
Dans l’unité suivante, vous commencerez à créer l’architecture de la solution pour l’exemple d’application. Cet exemple utilise un fichier de modèle Azure Resource Manager pour créer le groupe de ressources, le réseau virtuel, le cluster Spark et le cluster Kafka.
Une fois les clusters déployés, vous allez utiliser SSH dans l’un des courtiers Kafka et copier le fichier du producteur python dans le nœud principal. Ce fichier de producteur fournit des cours de bourse artificiels toutes les 10 secondes, il écrit également le numéro de partition et le décalage du message sur la console.
Une fois que le producteur est en cours d’exécution, vous pouvez télécharger le bloc-notes Jupyter sur le cluster Spark. Dans le bloc-notes, vous allez connecter les clusters Spark et Kafka et exécuter des exemples de requêtes sur les données, notamment la recherche des valeurs haute et basse pour une action dans une fenêtre d’événements.