Intégration et déploiement continus
L’intégration continue consiste à tester automatiquement et, dès que possible, chaque modification apportée à votre code base. La livraison continue fait suite au test effectué pendant l’intégration continue, et envoie (push) les modifications à un système de préproduction ou de production.
Dans Azure Data Factory, l’intégration et la livraison continues (CI/CD) impliquent de déplacer des pipelines Data Factory d’un environnement (développement, test, production) vers un autre. Azure Data Factory utilise des modèles Azure Resource Manager pour stocker la configuration de vos diverses entités Azure Data Factory (pipelines, jeux de données, flux de données, etc.). Deux méthodes sont recommandées pour promouvoir une fabrique de données dans un autre environnement :
- Déploiement automatisé grâce à l’intégration de Data Factory avec Azure Pipelines.
- Chargement manuel d’un modèle Resource Manager en tirant parti de l’intégration de l’expérience utilisateur de Data Factory avec Azure Resource Manager.
Intégration continue et livraison continue
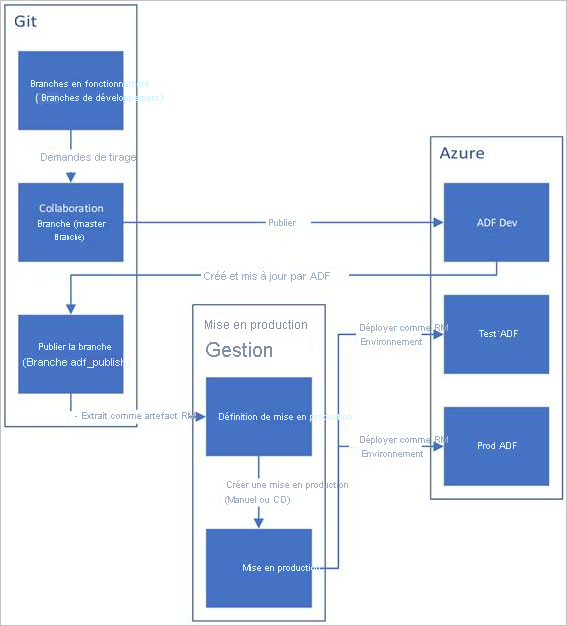
Vous trouverez ci-dessous une vue d’ensemble du cycle de vie d’intégration et de livraison continues dans une fabrique de données Azure configurée avec Azure Repos Git.
Une fabrique de données de développement est créée et configurée avec Azure Repos Git. Tous les développeurs doivent avoir l’autorisation de créer des ressources Data Factory telles que des pipelines et des jeux de données.
Un développeur crée une branche de fonctionnalité pour apporter une modification. Il débogue les exécutions de son pipeline avec ses modifications les plus récentes.
Une fois que le développeur est satisfait de ses modifications, il crée une demande de tirage (pull) à partir de sa branche de fonctionnalité vers la branche principale ou la branche de collaboration pour que ces modifications soient examinées par des pairs.
Une fois qu’une demande de tirage (pull) a été approuvée et que les modifications ont été fusionnées dans la branche principale, les modifications sont publiées dans la fabrique de développement.
Lorsque l’équipe est prête à déployer les modifications dans une fabrique de test ou de test d’acceptation utilisateur (UAT), elle accède à la mise en production sur Azure Pipelines et déploie la version souhaitée de la fabrique de développement vers l’UAT. Ce déploiement a lieu dans le cadre d’une tâche Azure Pipelines et utilise des paramètres de modèle Resource Manager pour appliquer la configuration appropriée.
Une fois les modifications vérifiées dans la fabrique de test, opérez le déploiement vers la fabrique de production en utilisant la tâche suivante de la mise en production de pipelines.
Notes
Seule la fabrique de développement est associée à un dépôt Git. Les fabriques de test et de production ne doivent pas avoir de dépôt Git associé et ne doivent être mises à jour que via un pipeline Azure DevOps ou un modèle de gestion des ressources.
L’image ci-dessous met en évidence les différentes étapes de ce cycle de vie.
Automatiser l’intégration continue à l’aide des versions d’Azure Pipelines
Vous trouverez ci-après un guide de configuration d’une mise en production Azure Pipelines qui automatise le déploiement d’une fabrique de données dans plusieurs environnements.
Spécifications
Un abonnement Azure lié à Visual Studio Team Foundation Server ou Azure Repos qui utilise le point de terminaison de service Azure Resource Manager
Une fabrique de données configurée avec l’intégration d’Azure Repos Git.
Un coffre de clés Azure contenant les secrets pour chaque environnement.
Configurer une version d’Azure Pipelines
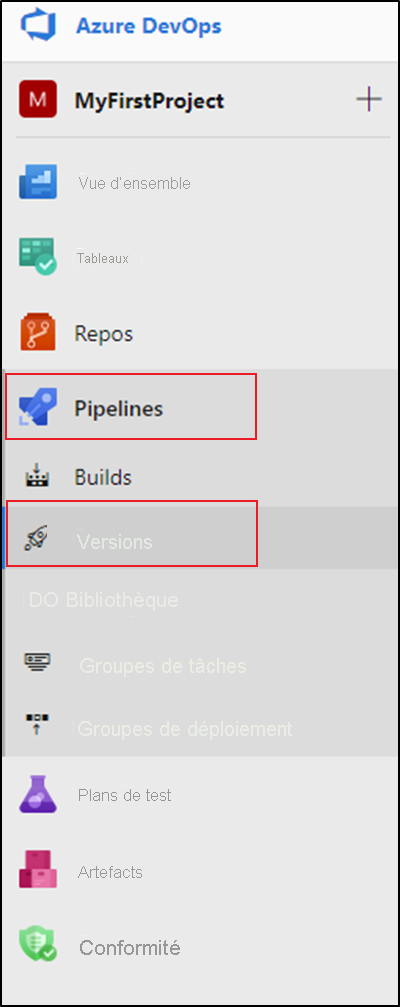
Dans Azure DevOps, ouvrez le projet configuré avec votre fabrique de données.
Sur le côté gauche de la page, sélectionnez Pipelines, puis sélectionnez Versions.
Sélectionnez Nouveau pipeline ou, si vous avez des pipelines existants, sélectionnez Nouveau puis Nouveau pipeline de mise en production.
Sélectionnez le modèle Tâche vide.
