Configurer le stockage et les bases de données
Souvent, une partie de votre processus de déploiement requiert que vous vous connectiez aux bases de données ou aux services de stockage. Cette connexion peut être nécessaire pour appliquer un schéma de base de données, ajouter des données de référence à une table de base de données ou charger des objets blob. Dans cette unité, vous découvrirez comment étendre votre pipeline pour travailler avec des services de données et de stockage.
Configurer vos bases de données à partir d’un pipeline
De nombreuses bases de données ont des schémas, qui représentent la structure des données contenues dans la base de données. Il est souvent recommandé d’appliquer un schéma à votre base de données à partir de votre pipeline de déploiement. Cette pratique permet de garantir que tous les éléments dont votre solution a besoin sont déployés ensemble. Cela permet aussi de s’assurer qu’en cas de problème quand le schéma est appliqué, votre pipeline affiche une erreur. L’erreur vous permet de corriger le problème et de redéployer.
Lorsque vous utilisez Azure SQL, vous devez appliquer des schémas de base de données en vous connectant au serveur de base de données et en exécutant des commandes à l’aide de scripts SQL. Ces commandes sont des opérations de plan de données. Votre pipeline doit s’authentifier auprès du serveur de base de données, puis exécuter les scripts. Azure Pipelines fournit la tâche SqlAzureDacpacDeployment qui peut se connecter à un serveur de base de données Azure SQL et exécuter des commandes.
Il n’est pas nécessaire de configurer d’autres services de données et de stockage à l’aide d’une API de plan de données. Par exemple, lorsque vous utilisez Azure Cosmos DB, vous stockez vos données dans un conteneur. Vous pouvez configurer vos conteneurs à l’aide du plan de contrôle, directement à partir de votre fichier Bicep. De même, vous pouvez déployer et gérer la plupart des aspects des conteneurs d’objets blob de Stockage Azure dans Bicep. Dans l’exercice suivant, vous verrez un exemple illustrant la façon de créer un conteneur d’objets blob à partir de Bicep.
Ajout de données
De nombreuses solutions nécessitent l’ajout de données de référence à leurs bases de données ou comptes de stockage avant de fonctionner. Il peut être judicieux d’ajouter ces données aux pipelines. Une fois le pipeline exécuté, votre environnement est entièrement configuré et prêt à être utilisé.
Il est également utile de disposer d’exemples de données dans vos bases de données, en particulier pour les environnements hors production. Les exemples de données aident les testeurs et autres personnes qui utilisent ces environnements à pouvoir tester immédiatement votre solution. Ces données peuvent inclure des exemples de produits ou des éléments tels que des faux comptes d’utilisateur. En règle générale, vous ne souhaitez pas ajouter ces données à votre environnement de production.
L’approche que vous utilisez pour ajouter des données dépend du service que vous utilisez. Par exemple :
- Pour ajouter des données à une base de données Azure SQL, vous devez exécuter un script, comme pour configurer un schéma.
- Pour insérer des données dans une base de données Azure Cosmos DB, vous devez accéder à l’API de son plan de données, ce qui peut nécessiter l’écriture de code dans un script personnalisé.
- Pour charger des objets blob dans un conteneur d’objets blob de Stockage Azure, vous pouvez utiliser divers outils à partir des scripts de pipeline, notamment l’application de ligne de commande AzCopy, Azure PowerShell ou Azure CLI. Chacun de ces outils comprend comment s’authentifier auprès du Stockage Azure en votre nom et comment se connecter à l’API de plan de données pour charger des objets blob.
Idempotence
L’une des caractéristiques des pipelines de déploiement et de l’infrastructure en tant que code est que vous devriez être en mesure de redéployer de façon répétée sans effets secondaires indésirables. Par exemple, quand vous redéployez un fichier Bicep précédemment déployé, Azure Resource Manager compare le fichier que vous avez soumis avec l’état existant de vos ressources Azure. En l’absence de modifications, Resource Manager ne fait rien. La capacité à réexécuter une opération de façon répétée est appelée idempotence. Une bonne pratique consiste à vous assurer que vos scripts et autres étapes de pipeline sont idempotents.
L’idempotence est particulièrement importante lorsque vous interagissez avec des services de données, car ils conservent l’état. Imaginez que vous insériez un exemple d’utilisateur dans une table de base de données à partir de votre pipeline. Si vous n’êtes pas vigilant, chaque fois que vous exécutez votre pipeline, un nouvel exemple d’utilisateur est créé. Ce résultat n’est probablement pas celui que vous voulez.
