Optimiser les performances d’une solution Recherche Azure AI
Les performances de vos solutions de recherche peuvent être affectées par la taille et la complexité de vos index. Vous devez également savoir comment écrire des requêtes efficaces pour lancer des recherches et choisir le niveau de service approprié.
Ici, vous allez explorer toutes ces dimensions et voir les mesures que vous pouvez prendre pour améliorer les performances de votre solution de recherche.
Mesurer vos performances de recherche actuelles
Pour optimiser votre service de recherche, vous devez d’abord connaître son niveau de performance actuel. Créez un point de référence qui vous permettra de valider les améliorations en termes de performances et de détecter toute dégradation au fil du temps.
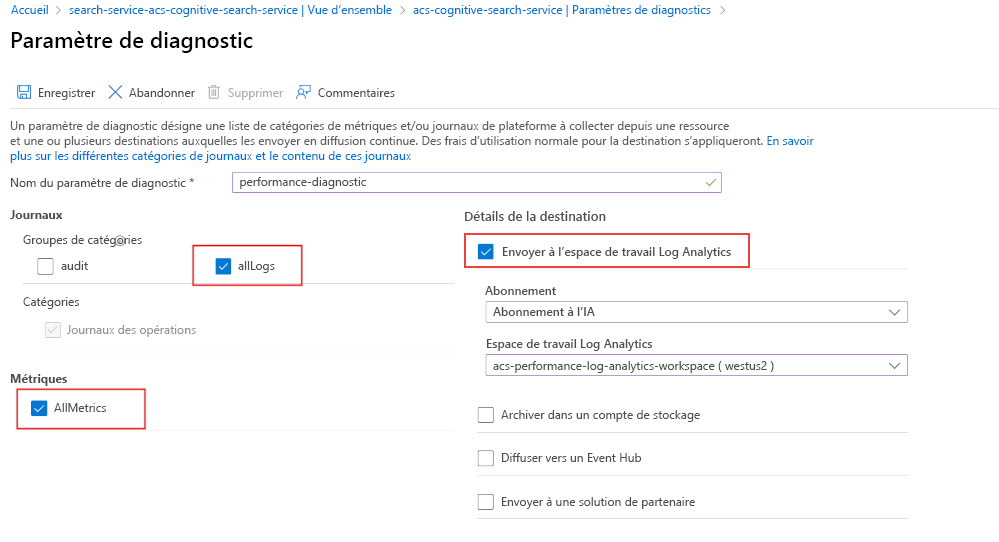
Pour commencer, activez la journalisation des diagnostics avec Log Analytics :
- Dans le portail Azure, sélectionnez Paramètres de diagnostic.
- Sélectionnez + Ajouter des paramètres de diagnostic.

- Donnez un nom à votre paramètre de diagnostic.
- Sélectionnez allLogs et AllMetrics.
- Sélectionnez Envoyer à l’espace de travail Log Analytics.
- Choisissez ou créez un espace de travail Log Analytics.
Il est important de capturer ces informations de diagnostic au niveau du service de recherche. En effet, vos utilisateurs finaux ou applications peuvent constater des problèmes de performances à différents endroits.

Si vous pouvez prouver que votre service de recherche fonctionne bien, vous pouvez l’éliminer des facteurs possibles si vous rencontrez des problèmes de performances.
Vérifier si votre service de recherche est limité
Les recherches et les index Recherche Azure AI peuvent être limités. Si vos utilisateurs ou vos applications voient leurs recherches limitées, cela est capturé dans Log Analytics avec une réponse HTTP 503. Si vos index sont limités, ils apparaissent sous la forme de réponses HTTP 207.
Cette requête que vous pouvez exécuter sur les journaux de votre service de recherche vous indique si votre service est limité.

Dans le portail Azure, sous Monitoring, sélectionnez Journaux. Sous l’onglet Nouvelle requête 1, vous utiliserez cette requête :
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Vous exécuterez la commande pour afficher un graphique à barres des réponses HTTP de votre service de recherche. Dans ce qui précède, vous pouvez voir plusieurs réponses 503.
Vérifier les performances de requêtes individuelles
Le meilleur moyen de tester les performances de requêtes individuelles consiste à utiliser un outil client comme Postman. Vous pouvez utiliser n’importe quel outil qui vous montre les en-têtes dans la réponse à une requête. Recherche Azure AI retourne toujours une valeur de temps écoulé (« elapsed-time »), qui correspond au temps nécessaire au service pour terminer la requête.

Si vous souhaitez savoir combien de temps il faudrait pour envoyer et recevoir la réponse du client, soustrayez le temps écoulé de l’aller-retour total. Dans ce qui précède, nous avons 125 ms - 21 ms, ce qui nous donne 104 ms.
Optimiser la taille et le schéma de votre index
Les performances de vos requêtes de recherche sont directement liées à la taille et à la complexité de vos index. Plus vos index sont petits et optimisés, plus Recherche Azure AI peut répondre rapidement aux requêtes. Voici quelques conseils qui pourront vous aider si vous rencontrez des problèmes de performances au niveau de requêtes individuelles.
Si vous ne faites pas attention, les index peuvent croître au fil du temps. Vous devez confirmer la pertinence de tous les documents de votre index et déterminer s’il doivent toujours faire l’objet de recherches.
Si vous ne pouvez supprimer aucun document, pouvez-vous réduire la complexité du schéma ? Les mêmes champs doivent-ils toujours faire l’objet de recherches ? Avez-vous encore besoin de tous les ensembles de compétences sélectionnés au moment de la création de l’index ?

