Diffuser en continu des données avec Apache Kafka
Apache Kafka a été créé par LinkedIn dans 2010, avec l’objectif de déplacer les données à une très grande échelle à très faible latence avec un niveau de tolérance de panne élevé. LinkedIn a ensuite fait don du projet à Apache Foundation dans 2012, mais LinkedIn utilise toujours Kafka dans son écosystème pour le suivi de l’activité des utilisateurs, l’échange de messages et la collecte des métriques.
Kafka est une plateforme de diffusion en continu distribuée conçue pour :
- Simplifier les pipelines de données
- Gérer de grandes quantités de données dans un modèle de diffusion en continu
- Prise en charge des systèmes de traitement par lots et en temps réel
- Mise à l’échelle horizontale
Commençons par en savoir plus sur Apache Kafka pure, puis sur Kafka sur Azure HDInsight.
Composants Kafka
Avant de comprendre comment Kafka fonctionne, jetons un coup d’œil aux rôles de certains composants clés de Kafka et à la façon dont ils se combinent pour fournir un système de messagerie hautement évolutif et tolérant aux pannes.
Service Broker
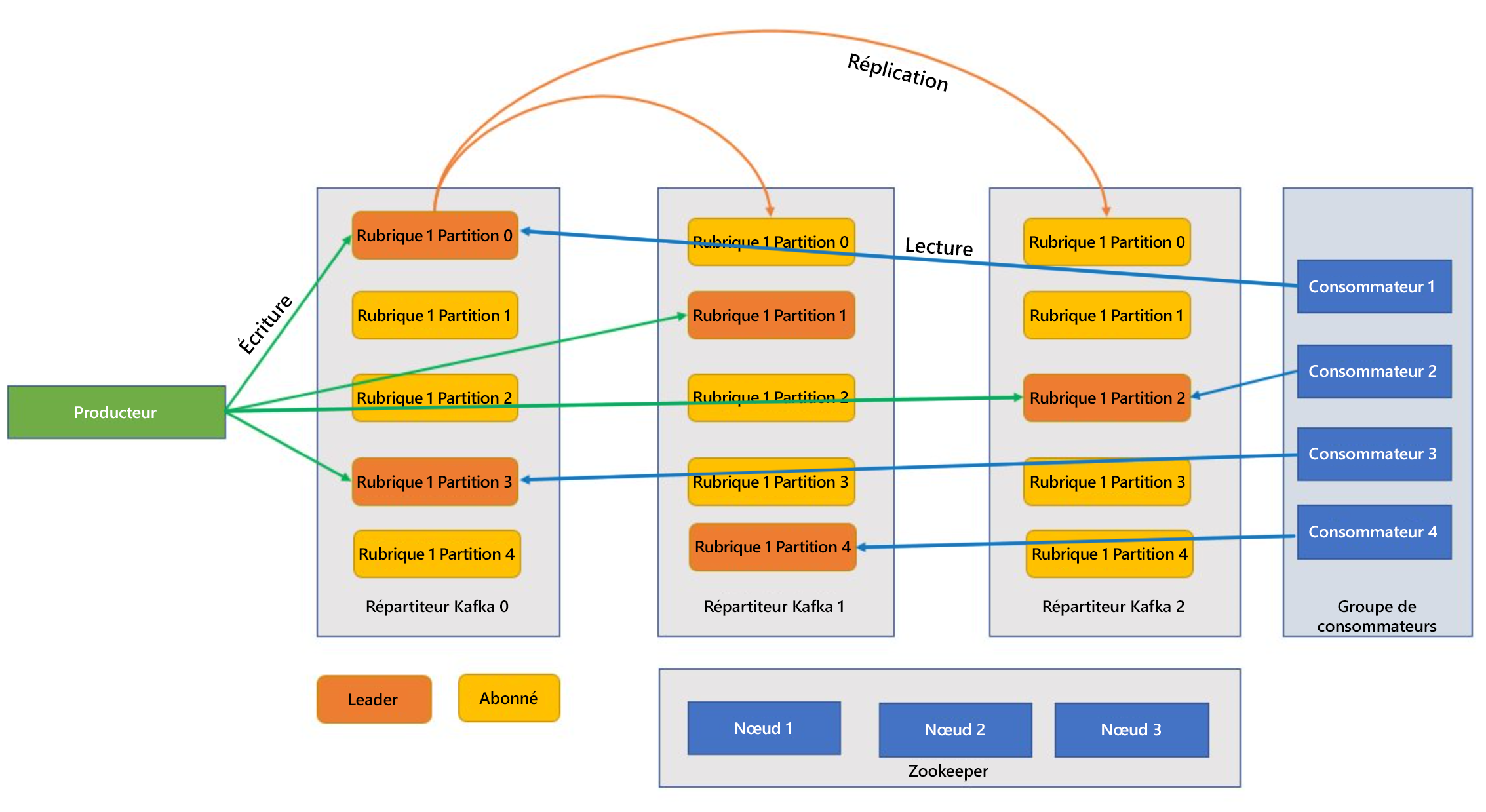
Kafka est un service en cluster et un seul cluster Kafka est également appelé répartiteur. Les courtiers reçoivent des messages de la part des producteurs et stockent ces messages sur le disque. Le répartiteur répond également aux demandes de récupération des consommateurs. Au sein d’un cluster de courtiers, un répartiteur joue le rôle de contrôleur et est responsable des opérations d’administration et de l’affectation des partitions aux courtiers.
