Décrire Spark Structured Streaming
Spark Structured Streaming est une plateforme populaire pour le traitement en mémoire. Elle dispose d’un paradigme unifié pour le traitement par lots et la diffusion en continu. Tout ce que vous allez apprendre et utiliser pour batch, vous pouvez l’utiliser pour la diffusion en continu. Il est donc facile de passer du traitement par lot de vos données à la diffusion en continu de vos données. Spark Streaming est simplement un moteur qui s’exécute sur Apache Spark.

Structured Streaming crée une longue requête au cours de laquelle vous appliquez des opérations sur les données d’entrée, par exemple des opérations de sélection, de projection, d’agrégation, de fenêtrage et de jointure de la trame de données de diffusion en continu avec les trames de données de référence. Les résultats sont ensuite transférés au stockage de fichiers (objets Blob du stockage Azure ou instance de Data Lake Storage), ou à n’importe quel magasin de données par le biais d’un code personnalisé (par exemple, SQL Database ou Power BI). Structured Streaming transmet également des données de sortie à la console à des fins de débogage en local, ainsi qu’à une table en mémoire afin que vous puissiez afficher les données générées pour le débogage dans HDInsight.
Flux de données sous forme de tables
Spark Structured Streaming représente un flux de données sous la forme d’une table non limitée en profondeur, autrement dit, la table ne cesse de croître à mesure que de nouvelles données arrivent. Cette table d’entrée est traitée en continu par une longue requête, et les résultats sont écrits dans une table de sortie :

Dans Structured Streaming, les données arrivent au système et sont ingérées immédiatement dans une table d’entrée. Vous écrivez des requêtes (à l’aide des API DataFrame et DataSet)qui effectuent des opérations sur cette table d’entrée. La sortie de la requête génère une autre table : la table de résultats. La table de résultats contient les résultats de votre requête, à partir desquels vous récupérez des données destinées à un magasin de données externe tel qu’une base de données relationnelle. Le moment où les données de la table d’entrée sont traitées est contrôlé par l’intervalle de déclenchement. Par défaut, l’intervalle de déclencheur est défini sur zéro, ce qui signifie que Structured Streaming tente de traiter les données dès qu’elles arrivent. Concrètement, dès que Structured Streaming a fini l’exécution de la requête précédente, il démarre un autre flux de traitement sur toutes les nouvelles données reçues. Vous pouvez configurer le déclencheur pour qu’il s’exécute à un intervalle défini, afin que les données de diffusion en continu soient traitées dans des lots basés sur le temps.
Les données des tables de résultats peuvent contenir uniquement les nouvelles données reçues depuis le traitement de la requête (mode Append), ou la table peut être actualisée chaque fois qu’il existe de nouvelles données, afin que la table contienne toutes les données de sortie depuis le début de la requête de streaming (mode Complet).
Mode Append
En mode Append, seules les lignes ajoutées à la table de résultats depuis la dernière exécution de la requête sont présentes dans la table de résultats et écrites dans un stockage externe. Par exemple, la requête la plus simple copie simplement toutes les données de la table d’entrée dans la table de résultats non modifiée. Chaque fois qu’un intervalle de déclencheur est écoulé, les nouvelles données sont traitées et les lignes qui représentent des nouvelles données apparaissent dans la table de résultats.
Imaginez un scénario dans lequel vous traitez des données de cotation boursière. Supposons que le premier déclencheur ait traité un événement à 00:01 pour l'action MSFT avec une valeur de 95 dollars. Dans le premier déclencheur de la requête, seule la ligne associée à l’heure 00:01 apparaît dans la table de résultats. À l’heure 00:02, lorsqu’un autre événement arrive, la seule nouvelle ligne est la ligne associée à l’heure 00:02 et, par conséquent, la table de résultats contiendra uniquement cette ligne.
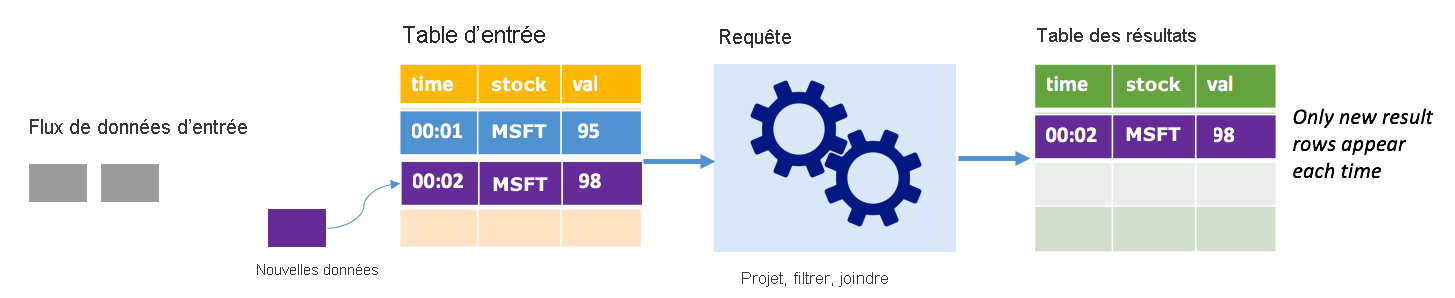
Lorsque vous utilisez le mode Append, votre requête applique des projections (en sélectionnant les colonnes qui l’intéressent), un filtrage (en choisissant uniquement les lignes répondant à certaines conditions) ou une jointure (en enrichissant les données avec les données d’une table de recherche statique). Le mode Append permet de transmettre facilement les nouveaux points de données pertinents vers un stockage externe.