Lorsque vous appliquez des schémas à une base de données Azure SQL, vous pouvez utiliser un package de données, également appelé fichier DACPAC, pour déployer votre schéma. Votre pipeline génère un fichier DACPAC à partir du code source et crée un artefact de pipeline, comme avec une application. Ensuite, la phase de déploiement dans votre pipeline publie le fichier DACPAC dans la base de données :
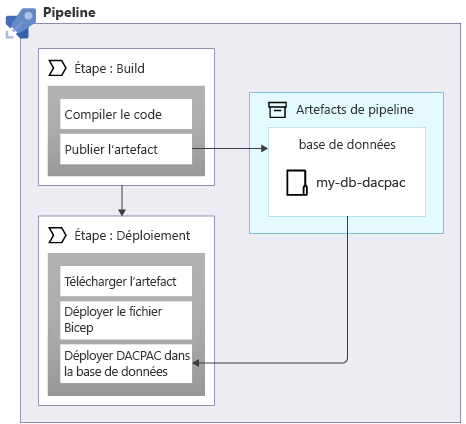
Quand un fichier DACPAC est déployé, il se comporte de manière idempotente. Il compare l’état cible de votre base de données à l’état défini dans le package. Dans de nombreux cas, cela signifie que vous n’avez pas besoin d’écrire des scripts qui suivent le principe de l’idempotence, car les outils le gèrent pour vous. Certains outils pour Azure Cosmos DB et le stockage Azure se comportent également correctement.
Cependant, quand vous créez des exemples de données dans une base de données Azure SQL ou un autre service de stockage qui ne fonctionne pas automatiquement de manière idempotente, c’est une bonne pratique que d’écrire votre script pour qu’il crée les données seulement si elles n’existent pas encore.
Il est également important de considérer si vous pouvez être amené à restaurer les déploiements, par exemple en réexécutant une version antérieure d’un pipeline de déploiement. L’annulation des modifications apportées à vos données peut s’avérer compliquée : réfléchissez donc avec attention à la façon dont votre solution fonctionne si vous devez revenir en arrière.
Sécurité du réseau
Parfois, vous pouvez appliquer des restrictions réseau à certaines de vos ressources Azure. Ces restrictions peuvent appliquer des règles sur les demandes adressées au plan de données d’une ressource, par exemple :
- Ce serveur de base de données est accessible uniquement à partir d’une liste spécifiée d’adresses IP.
- Ce compte de stockage est accessible uniquement à partir de ressources déployées au sein d’un réseau virtuel spécifique.
Les restrictions réseau sont courantes avec les bases de données, car il n’est pas nécessaire d’utiliser Internet pour se connecter à un serveur de base de données.
Toutefois, en raison des restrictions réseau, vos pipelines de déploiement peuvent avoir des difficultés à fonctionner avec les plans de données de vos ressources. Quand vous utilisez un agent de pipeline hébergé par Microsoft, son adresse IP ne peut pas être facilement connue à l’avance et peut être affectée à partir d’un grand pool d’adresses IP. En outre, les agents de pipeline hébergés par Microsoft ne peuvent pas être connectés à vos propres réseaux virtuels.
Certaines tâches d’Azure Pipelines qui vous aident à effectuer des opérations de plan de données peuvent contourner ces problèmes. Par exemple, la tâche SqlAzureDacpacDeployment :
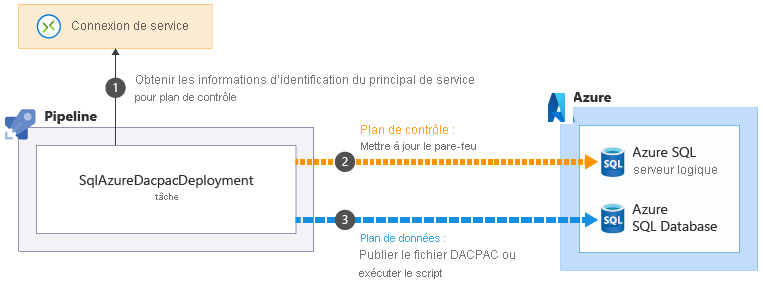
Quand vous utilisez la tâche SqlAzureDacpacDeployment pour travailler avec une base de données ou un serveur logique Azure SQL, elle utilise le principal de service de votre pipeline pour se connecter au plan de contrôle pour le serveur logique Azure SQL. Elle met à jour le pare-feu pour permettre à l’agent de pipeline d’accéder au serveur à partir de son adresse IP
de votre pipeline pour se connecter au plan de contrôle pour le serveur logique Azure SQL. Elle met à jour le pare-feu pour permettre à l’agent de pipeline d’accéder au serveur à partir de son adresse IP . Ensuite, elle peut soumettre avec succès le fichier ou le script DACPAC à exécuter
. Ensuite, elle peut soumettre avec succès le fichier ou le script DACPAC à exécuter . La tâche supprime ensuite automatiquement la règle de pare-feu quand elle se termine.
. La tâche supprime ensuite automatiquement la règle de pare-feu quand elle se termine.
Dans d’autres situations, il n’est pas possible de créer ces types d’exceptions. Dans ce cas, envisagez d’utiliser un agent de pipeline auto-hébergé, qui s’exécute sur une machine virtuelle ou une autre ressource de calcul que vous contrôlez. Vous pouvez ensuite configurer cet agent selon vos besoins. Il peut utiliser une adresse IP connue ou être connecté à votre propre réseau virtuel. Nous n’aborderons pas les agents auto-hébergés dans ce module, mais nous vous proposons des liens vers des informations supplémentaires dans la page Résumé, à la fin du module.
Votre pipeline de déploiement
Dans l’exercice suivant, vous allez mettre à jour votre pipeline de déploiement pour ajouter de nouveaux travaux afin de créer les composants de base de données de votre site web, déployer la base de données et y ajouter des données initiales :