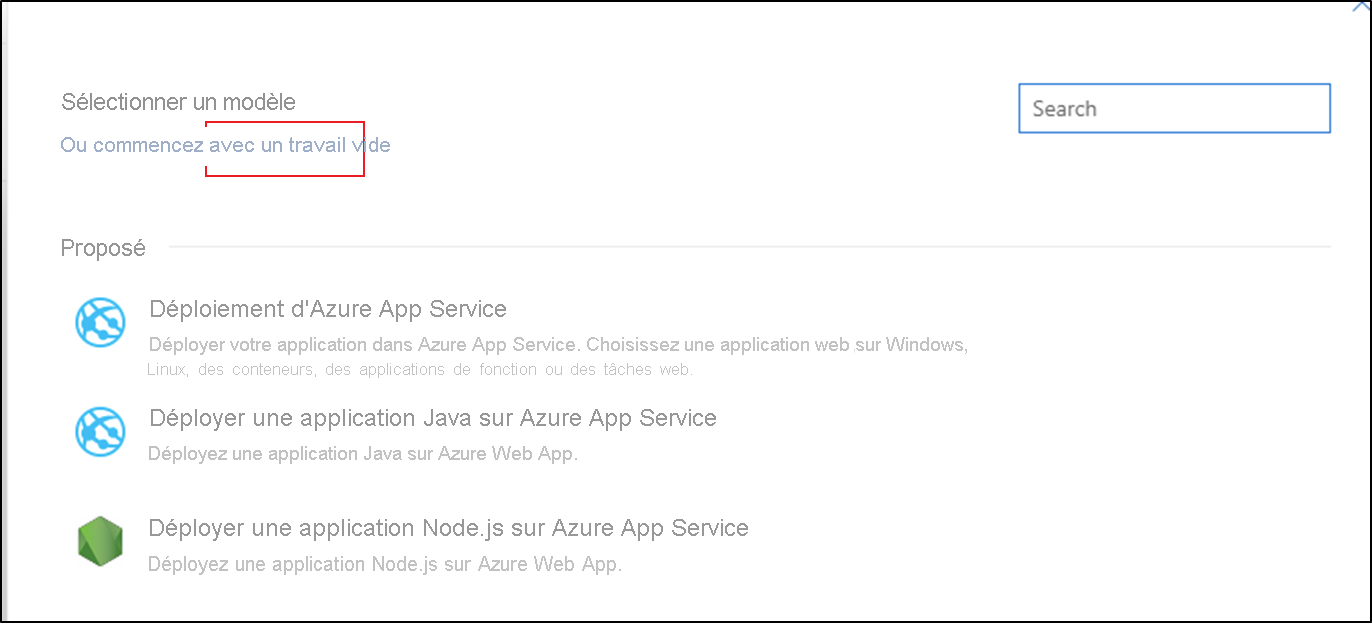
Dans la zone Nom de la phase, entrez le nom de votre environnement.
Sélectionnez Ajouter un artefact, puis choisissez le dépôt Git configuré avec votre fabrique de données de développement. Sélectionnez la branche de publication du dépôt comme branche par défaut. Par défaut, cette branche de publication est
adf_publish. Pour Version par défaut, sélectionnez La dernière de la branche par défaut.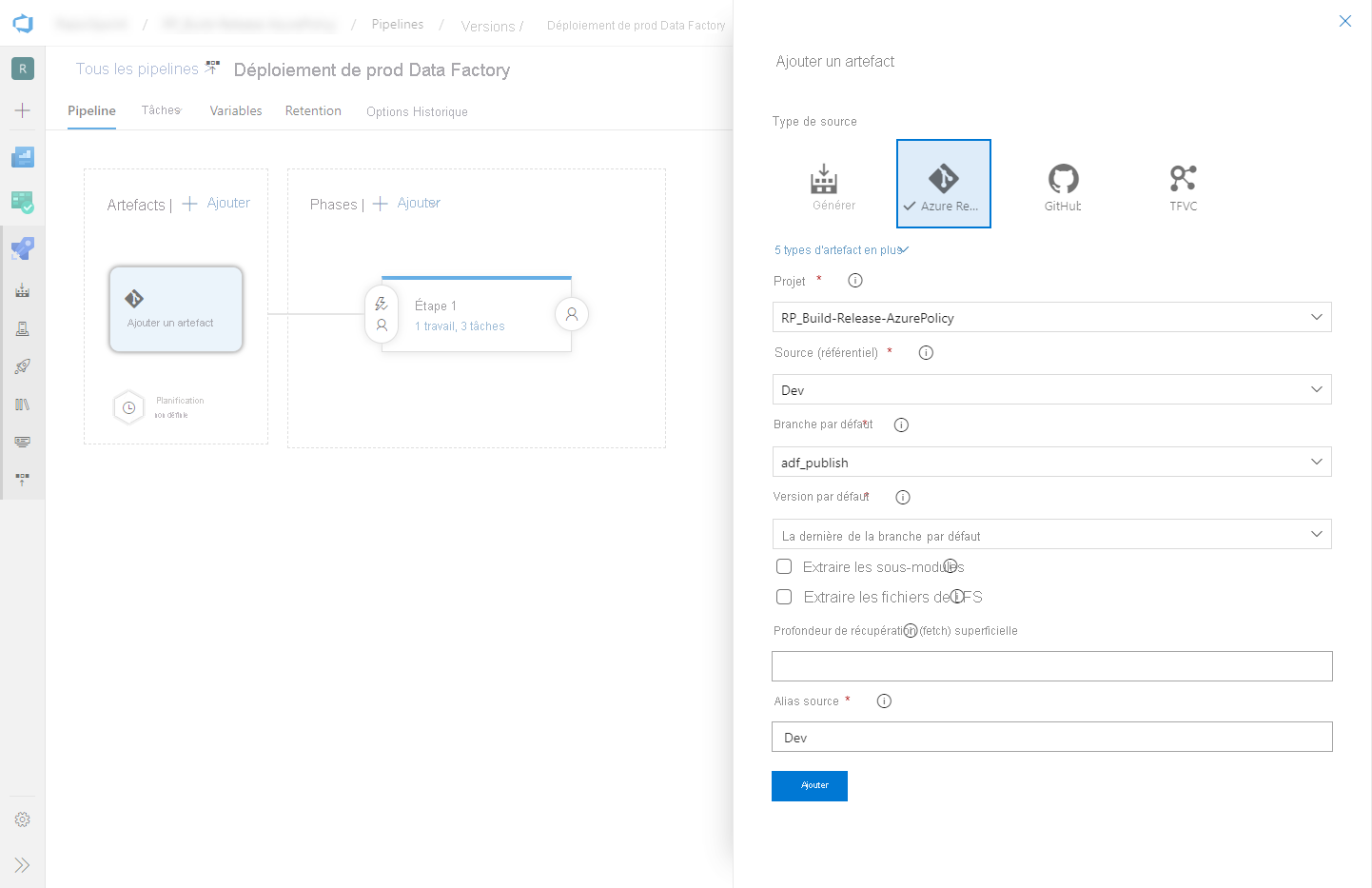
Ajoutez une tâche de déploiement Azure Resource Manager :
a. Dans la vue des phases, sélectionnez Afficher les tâches de phase.
b. Créer une tâche. Recherchez Déploiement de modèles ARM, puis sélectionnez Ajouter.
