Explorer la migration de bases de données très volumineuses
Les systèmes SAP déplacés dans le cloud Azure incluent désormais généralement de grands systèmes multinationaux « d’instance globale unique ». Ces systèmes sont beaucoup plus volumineux que les premiers systèmes client déployés lorsque la plateforme Azure était d’abord certifiée pour les charges de travail SAP.
Les bases de données très volumineuses (VLDB) sont désormais fréquemment déplacées vers Azure. Les bases de données de plus de 20 To requièrent des techniques et des procédures supplémentaires pour effectuer une migration de l’environnement local vers Azure avec un temps d’arrêt acceptable et un risque réduit.
Vue d’ensemble globale
Une migration de base de données très volumineuse entièrement optimisée doit atteindre un débit de migration de 2 To par heure ou plus. Cela signifie que le composant de transfert de données d’une migration de 20 To peut être effectué en 10 heures environ. Plusieurs étapes d’après traitement et de validation doivent être effectuées. En général, avec un temps adapté à la préparation et le test, tout système client de toute taille peut être déplacé vers Azure.
Les migrations de VLDB nécessitent des compétences, une attention aux détails et une analyse considérables. Par exemple, l’effet net d’un fractionnement de table doit être mesuré et analysé. Les fractionnements d’une grande table dans plus de 50 exportations parallèles peuvent réduire considérablement le temps nécessaire à l’exportation d’une table, mais un nombre trop important de fractionnements de tables peut entraîner des temps d’importation considérablement accrus. C’est pourquoi l’impact net du fractionnement de table doit être calculé et testé. Un consultant en migration de système d’exploitation/base de données expérimenté doit bien connaître les concepts et les outils. Nous mettons en évidence du contenu propre à Azure pour les migrations VLDB.
En particulier, nous décrivons la migration de systèmes d’exploitation/bases de données hétérogènes vers Azure avec SQL Server comme base de données cible en utilisant des outils comme R3load et Migmon. Les étapes de migration ne sont pas prévues pour des copies système homogènes, c’est-à-dire une copie où l’architecture du SGBD et du processeur (ordre Endian) reste la même. En général, les copies système homogènes doivent avoir un temps d’arrêt faible, quelle que soit la taille du SGBD, car la copie des journaux de transaction peut être utilisée pour synchroniser une copie de la base de données dans Azure.
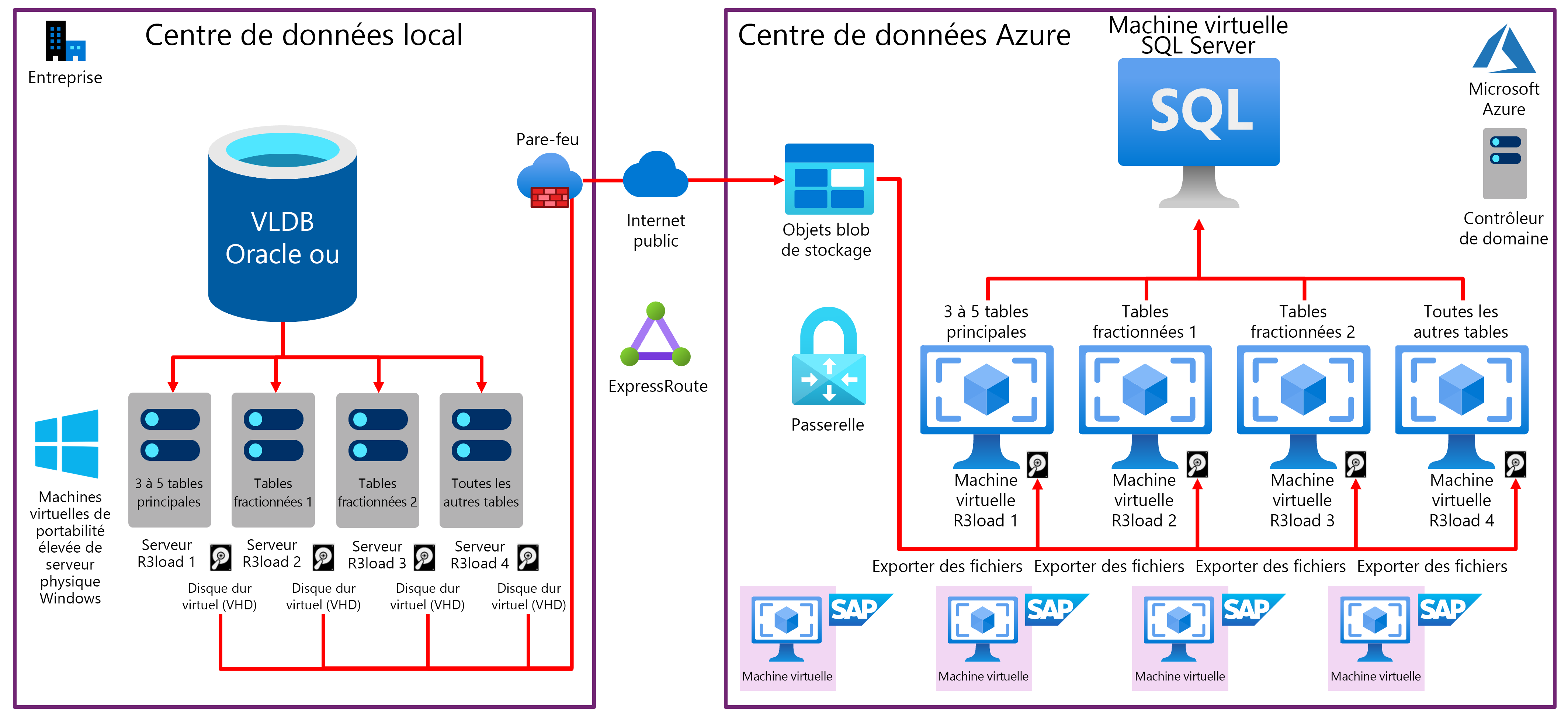
