Considérations sur l’épinglage de processus
Pourquoi épingler des processus et des threads ?
Épinglez toujours des processus à des cœurs spécifiques pour favoriser des performances maximales et rendre les performances plus cohérentes à chaque exécution.
Épinglage des processus :
Optimise la bande passante mémoire en plaçant ou en épinglant les processus à des emplacements qui utilisent tous les canaux de mémoire et les distribuent de façon égale entre les cœurs.
Améliore les performances de calcul en virgule flottante en garantissant que chaque processus figure sur son propre cœur. Cela élimine la possibilité d’avoir deux processus sur le même cœur.
Optimise le déplacement des données entre les processus en plaçant les processus qui communiquent dans des nœuds de domaine NUMA (Non-Uniform Memory Access). Cela leur garantit d’avoir une latence minimale et une bande passante maximale.
Réduit la surcharge du système d’exploitation et permet d’obtenir des résultats plus cohérents, car le système d’exploitation ne peut pas déplacer les processus vers des domaines NUMA ou des cœurs différents.
Où épingler les processus et les threads ?
Pour déterminer où épingler les processus et les threads, vous devez comprendre la topologie du processeur et de la mémoire, et notamment le nombre et l’emplacement des domaines NUMA.
L’utilitaire lstopo-no-Graphics (à partir de hwloc RPM) et le vérificateur de latence de la mémoire Intel Memory Latency Checker (MLC) sont des outils utiles pour déterminer la topologie du processeur et de la mémoire. Par exemple : combien de domaines NUMA la machine virtuelle possède-t-elle ? Quels cœurs font partie des différents domaines NUMA ? Quelle est la latence et la bande passante pour les processus dans chaque domaine NUMA quand ils communiquent les uns avec les autres ?
L’illustration suivante montre le mappage de latence de domaine NUMA pour HB120_v2 générée par Intel MLC. Plus la latence est faible entre les domaines NUMA, plus la communication est rapide entre eux. Cette illustration montre clairement que HB120_v2 a 30 domaines NUMA, et quels domaines NUMA sont sur quel socket. Elle montre également quels domaines NUMA peuvent être regroupés pour obtenir le transfert de données et la latence de communication les plus faibles.

Les processeurs Intel ont six canaux de mémoire et les processeurs AMD EPYC en possèdent huit. Veillez à utiliser tous les canaux de mémoire pour optimiser la bande passante mémoire disponible. Pour cela, répartissez les processus parallèles uniformément entre les domaines de nœud NUMA. Pour les applications parallèles hybrides, conservez le regroupement des processus/threads dans les mêmes domaines NUMA, si possible en partageant le même cache L3. Assurez-vous que le nombre total de threads ne dépasse pas le nombre total de cœurs.
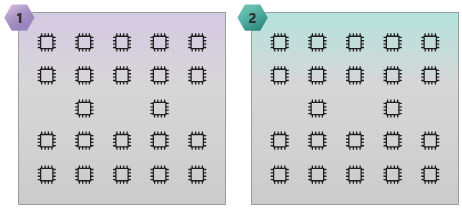
L’image suivante illustre une référence SKU HC44 avec 2 domaines NUMA et 44 cœurs.
L’image suivante illustre une référence SKU HB60 avec 15 domaines NUMA et 60 cœurs.
Applications subordonnées à la bande passante mémoire
Si vous avez une application limitée par une bande passante mémoire, vous pouvez obtenir de meilleures performances sur la machine virtuelle en réduisant le nombre de threads et de processus parallèles dans chaque domaine de nœud NUMA. Cela peut permettre d’obtenir une bande passante mémoire supérieure par processus et de réduire éventuellement la durée totale d’exécution.
Par exemple, si vous utilisez la référence SKU HB120_v2 avec 30 domaines de nœud NUMA, vous pouvez essayer d’exécuter 1, 2 et 3 processus et threads par domaine de nœud NUMA (par exemple : 30, 60 et 90 processus et threads par machine virtuelle). Vous pouvez ensuite voir quelle configuration offre les meilleures performances.