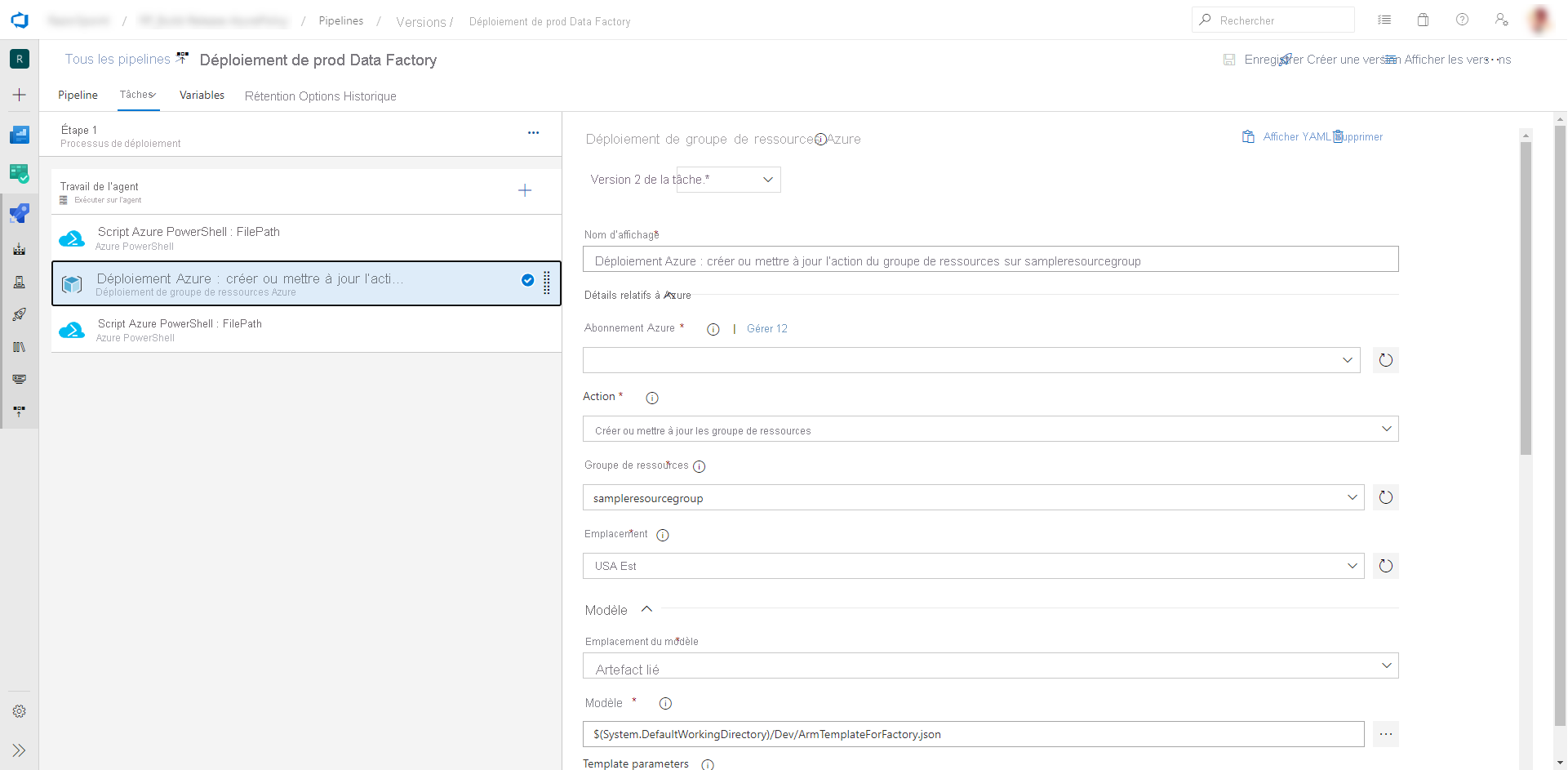
c. Dans la tâche Déploiement, sélectionnez l’abonnement, le groupe de ressources et l’emplacement de la fabrique de données cible. Fournissez les informations d’identification si nécessaire.
d. Dans la liste Actions, sélectionnez Créer ou mettre à jour un groupe de ressources.
e. Sélectionnez le bouton de sélection ( … ) en regard de la zone Modèle. Recherchez le modèle Azure Resource Manager généré dans votre branche de publication du dépôt Git configuré. Recherchez le fichier
ARMTemplateForFactory.jsondans le dossier<FactoryName>de la branche adf_publish.f. Sélectionnez … à côté de la zone Paramètres du modèle pour choisir le fichier de paramètres. Recherchez le fichier
ARMTemplateParametersForFactory.jsondans le dossier<FactoryName>de la branche adf_publish.g. Sélectionnez … à côté de la zone Remplacer les paramètres du modèle, puis entrez les valeurs de paramètre souhaitées pour la fabrique de données cible. Pour les informations d’identification provenant d’Azure Key Vault, entrez le nom du secret entre guillemets doubles. Par exemple, si le nom du secret est cred1, entrez "$(cred1)" pour cette valeur.
h. Sélectionnez Incrémentiel comme Mode de déploiement.
Avertissement
En mode de déploiement complet, les ressources présentes dans le groupe de ressources mais pas spécifiées dans le modèle Resource Manager sont supprimées.
Enregistrez le pipeline de mise en production.
Pour déclencher une mise en production, sélectionnez Créer une mise en production. Dans Azure DevOps, cela peut être automatisé.