Message
Unité de données dans un cluster Kafka. Dans la plupart des cas, les messages sont des paires clé-valeur.
Rubriques et partitions
Les rubriques et les partitions sont des catégories de messages dans Kafka. Les rubriques sont généralement divisées en plusieurs partitions à améliorer, avec un minimum de trois partitions recommandé. Les messages sont écrits dans une partition de rubrique à l’ajout uniquement. Les partitions sont répliquées sur plusieurs courtiers pour améliorer la redondance en cas de défaillance du répartiteur. Les partitions permettent de lire les rubriques en parallèle, car elles permettent le fractionnement des données entre plusieurs répartiteurs. Il existe un réplica de leader qui gère toutes les demandes de lecture-écriture, et les abonnés sont répliqués à partir du responsable. En cas de défaillance d’un responsable, l’un des réplicas devient le responsable.
Producteurs et consommateurs
Les producteurs et les consommateurs sont les clients qui produisent et consomment des messages du système Kafka. Les producteurs publient de nouveaux messages et les dirigent vers une rubrique spécifique. Les consommateurs peuvent également être conçus pour écrire dans une partition de rubrique spécifique. Les consommateurs s’abonnent à leur tour à une ou plusieurs rubriques et lisent les messages à partir de ces rubriques.
Groupe de consommateurs
Un ou plusieurs consommateurs peuvent travailler ensemble en tant que groupe et utiliser des messages en tant que groupe. Si le nombre de consommateurs est égal au nombre de partitions de rubrique, chaque consommateur utilise une partition de rubrique unique créant un parallélisme.
Rétention
Les messages dans Kafka peuvent être conservés durablement dans le cluster Kafka pendant un laps de temps prédéfini. Une fois les limites de rétention atteintes, Kafka peut expirer et supprimer ces messages.
Offset
Un décalage correspond simplement à la position d’un message dans une partition. La mise à jour de la position actuelle dans une partition au fur et à mesure du traitement des messages est appelée une validation. Après le traitement d’un message, Kafka valide l’offset du message sur une rubrique Kafka interne spéciale. Lorsqu’un producteur publie un message dans une partition, il est transféré au responsable. Le responsable ajoute le message au Journal de validation et incrémente le décalage du message. Le décalage du message est la manière dont les messages sont identifiés dans la rubrique. Le message est uniquement disponible pour le consommateur une fois que le message a été validé sur le cluster.
Zookeeper
Zookeeper est un service de coordination et dans un cluster Kafka, le Zookeeper fournit une vue synchronisée de l’état du cluster. Kafka utilise Zookeeper pour l’élection de leader parmi les partitions de Broker et de rubrique. Kafka utilise Zookeeper pour gérer la découverte de service pour les courtiers Kafka qui forment le cluster. Zookeeper envoie les modifications de la topologie à Kafka, de sorte que chaque nœud du cluster sait quand un nouveau répartiteur aparaît, quand un répartiteur disparait, qu’une rubrique a été supprimée ou qu’une rubrique a été ajoutée.
Comment tous les éléments sont-ils réunis ?
