Présentation
Le Machine Learning transforme la façon dont les entreprises fonctionnent en permettant une prise de décision basée sur les données et l'automatisation. Toutefois, le développement d’un modèle Machine Learning n’est qu’un début. Le véritable défi réside dans le déploiement de ces modèles dans des environnements de production où ils peuvent fournir des insights et des prédictions en temps réel.
Azure Databricks est une plateforme polyvalente qui combine l’ingénierie des données et la science des données. Elle fournit une plateforme d’analytique unifiée qui simplifie le processus de création, d’apprentissage et de déploiement de modèles Machine Learning à grande échelle. Avec son environnement collaboratif, les scientifiques des données et les ingénieurs peuvent collaborer pour créer des solutions Machine Learning efficaces.
Pour utiliser pleinement les fonctionnalités d’Azure Databricks, il est essentiel de comprendre le flux de travail Machine Learning complet.
Explorer le flux de travail Machine Learning
Le flux de travail Machine Learning est un processus complet qui englobe plusieurs tâches critiques, chacune jouant un rôle essentiel dans le développement et le déploiement de modèles Machine Learning efficaces. Le flux de travail Machine Learning inclut les tâches suivantes :
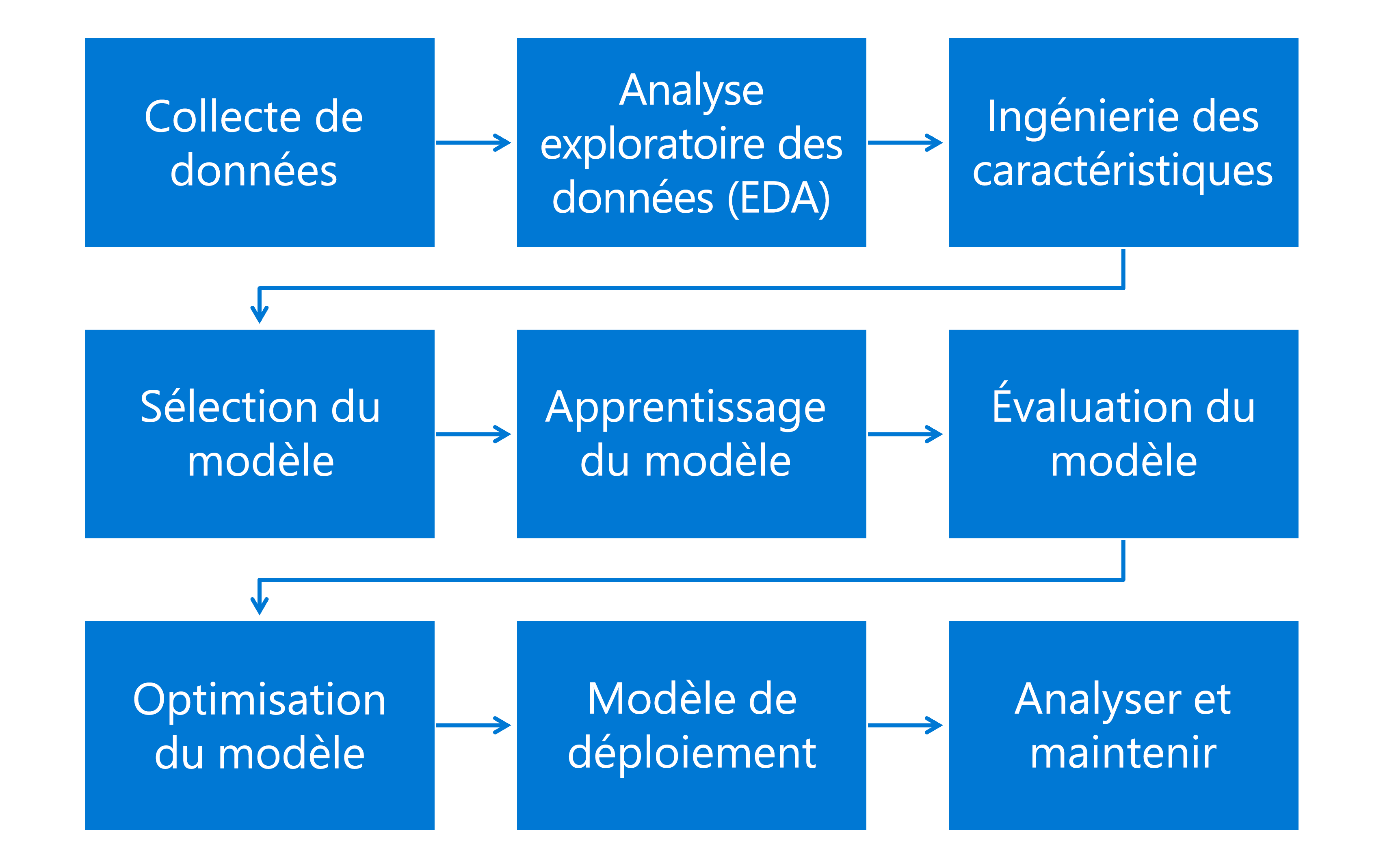
- Collecte de données : les données peuvent être des nombres, des images ou du texte, selon ce que la machine doit apprendre.
- Analyse exploratoire des données : analyse des données pour résumer ses principales caractéristiques et découvrir les modèles.
- Ingénierie de caractéristiques : création de nouvelles fonctionnalités ou modification des fonctionnalités existantes pour améliorer les performances du modèle.
- Sélection du modèle : le modèle est une formule mathématique ou un algorithme qui effectue des prédictions en recherchant des modèles dans les données.
- Apprentissage du modèle : l’algorithme du Machine Learning utilise des données pour apprendre les modèles qui connectent l’entrée (fonctionnalités) à la sortie (cible). Le modèle ajuste ses paramètres pour réduire la différence entre ses prédictions et les résultats réels dans les données d’apprentissage.
- Évaluation du modèle : les performances du modèle sont évaluées à l’aide d’un nouveau jeu de données appelé jeu de tests. Les métriques telles que la précision, le rappel et la zone sous la courbe ROC sont utilisées pour évaluer différents types de modèles.
- Optimisation du modèle : les paramètres et l’algorithme du modèle sont affinés pour améliorer sa précision et son efficacité.
- Modèle de déploiement : le modèle est déployé dans un environnement de production où il effectue des prédictions par lots ou en temps réel.
- Surveillance et maintien : la surveillance continue est essentielle pour garantir que le modèle reste efficace à mesure que de nouvelles données et des changements potentiels dans la distribution des données sous-jacentes se produisent.
Pour parcourir chaque phase du flux de travail Machine Learning et mettre les modèles en production, il est important d’utiliser les outils et technologies appropriés. Azure Databricks, ainsi que d’autres services Azure, propose un ensemble d’outils qui prennent en charge chaque étape de ce processus. De la collecte de données et de l’ingénierie des fonctionnalités au modèle de déploiement et à la surveillance, Azure fournit des outils qui permettent une intégration fluide et des flux de travail efficaces.
Examinons les outils qui vous aident à mettre vos flux de travail Machine Learning en production.