Important
Dans les scénarios d’intégration et de livraison continues, le type de runtime d’intégration (IR) doit être le même dans les différents environnements. Par exemple, si vous avez un runtime d’intégration auto-hébergé dans l’environnement de développement, le même runtime d’intégration doit aussi être de type auto-hébergé dans les autres environnements (test, production). De même, si vous partagez des runtimes d’intégration dans plusieurs phases, vous devez les configurer comme étant liés et auto-hébergés dans tous les environnements (développement, test, production).
Obtenez les secrets à partir du coffre Azure Key Vault
Si vous avez des secrets à transmettre dans un modèle Azure Resource Manager, nous vous recommandons d’utiliser Azure Key Vault avec la version Azure Pipelines.
Il existe deux moyens de gérer les secrets :
Ajoutez les secrets au fichier de paramètres.
Créez une copie du fichier de paramètres qui sera chargée dans la branche de publication. Définissez les valeurs des paramètres que vous souhaitez obtenir à partir du coffre de clés avec le format suivant :
{ "parameters": { "azureSqlReportingDbPassword": { "reference": { "keyVault": { "id": "/subscriptions/<subId>/resourceGroups/<resourcegroupId> /providers/Microsoft.KeyVault/vaults/<vault-name> " }, "secretName": " < secret - name > " } } } }Lorsque vous utilisez cette méthode, le secret est automatiquement extrait du coffre de clés.
Le fichier de paramètres doit également être dans la branche de publication.
Ajoutez une tâche Azure Key Vault avant la tâche de déploiement d’Azure Resource Manager décrite dans la section précédente :
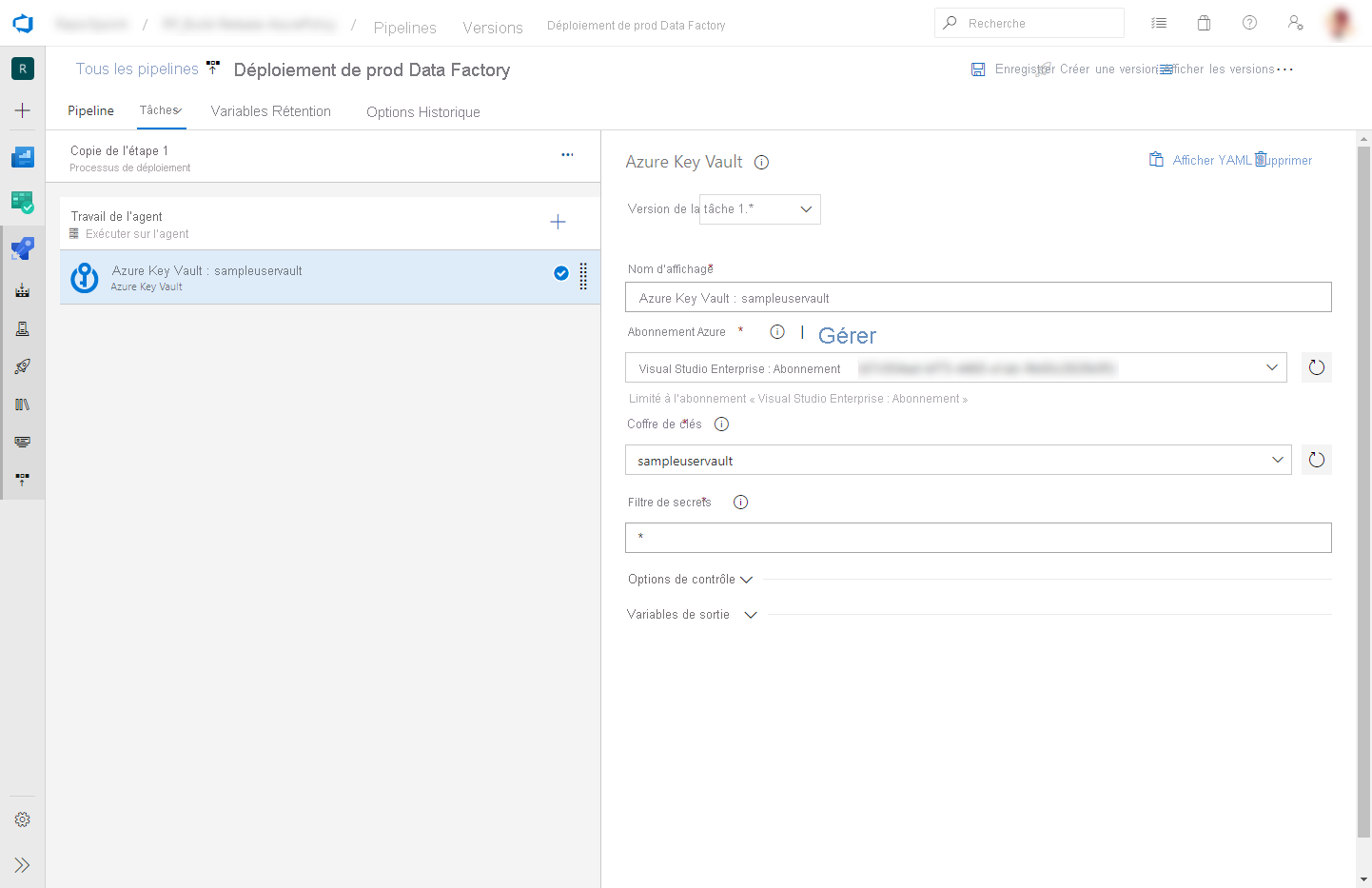
Dans l’onglet Tâches, créez une nouvelle tâche. Recherchez Azure Key Vault et ajoutez-le.
Dans la tâche Key Vault, sélectionnez l’abonnement dans lequel vous avez créé le coffre de clés. Fournissez les informations d’identification si nécessaire, puis sélectionnez le coffre de clés.

Accorder des autorisations à l’agent Azure Pipelines
La tâche Azure Key Vault peut échouer avec une erreur d’accès refusé si les autorisations appropriées ne sont pas définies. Téléchargez les journaux de la version, puis recherchez le fichier .ps1 contenant la commande pour accorder des autorisations à l’agent Azure Pipelines. Vous pouvez exécuter directement la commande. Vous pouvez aussi copier l’ID du principal à partir du fichier et ajouter manuellement la stratégie d’accès dans le Portail Azure. Get et List sont les autorisations minimales requises.