Songez à passer en revue tous les attributs que vous avez activés sur chaque champ. Par exemple, la prise en charge des filtres, des facettes et du tri peut quadrupler le stockage nécessaire pour prendre en charge votre index.
Remarque
Le fait d’avoir trop d’attributs sur un champ limite ses capacités. Par exemple, dans un champ prenant en charge les facettes, les filtres et les recherches, vous ne pouvez stocker que 16 Ko. En revanche, un champ pouvant faire l’objet de recherches peut contenir jusqu’à 16 Mo de texte.
Si votre index a été optimisé, mais que les performances ne sont toujours pas au niveau désiré, vous pouvez effectuer un scale-up ou un scale-out de votre service de recherche.
Améliorer les performances de vos requêtes
Si vous savez comment fonctionne le service de recherche, vous pouvez ajuster vos requêtes pour améliorer considérablement les performances. Utilisez cette check-list pour écrire de meilleures requêtes :
- Spécifiez uniquement les champs dans lesquels vous souhaitez faire des recherches avec le paramètre searchFields. En effet, plus de champs nécessitent un traitement supplémentaire.
- Retournez le plus petit nombre de champs que vous devez afficher sur votre page des résultats de la recherche. Le retour de données supplémentaires prend plus de temps.
- Essayez d’éviter les termes de recherche partiels comme la recherche par préfixe ou les expressions régulières. Ces types de recherches sont plus coûteux en termes de calcul.
- Évitez d’utiliser des valeurs d’évitement élevées. Cela oblige le moteur de recherche à récupérer et à classer de plus grands volumes de données.
- Limitez l’utilisation de champs prenant en charge les facettes et les filtres à des données de cardinalité faible.
- Utilisez des fonctions de recherche au lieu de valeurs individuelles dans les critères de filtre. Par exemple, vous pouvez utiliser
search.in(userid, '123,143,563,121',',')au lieu de$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121.
Si vous avez appliqué tout ce qui précède et que certaines requêtes individuelles ne donnent toujours pas de bons résultats, vous pouvez effectuer un scale-out de votre index. Selon le niveau de service que vous avez utilisé pour créer votre solution de recherche, vous pouvez ajouter jusqu’à 12 partitions. Les partitions sont le stockage physique où réside votre index. Par défaut, tous les nouveaux index de recherche sont créés avec une seule partition. Si vous ajoutez d’autres partitions, l’index est stocké sur celles-ci. Par exemple, si votre index occupe 200 Go et que vous avez quatre partitions, chaque partition contient 50 Go de votre index.
L’ajout de partitions supplémentaires peut améliorer les performances, car le moteur de recherche peut fonctionner en parallèle dans chaque partition. Les meilleures améliorations sont observées pour les requêtes qui retournent un grand nombre de documents et celles qui utilisent des facettes pour fournir des totaux sur un grand nombre de documents. Ce facteur montre à quel point le scoring de la pertinence des documents est coûteux en termes de calcul.
Utiliser le meilleur niveau de service pour vos besoins de recherche
Vous avez vu que vous pouvez effectuer un scale-out des niveaux de service en ajoutant d’autres partitions. Vous pouvez effectuer un scale-out avec des réplicas si vous devez effectuer une mise à l’échelle en raison d’une augmentation de la charge. Vous pouvez également effectuer un scale-up de votre service de recherche en utilisant un niveau supérieur.

Les deux index de recherche ci-dessus ont une taille de 200 Go. Le niveau S1 utilise huit partitions et le niveau S2 n’en a que deux. Les deux ont deux réplicas et coûtent environ la même chose. Pour choisir le meilleur niveau pour votre solution de recherche, vous devez connaître la taille totale approximative du stockage dont vous aurez besoin. Le plus grand index actuellement pris en charge compte 12 partitions dans le niveau L2, soit 24 To au total.
| Niveau | Type | Stockage | Réplicas | Partitions |
|---|---|---|---|---|
| F | Gratuit | 50 Mo | 1 | 1 |
| B | De base | 2 Go | 3 | 1 |
| S1 | standard | 25 Go/Partition | 12 | 12 |
| S2 | standard | 100 Go/Partition | 12 | 12 |
| S3 | standard | 200 Go/Partition | 12 | 12 |
| S3HD | Haute densité | 200 Go/Partition | 12 | 3 |
| L1 | À stockage optimisé | 1 To/Partition | 12 | 12 |
| L2 | À stockage optimisé | 2 To/Partition | 12 | 12 |
Selon vous, lequel des deux niveaux ci-dessus dans l’exemple ci-dessus offre les meilleures performances ? Vous avez vu que le scale-out offre des avantages en termes de performances en raison du parallélisme. Toutefois, les niveaux supérieurs sont également fournis avec un stockage Premium, des ressources de calcul plus puissantes et plus de mémoire. La deuxième option offre une infrastructure plus puissante et prend en charge la croissance future de l’index. Malheureusement, le niveau qui fonctionne le mieux dépend de la taille et de la complexité de votre index et des requêtes que vous écrivez pour lancer des recherches. Le meilleur niveau peut donc être l’un ou l’autre.
Los de la planification de la croissance future de votre solution de recherche, vous devez envisager les unités de recherche. Une unité de recherche (SU) est le produit des réplicas et des partitions. Cela signifie que le niveau S1 ci-dessus utilise 16 SU et que le niveau S2 n’utilise que 4 SU. Les coûts sont similaires, car les niveaux supérieurs facturent plus par SU.
Pensez à la nécessité de mettre à l’échelle votre solution de recherche en raison de la charge accrue. L’ajout d’un autre réplica aux deux niveaux fait passer le niveau S1 à 24 SU, mais le niveau S2 ne passe qu’à 6 SU.