Un diagramme de blocs illustré représentant une migration classique de système d’exploitation/base de données VLDB et le déplacement vers Azure est présenté après les points clés :
Le système d’exploitation/la base de code source actuel est souvent AIX, HPUX, Solaris ou Linux ; et DB2 ou Oracle.
Le système d’exploitation cible est Windows, SUSE 12.3, Red Hat 7.x ou Oracle Linux 7.x.
La base de données cible est généralement SQL Server ou Oracle 12.2.
Le niveau de performance de thread d’IBM pSeries, de Solaris SPARC et de HP Superdome sont radicalement inférieures à celui des serveurs Intel modernes à faible coût. R3load est donc exécuté sur des serveurs Intel distincts.
VMWare requiert un paramétrage et une configuration spéciaux pour obtenir un niveau de performance réseau approprié, stable et prévisible. En règle générale, les serveurs physiques sont utilisés comme serveurs R3load et non comme machines virtuelles.
Généralement, quatre serveurs d’exportation R3load sont utilisés, même si le nombre de serveurs d’exportation n’est pas limité. Une configuration classique serait la suivante :
- Serveur d’exportation 1 – dédié aux plus grandes tables 1 à 4 (en fonction de la manière dont la distribution des données est faussée sur la base de données source).
- Serveur d’exportation 2 – dédié aux tables avec fractionnements de table.
- Serveur d’exportation 3 – dédié aux tables avec fractionnements de table.
- Serveur d’exportation 4 – toutes les tables restantes.
Les fichiers d’image mémoire de l’exportation sont transférés du disque local du serveur Intel R3load vers Azure en utilisant AzCopy sur l’Internet public. C’est généralement plus rapide qu’avec ExpressRoute.
Le contrôle et la séquence de l’importation s’effectuent via le fichier de signal (SGN) généré automatiquement lorsque tous les packages d’exportation sont terminés. Cela permet une exportation/importation semi-parallèle.
L’importation vers SQL Server ou Oracle est structurée de la même façon que l’exportation, à l’aide de quatre serveurs d’importation. Ces serveurs sont des serveurs R3load dédiés distincts avec mise en réseau accélérée. Les serveurs d’applications SAP ne sont pas recommandés pour cette tâche.
Les bases de données VLDB utilisent généralement des machines virtuelles E64v3, m64 ou m128 avec Stockage Premium. Le journal des transactions peut être placé sur le disque SSD local pour accélérer les écritures du journal des transactions et supprimer les IOPS et la bande passante d’E/S du journal des transactions du quota de machines virtuelles. Après la migration, le journal des transactions doit être placé sur un disque persistant.