Mise à jour des déclencheurs actifs
Le déploiement peut échouer si vous tentez de mettre à jour les déclencheurs actifs. Pour mettre à jour les déclencheurs actifs, vous devez les arrêter manuellement puis les redémarrer après le déploiement. Vous pouvez le faire à l’aide d’une tâche Azure PowerShell :
Dans l’onglet Tâches de la version, ajoutez une tâche Azure Powershell. Choisissez une tâche de version 4.*.
Sélectionnez l’abonnement dans lequel se trouve votre fabrique.
Sélectionnez Chemin d’accès au fichier de script comme type de script. Pour cela, vous devez enregistrer votre script PowerShell dans votre référentiel. Le script PowerShell suivant peut être utilisé pour arrêter des déclencheurs :
$triggersADF = Get-AzDataFactoryV2Trigger -DataFactoryName $DataFactoryName -ResourceGroupName $ResourceGroupName $triggersADF | ForEach-Object { Stop-AzDataFactoryV2Trigger -ResourceGroupName $ResourceGroupName -DataFactoryName $DataFactoryName -Name $_.name -Force }
Vous pouvez suivre des étapes similaires (avec la fonction Start-AzDataFactoryV2Trigger) pour redémarrer les déclencheurs après le déploiement.
Notes
Ces étapes sont déjà incluses dans les scripts de pré-déploiement et de publication fournis par l’équipe d’Azure Data Factory
Promouvoir manuellement un modèle Resource Manager pour chaque environnement
Si vous ne parvenez pas à utiliser Azure DevOps ou un autre outil de gestion des mises en production, vous pouvez promouvoir manuellement une fabrique de données à l’aide d’un modèle ARM.
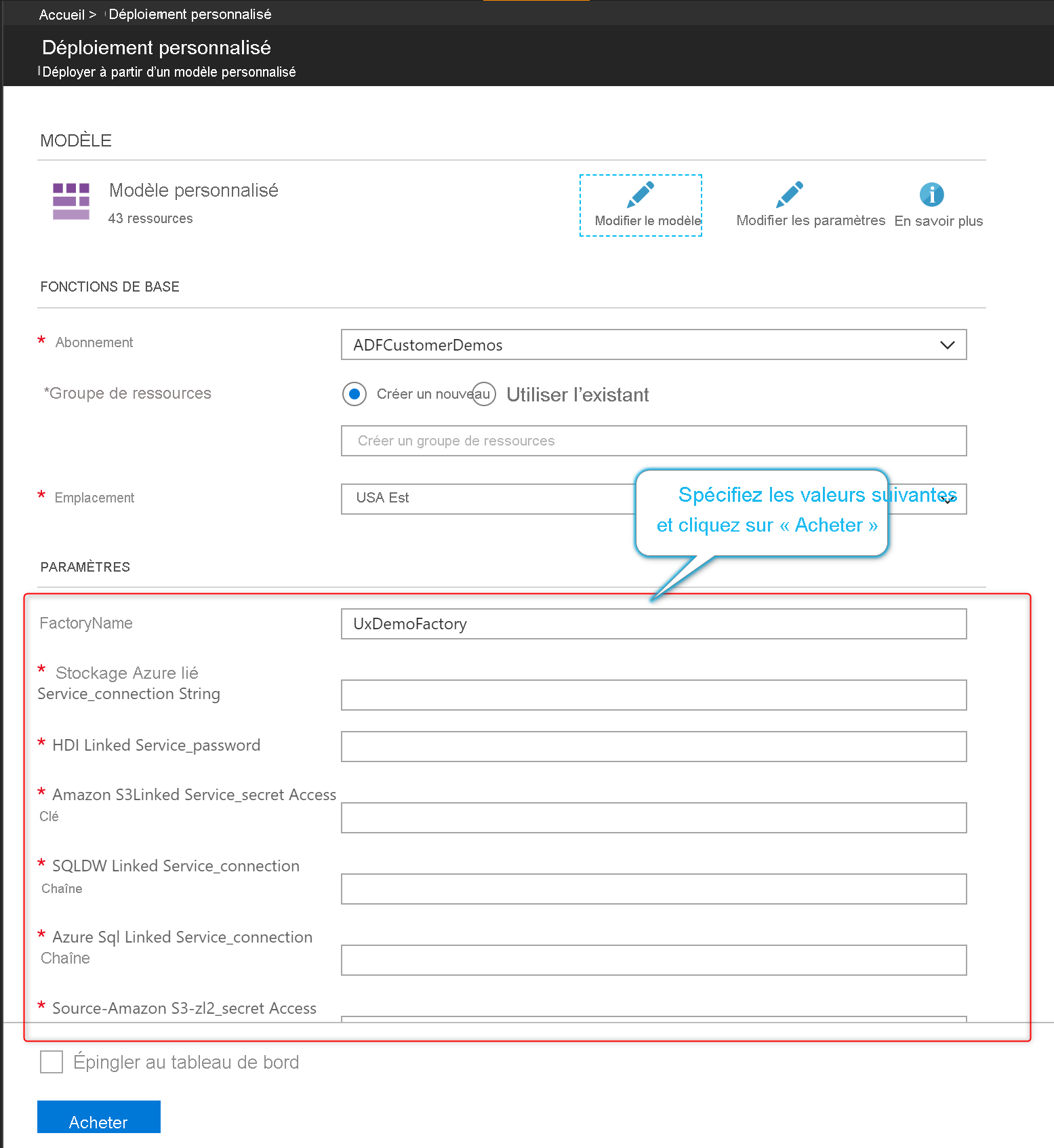
Dans la liste Modèle ARM, sélectionnez Exporter un modèle ARM pour exporter le modèle Resource Manager de votre fabrique de données dans l’environnement de développement.

Dans vos fabriques de données de test et de production, sélectionnez Importer un modèle ARM. Cette action ouvre le portail Azure, dans lequel vous pouvez importer le modèle exporté. Sélectionnez Créer votre propre modèle dans l’éditeur pour ouvrir l’éditeur de modèle Resource Manager.