Mode Complet
Considérez le même scénario, cette fois en utilisant le mode Complet. En mode Complet, l’intégralité de la table de sortie est actualisée à chaque déclencheur. Autrement dit, la table inclut non seulement les données issues de l’exécution du dernier déclencheur, mais également les données de toutes les autres exécutions. Vous pouvez utiliser le mode Complet pour copier les données non modifiées de la table d’entrée vers la table de résultats. À chaque exécution déclenchée, les nouvelles lignes de résultats s’affichent en même temps que toutes les lignes précédentes. La table des résultats de sortie finit par stocker toutes les données collectées depuis le début de la requête et vous risquez de manquer de mémoire. Le mode Complet est destiné à des requêtes d’agrégation qui, d’une certaine façon, synthétisent les données entrantes. À chaque déclencheur, la table de résultats est donc mise à jour avec un nouveau résumé.
Supposons que nous avons déjà traité l’équivalent de cinq secondes de données, et qu’il nous faille maintenant traiter les données correspondant à la sixième seconde. La table d’entrée contient des événements pour l’heure 00:01 et l’heure 00:03. L’objectif de cet exemple de requête est de donner la température moyenne de l’appareil toutes les cinq secondes. L’implémentation de cette requête applique un agrégat qui accepte toutes les valeurs comprises dans chaque fenêtre de 5 secondes, calcule la moyenne du cours de l’action et produit une ligne pour le cours moyen de l’action sur cet intervalle. À la fin de la première fenêtre de 5 secondes, il existe deux tuples : (00:01, 1, 95) et (00:03, 1, 98). Ainsi, pour la fenêtre 00:00-00:05, l’agrégation produit un tuple avec la cotation boursière moyenne de 96,50 $. Dans la fenêtre de 5 secondes suivante, on obtient uniquement un point de données à l’heure 00:06, ce qui donne une température moyenne de 98 $. À l’heure 00:10, à l’aide du mode Complet, la table de résultats intègre les lignes correspondant aux deux fenêtres (00:00-00:05 et 00:05:00:10), car la requête renvoie toutes les lignes agrégées, et pas seulement les nouvelles. Par conséquent, la table des résultats continue de croître à mesure que de nouvelles fenêtres sont ajoutées.
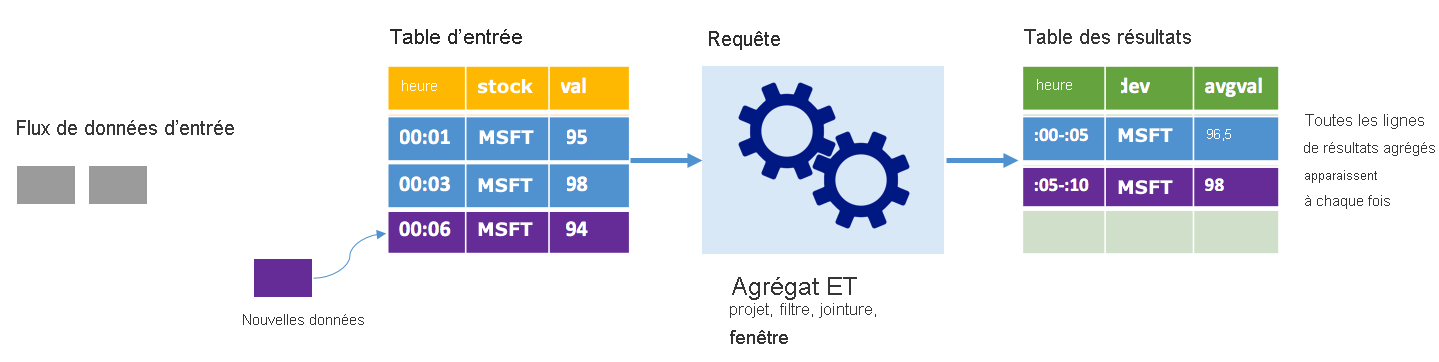
Toutes les requêtes qui utilisent le mode Complet n’entraînent pas une croissance illimitée de la table. Imaginez, en reprenant l’exemple précédent, qu'au lieu de faire la moyenne du prix de l'action par fenêtre, on a fait la moyenne par action. La table de résultats contient un nombre fixe de lignes (une par stock) avec le cours d’action moyen pour les stocks sur tous les points de données reçus à partir de cet appareil. À mesure que de nouveaux cours sont reçus, la table de résultats est mise à jour afin que les moyennes dans la table soient toujours actuelles.