Les applications (également appelées producteurs) envoient des messages à un répartiteur Kafka et ces messages sont traités par un ou plusieurs consommateurs. Les messages d’un cluster sont classés par rubriques. Par exemple, un client peut créer une rubrique « Ventes » pour envoyer tous les messages pertinents pour les ventes, et ainsi de suite. Dans la mesure où les rubriques augmentent en taille avec des messages d’augmentation, elles sont fractionnées en partitions et ces dernières sont répliquées sur les répartiteurs Kafka à des fins de redondance. Les partitions sont classées en tant que dirigeants et abonnés. La partition principale est écrite et lue, tandis que les partitions suivantes sont simplement des réplicas, qui rattrapent l’état du responsable. Pour déterminer la partition à utiliser pour l’écriture et la lecture, les producteurs et les consommateurs doivent savoir quelles partitions sont conçues comme responsables. Les nœuds Zookeeper gèrent l’état du cluster Kafka et, parmi d’autres choses, choisissent les dirigeants de partition et fournissent ces informations aux producteurs et aux consommateurs.
Kafka fournit la garantie que les messages avec une partition sont triés dans l’ordre dans lequel ils ont été fournis. Un message spécifique peut être identifié de façon distincte à travers son décalage, qui est sa position dans une partition. Les messages lus par les consommateurs à partir des partitions et du traitement des messages valident le décalage indiquant que le message a été traité avec succès. Kafka stocke tous ses enregistrements sur le disque et assure la persistance des messages. Si le consommateur est interrompu pour une raison quelconque et si le traitement s’arrête, Kafka garde ces messages pendant une période de conservation prédéterminée. Une fois de retour en ligne, le consommateur peut redémarrer le traitement à partir du décalage validé, là où il s’était arrêté avant l’interruption.
Rubriques Kafka
Une rubrique Kafka est un flux ou une file d’attente dans laquelle les messages sont stockés et publiés. Les producteurs poussent les messages vers les rubriques et les consommateurs lisent à partir des rubriques. Chaque nœud d’un courtier Kafka peut contenir plusieurs rubriques.
Quels sont les avantages de Kafka sur Azure HDInsight ?
La version open source de Kafka offre de nombreuses fonctionnalités, mais une grande partie du travail est impliquée dans sa configuration. Azure HDInsight apporte les meilleures infrastructures d’analyse Open source sur Azure et permet aux clients de configurer facilement leurs clusters Open source en quelques minutes, au lieu de consacrer des semaines ou des mois à la configuration de ces clusters, et vous pouvez les utiliser immédiatement. HDInsight est également prêt pour l’entreprise avec les avantages suivants :
- Il s’agit d’un service administré qui propose un processus de configuration simplifiée. En résulte une configuration testée et prise en charge par Microsoft.
- Microsoft fournit un contrat de niveau de service (SLA) de 99,9 % sur la disponibilité de Spark et Kafka.
- Il utilise Azure Disques managés comme magasin de stockage pour Kafka. Managed Disks peut fournir jusqu’à 16 To de stockage par répartiteur Kafka, avec plusieurs répartiteurs Kafka.
- HDInsight offre la meilleure sécurité d’entreprise grâce aux réseaux virtuels, une sécurité fine avec Apache Ranger et un chiffrement Bring Your Own Key (BYOK) pour les données au repos
- Conformité pour HIPAA, SOC et PCI
- Possibilité de déployer des pipelines de diffusion en continu de bout en bout avec Spark et le stockage via des modèles ARM (Automated Azure Resource Manager) dans le même réseau virtuel.
- La haute disponibilité peut être obtenue avec Kafka MirrorMaker, qui peut consommer des enregistrements à partir des rubriques du cluster principal, puis créer une copie locale sur le cluster secondaire.
- HDInsight permet de modifier le nombre de nœuds de travail (qui hébergent le répartiteur Kafka) après la création du cluster. La mise à l’échelle peut être effectuée depuis le portail Azure, Azure PowerShell et d’autres interfaces de gestion Azure. Pour Kafka, vous devez rééquilibrer les réplicas de partition après les opérations de mise à l’échelle. Le rééquilibrage des partitions permet à Kafka de tirer parti du nouveau nombre de nœuds de travail.
- Les journaux d’activité Azure Monitor peuvent servir à superviser Kafka sur HDInsight. Azure Monitor journalise les informations au niveau de l’ordinateur virtuel, telles que les métriques de disque et de carte réseau, et les métriques JMX à partir de Kafka.