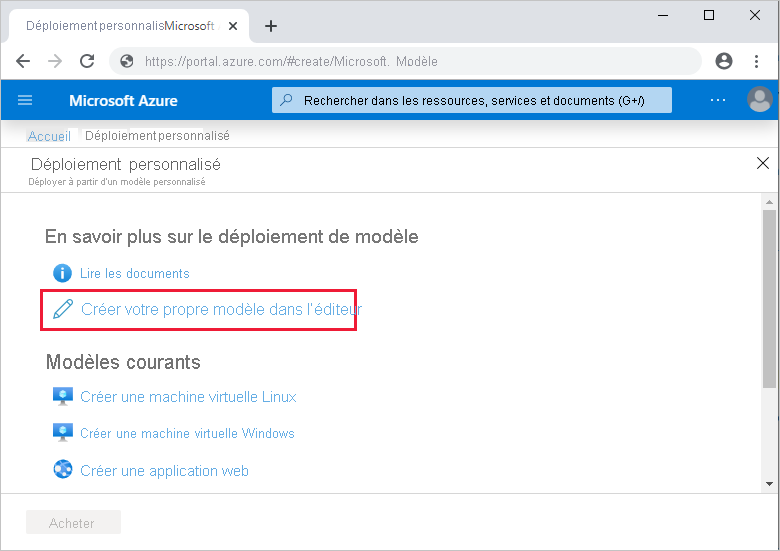
Sélectionnez Charger le fichier, puis sélectionnez le modèle Resource Manager généré. Il s’agit du fichier arm_template.json situé dans le fichier .zip exporté à l’étape 1.
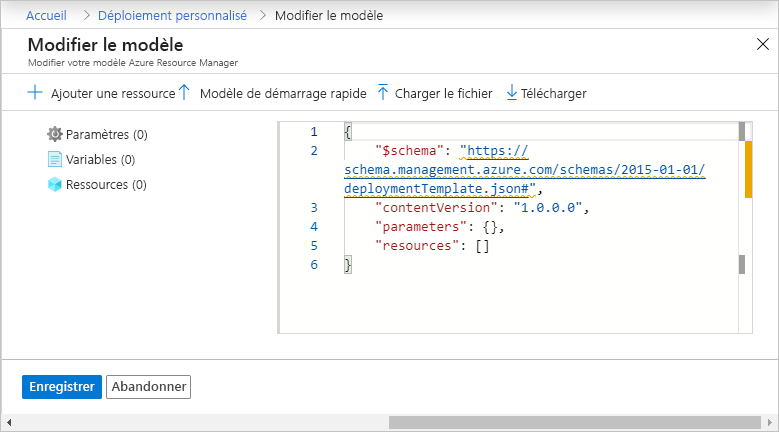
Dans la section des paramètres, entrez les valeurs de configuration telles que les informations d’identification du service lié. Lorsque vous avez terminé, sélectionnez Acheter pour déployer le modèle Resource Manager.
Personnaliser les paramètres de modèle Azure Resource Manager
Si votre fabrique de développement dispose d’un dépôt Git associé, vous pouvez remplacer les paramètres du modèle Resource Manager par défaut du modèle Resource Manager généré en publiant ou exportant le modèle. Vous souhaiterez peut-être remplacer le modèle de paramétrage par défaut dans les scénarios suivants :
- Vous utilisez CI/CD automatisé et souhaitez modifier certaines propriétés pendant le déploiement de Resource Manager, mais les propriétés ne sont pas paramétrables par défaut.
- Votre fabrique est si volumineuse que le modèle Resource Manager par défaut n’est pas valide car il dépasse le nombre maximum autorisé de paramètres (256).
Pour remplacer le modèle de paramétrage par défaut, accédez au hub de gestion et sélectionnez Modèle de paramétrage dans la section de contrôle de code source. Sélectionnez Modifier le modèle pour ouvrir l’éditeur de code du modèle de paramétrage.
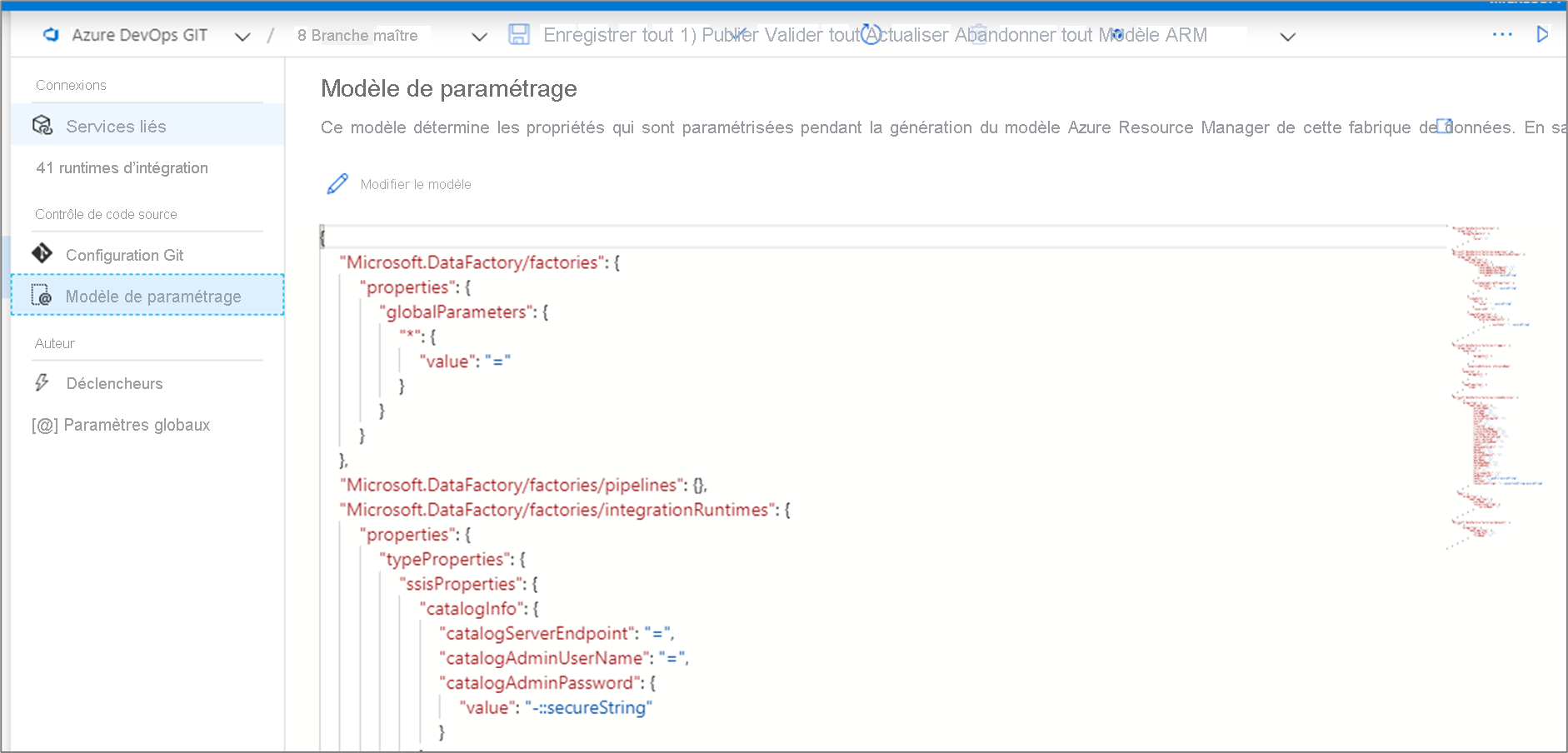
La création d’un modèle de paramétrage personnalisé, crée un fichier nommé arm-template-parameters-definition.json dans le dossier racine de votre branche Git. Vous devez utiliser ce nom de fichier exact.