Quels sont les avantages de Spark Structured Streaming ?
Dans le secteur financier, le minutage des transactions est très important. Par exemple, dans une bourse, la différence entre le moment où l’action se produit sur le marché ou le moment où vous recevez la transaction, ou encore le moment où les données sont lues. Pour les institutions financières, cela dépend de ces données critiques et de la synchronisation qui leur est associée.
Heure de l’événement, données tardives et filigrane
Spark Structured Streaming connait la différence entre l’heure d’un événement et l’heure à laquelle l’événement a été traité par le système. Chaque événement est une ligne de la table, et l’heure de l’événement est une valeur de colonne dans la ligne. Cela permet aux agrégations basées sur une fenêtre (par exemple, le nombre d’événements par minute) de constituer simplement un regroupement et une agrégation sur la colonne d’événement-heure. Chaque fenêtre de temps est un groupe et chaque ligne peut appartenir à plusieurs fenêtres/groupes. Par conséquent, ces requêtes d’agrégation basées sur une fenêtre de temps d’événement peuvent être définies de manière cohérente sur un jeu de données statique et sur un flux de données, ce qui facilite grandement la vie d’un ingénieur de données.
En outre, ce modèle gère naturellement les données qui sont arrivées plus tard que prévu, en fonction de leur temps d’événement. Spark dispose d’un contrôle total sur la mise à jour des anciens agrégats lorsqu’il y a des données tardives, ainsi que de nettoyage des anciens agrégats pour limiter la taille des données d’état intermédiaires. En outre, depuis Spark 2.1, Spark prend en charge le filigrane, ce qui vous permet de spécifier le seuil des données tardives et permet au moteur de nettoyer l’ancien état.
Flexibilité pour télécharger les données récentes ou toutes les données
Comme indiqué dans l’unité précédente, vous pouvez choisir d’utiliser le mode Append ou le mode Complet lorsque vous utilisez Spark Structured streaming, afin que votre tableau de résultats comprenne uniquement les données les plus récentes ou toutes les données.
Prend en charge le passage des micro-lots au traitement continu
En modifiant le type de déclencheur d’une requête Spark, vous pouvez passer du traitement des micro-lots au traitement continu sans apporter d’autres modifications à votre infrastructure. Voici les différents types de déclencheurs pris en charge par Spark.
- Non spécifié, il s’agit de la valeur par défaut. Si aucun déclencheur n’est défini explicitement, la requête est exécutée dans des micro-lots et sera traitée en continu.
- Intervalle fixe micro-lot. La requête est lancée à intervalles récurrents définis par l’utilisateur. Si aucune nouvelle donnée n’est reçue, aucun processus de micro-lot n’est exécuté.
- Micro-lot à usage unique. La requête exécute un seul micro-lot, puis s’arrête. Cela est utile si vous souhaitez traiter toutes les données depuis le micro-lot précédent, et vous pouvez réaliser des économies pour les tâches qui n’ont pas besoin d’être exécutées en continu.
- Continue avec un intervalle de point de contrôle fixe. La requête est exécutée dans un nouveau mode de traitement continu à faible latence qui permet une latence de bout en bout faible (~ 1 ms) avec des garanties de tolérance aux pannes au moins une fois. Cela est similaire à la valeur par défaut, qui peut obtenir des garanties « exactement une fois », mais n’atteint que les latences de près de 100 ms au mieux.
Combinaison de travaux de diffusion en continu et par lot
Outre la simplification du passage des tâches de traitement par lot à la diffusion en continu, vous pouvez également combiner des tâches batch et de diffusion en continu. Cela s’avère particulièrement utile lorsque vous souhaitez utiliser des données historiques à long terme pour prévoir les tendances futures lors du traitement des informations en temps réel. Pour les stocks, vous souhaiterez peut-être consulter le prix des actions au cours des 5 dernières années, en plus du prix actuel, pour prédire les modifications apportées autour des annonces de revenus annuels ou trimestriels.
Fenêtres de temps d’événement
Vous souhaiterez peut-être capturer des données dans Windows, par exemple un cours de bourse élevé et un cours bas dans une fenêtre d’une journée, ou une fenêtre d’une minute, quel que soit l’intervalle que vous choisissez, et Spark Structured Streaming en prend également en charge. Les fenêtres superposées sont également prises en charge.
Point de contrôle pour la récupération en cas d’échec
En cas d’échec ou d’arrêt intentionnel, vous pouvez récupérer la progression précédente et l’état d’une requête précédente et continuer là où elle s’était arrêtée. Cette opération s’effectue à l’aide de points de contrôle et de journaux d’écriture anticipée. Vous pouvez configurer une requête avec un emplacement de point de contrôle, et la requête enregistrera toutes les informations de progression (par exemple, la plage de décalages traités dans chaque déclencheur) et les agrégats en cours d’exécution à l’emplacement du point de contrôle. L’emplacement du point de contrôle doit être un chemin dans un système de fichiers compatible HDFS et peut être défini en tant qu’option dans le DataStreamWriter lors du démarrage d’une requête.