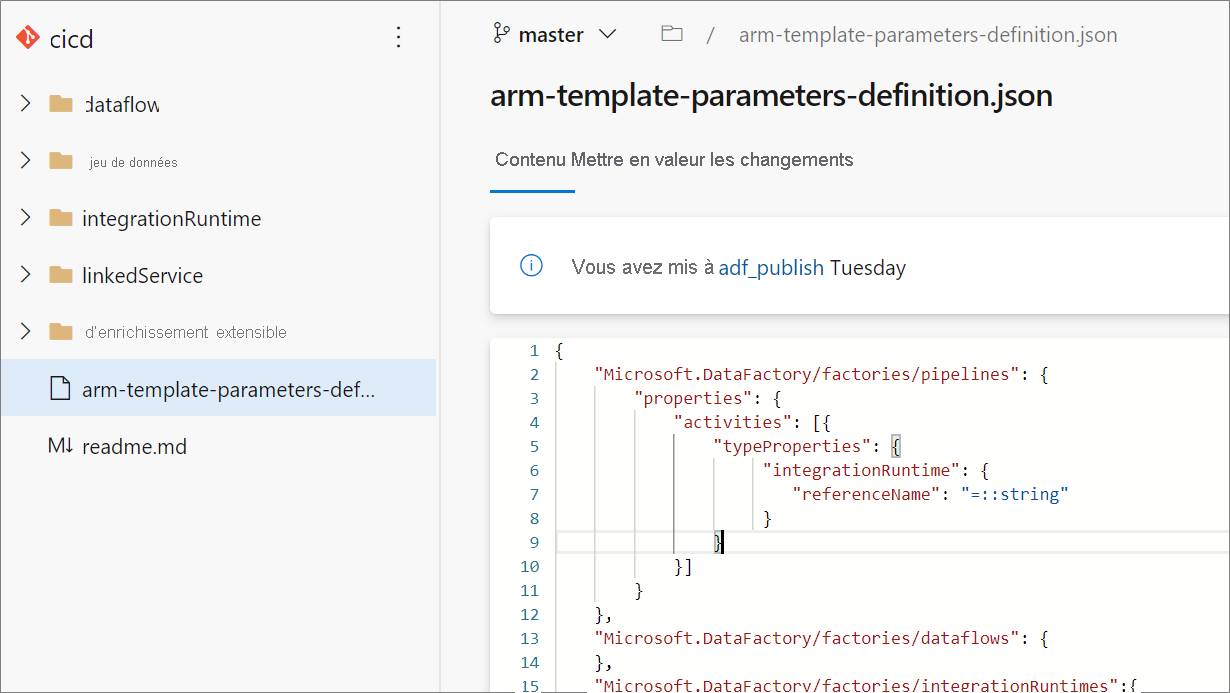
Lors de la publication à partir de la branche de collaboration, Data Factory lit ce fichier et utilise sa configuration pour générer les propriétés qui sont paramétrées. Si aucun fichier n’est trouvé, le modèle par défaut est utilisé.
Lors de l’exportation d’un modèle Resource Manager, Data Factory lit ce fichier à partir de la branche sur laquelle vous travaillez actuellement, et pas de la branche de collaboration. Vous pouvez créer ou modifier le fichier à partir d’une branche privée, dans laquelle vous pouvez tester vos modifications en sélectionnant Exporter le modèle ARM dans l’interface utilisateur. Vous pouvez ensuite fusionner le fichier dans la branche de collaboration.
Notes
Un modèle de paramétrage personnalisé ne change pas la limite de 256 paramètres du modèle ARM. Il vous permet de choisir et de diminuer le nombre de propriétés paramétrées.
Syntaxe de paramètre personnalisé
Vous trouverez ci-dessous quelques recommandations à suivre lorsque vous créez le fichier de paramètres personnalisés arm-template-parameters-definition.json. Le fichier comprend une section pour chaque type d’entité : déclencheur, pipeline, service lié, jeu de données, runtime d’intégration et flux de données.
- Entrez le chemin d’accès de propriété sous le type d’entité correspondant.
- Définir un nom de propriété sur
*indique que vous souhaitez paramétrer toutes les propriétés dans celle-ci (uniquement jusqu’au premier niveau, pas de manière récursive). Vous pouvez également fournir des exceptions à cette configuration. - Définir la valeur d’une propriété sous forme de chaîne indique que vous souhaitez paramétrer la propriété. Utilisez le format
<action>:<name>:<stype>.<action>peut être l’un des caractères suivants :=permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre.-permet de ne pas conserver la valeur par défaut pour le paramètre.|est un cas particulier pour les secrets Azure Key Vault pour les chaînes de connexion ou les clés.
<name>correspond au nom du paramètre. S’il est vide, il prend le nom du Si la valeur commence par un caractère-, le nom est abrégé. Par exemple,AzureStorage1_properties_typeProperties_connectionStringserait abrégé enAzureStorage1_connectionString.<stype>correspond au type de paramètre. Si<stype>est vide, le type par défaut eststring. Valeurs prises en charge :string,bool,number,objectetsecurestring.
- La spécification d’un tableau dans le fichier de définition indique que la propriété correspondante dans le modèle est un tableau. Data Factory effectue une itération sur tous les objets du tableau en utilisant la définition spécifiée dans l’objet de runtime d’intégration du tableau. Le second objet, une chaîne, correspond alors au nom de la propriété et sert de nom au paramètre pour chaque itération.
- Une définition ne peut pas être spécifique à une instance de ressource. Toute définition s’applique à toutes les ressources de ce type.
- Par défaut, toutes les chaînes sécurisées, telles que les secrets Key Vault, et les chaînes sécurisées, telles que les chaînes de connexion, les clés et les jetons, sont paramétrables.
Modèles liés
Si vous avez configuré l’intégration et la livraison continues (CI/CD) pour vos fabriques de données, vous pouvez dépasser les limites du modèle Azure Resource Manager lorsque votre fabrique croît. Par exemple, le nombre maximal de ressources dans un modèle Resource Manager est une limite. Pour prendre en compte des fabriques de grande taille tout en générant le modèle Resource Manager complet pour une fabrique, Data Factory génère désormais des modèles Resource Manager liés. Avec cette fonctionnalité, la charge utile de fabrique entière est divisée en plusieurs fichiers, pour que vous ne soyez pas contraint par les limites.
Si vous avez configuré Git, les modèles liés sont générés et enregistrés en même temps que les modèles Resource Manager complets, dans la branche adf_publish, dans un nouveau dossier nommé linkedTemplates. Les modèles Resource Manager liés sont généralement composés d’un modèle maître et d’un ensemble de modèles enfants liés au maître. Le modèle parent est appelé ArmTemplate_master.json et les modèles enfants sont nommés selon le modèle ArmTemplate_0.json, ArmTemplate_1.json, etc.
Pour utiliser des modèles liés à la place du modèle Resource Manager complet, mettez à jour votre tâche CI/CD de manière à pointer vers ArmTemplate_master.json plutôt que vers ArmTemplateForFactory.json (modèle Resource Manager complet). Resource Manager exige également que vous chargiez les modèles liés dans un compte de stockage pour qu’Azure puisse y accéder pendant le déploiement.
Environnement de production de correctif logiciel
Si vous déployez une fabrique en production et détectez un bogue qui doit être corrigé immédiatement, mais que vous ne pouvez pas déployer la branche de collaboration actuelle, vous devrez peut-être déployer un correctif logiciel. Cette approche est également connue sous le nom de QFE (Quick-Fix Engineering).
Dans Azure DevOps, accédez à la version qui a été déployée en production. Recherchez la dernière validation qui a été déployée.
À partir du message de validation, obtenez l’ID de validation de la branche de collaboration.
Créez une nouvelle branche de correctifs logiciels à partir de cette validation.
Accédez à l’expérience utilisateur Azure Data Factory et basculez vers cette branche de correctifs logiciels.
Corrigez le bogue en utilisant l’expérience utilisateur Azure Data Factory. Tester vos modifications.
Une fois le correctif vérifié, sélectionnez Exporter le modèle ARM pour obtenir le modèle Resource Manager du correctif logiciel.
Archivez manuellement cette build dans la branche de publication.
Si vous avez configuré votre pipeline de mise en production pour qu’il se déclenche automatiquement en fonction des archivages adf_publish, une nouvelle version démarre automatiquement. Sinon, créez manuellement une file d'attente de versions.
Déployez la version avec correctif logiciel dans les fabriques de test et de production. Cette version contient la charge utile de production précédente ainsi que la correction apportée à l’étape 5.
Ajoutez les modifications issues du correctif logiciel dans la branche de développement pour que les versions ultérieures n’incluent pas le même bogue.
Bonnes pratiques pour l’intégration et la livraison continues
Si vous utilisez une intégration Git avec votre fabrique de données, et disposez d’un pipeline CI/CD qui déplace vos modifications du développement aux tests, puis en production, nous vous recommandons les bonnes pratiques suivantes :
Intégration Git. Configurez uniquement votre fabrique de données de développement avec l’intégration Git. Les modifications au niveau des tests et de la production sont déployées via CI/CD et ne nécessitent pas d’intégration Git.
Script de pré-déploiement et de post-déploiement. Avant l’étape de déploiement Resource Manager dans CI/CD, vous devez effectuer certaines tâches, telles que l’arrêt et le redémarrage des déclencheurs, et le nettoyage. Nous vous recommandons d’utiliser des scripts PowerShell avant et après la tâche de déploiement. L'équipe de Data Factory a fourni un script à utiliser dans la page de documentation « CI/CD dans Azure Data Factory ».
Runtimes d’intégration et partage. Les runtimes d’intégration ne changent pas souvent et sont similaires dans toutes les phases de CI/CD. Ainsi, Data Factory s’attend à ce que vous ayez le même nom et le même type de runtime d’intégration dans toutes les phases de CI/CD. Si vous voulez partager les runtimes d’intégration dans toutes les phases, envisagez d’utiliser une fabrique ternaire qui contiendra uniquement les runtimes d’intégration partagés. Vous pouvez utiliser cette fabrique partagée dans tous vos environnements en tant que type de runtime d’intégration lié.
Déploiement du point de terminaison privé managé. Si un point de terminaison privé existe déjà dans une fabrique et que vous essayez de déployer un modèle ARM qui contient un point de terminaison privé portant le même nom mais dont les propriétés sont modifiées, le déploiement échoue. En d’autres termes, vous pouvez déployer avec succès un point de terminaison privé, à condition qu’il ait les mêmes propriétés que celui qui existe déjà dans la fabrique. Si une propriété est différente d’un environnement à un autre, vous pouvez la remplacer en paramétrant cette propriété et en fournissant la valeur correspondante pendant le déploiement.
Key Vault. Lorsque vous utilisez des services liés dont les informations de connexion sont stockées dans Azure Key Vault, il est recommandé de conserver des coffres de clés distincts pour les différents environnements. Vous pouvez également configurer des niveaux d’autorisation distincts pour chaque coffre de clés. Par exemple, vous ne souhaitez peut-être pas que les membres de votre équipe disposent d’autorisations sur les secrets de production. Si vous suivez cette approche, nous vous recommandons de conserver les mêmes noms de secrets dans toutes les phases. Si vous conservez les mêmes noms secrets, vous n’avez pas besoin de paramétrer chaque chaîne de connexion dans les environnements d’intégration et de livraison continues, car la seule chose qui change est le nom du coffre de clés, qui est un paramètre distinct.
Nommage des ressources En raison de contraintes liées au modèle ARM, des problèmes de déploiement peuvent survenir si le nom de vos ressources contient des espaces. L’équipe Azure Data Factory recommande d’utiliser des caractères « _ » ou « - » au lieu d’espaces dans les noms de ressources. Par exemple, le nom « Pipeline_1 » est préférable à « Pipeline 1 ».