Définir l’apprentissage supervisé
Le processus d’entraînement d’un modèle peut être supervisé ou non supervisé. Notre objectif est de comparer ces approches, puis d’examiner plus en détail le processus d’apprentissage en mettant l’accent sur l’apprentissage supervisé. Il est bon de se rappeler tout au long de cette présentation que la seule différence entre l’apprentissage supervisé et l’apprentissage non supervisé est le fonctionnement de la fonction objectif.
Qu’est-ce que l’apprentissage non supervisé ?
Dans l’apprentissage non supervisé, nous entraînons un modèle pour résoudre un problème sans que nous connaissions la réponse correcte. En fait, l’apprentissage non supervisé est généralement utilisé pour les problèmes où il n’y a pas une réponse correcte, mais des solutions meilleures et des solutions moins bonnes.
Imaginons que nous voulons que notre modèle Machine Learning dessine des images réalistes de chiens de recherche en avalanche. Il n’y a pas un unique dessin « correct » à produire. Dès lors que l’image ressemble à un chien, nous sommes satisfaits. Mais si l’image produite est un chat, il s’agit d’une solution moins bonne.
Rappelez-vous que l’entraînement nécessite plusieurs composants :
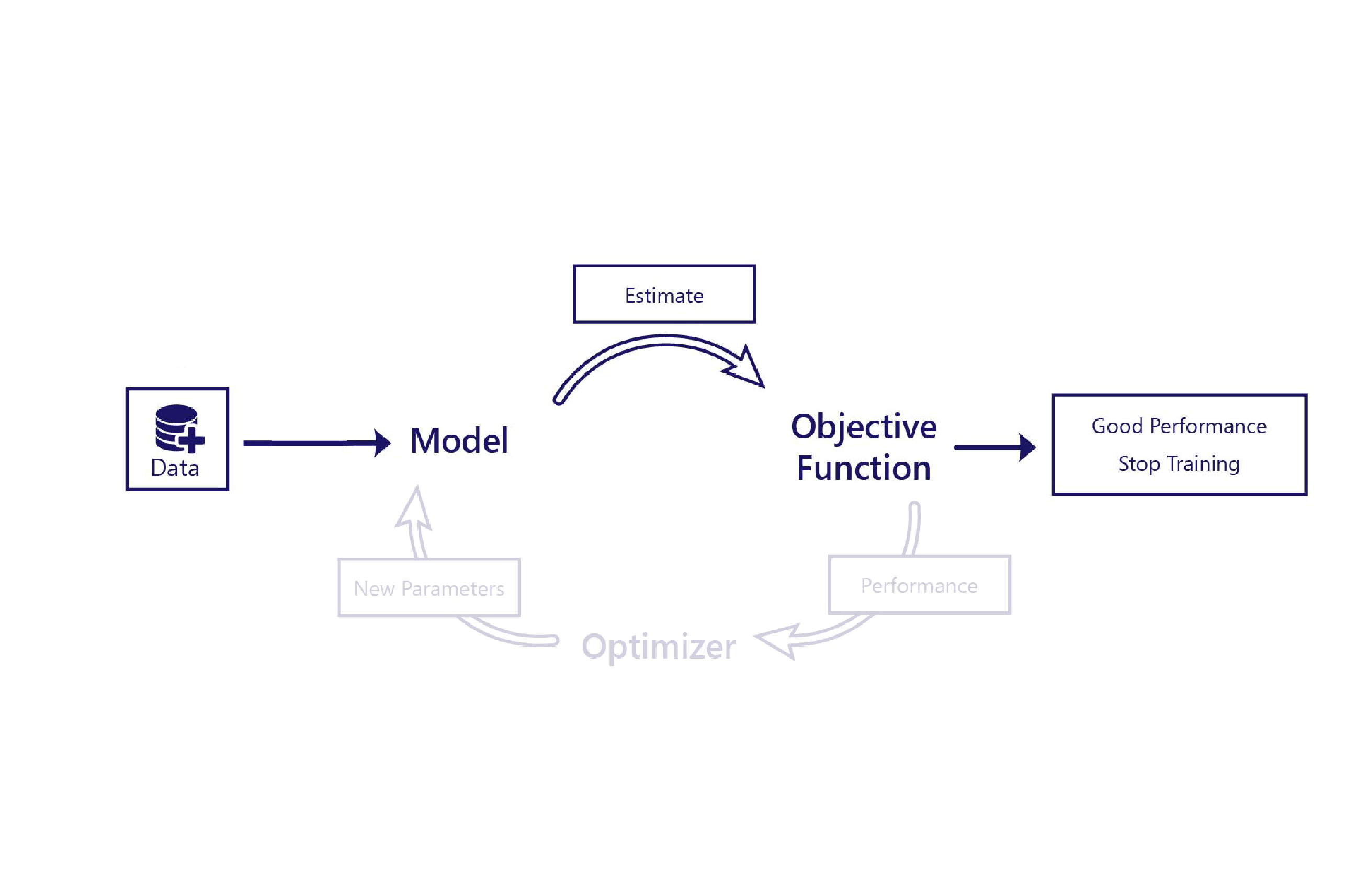
Dans l’apprentissage non supervisé, la fonction objectif établit son jugement exactement d’après l’estimation du modèle. Cela signifie que la fonction objectif doit souvent être relativement sophistiquée. Par exemple, la fonction objectif peut avoir besoin de contenir un « détecteur de chien » pour évaluer si les images que dessine le modèle sont réalistes. Les seules données dont nous avons besoin pour l’apprentissage non supervisé concernent les caractéristiques que nous fournissons au modèle.
Qu’est-ce que l’apprentissage supervisé ?
Considérez l’apprentissage supervisé comme un apprentissage par l’exemple. Dans l’apprentissage supervisé, nous évaluons les performances du modèle en comparant ses estimations à la réponse correcte. Même si nous pouvons avoir des fonctions d’objectif simples, nous avons besoin à la fois :
- De caractéristiques qui sont fournies en tant qu’entrées au modèle
- D’étiquettes, qui correspondent aux réponses correctes que nous voulons que le modèle soit capable de produire
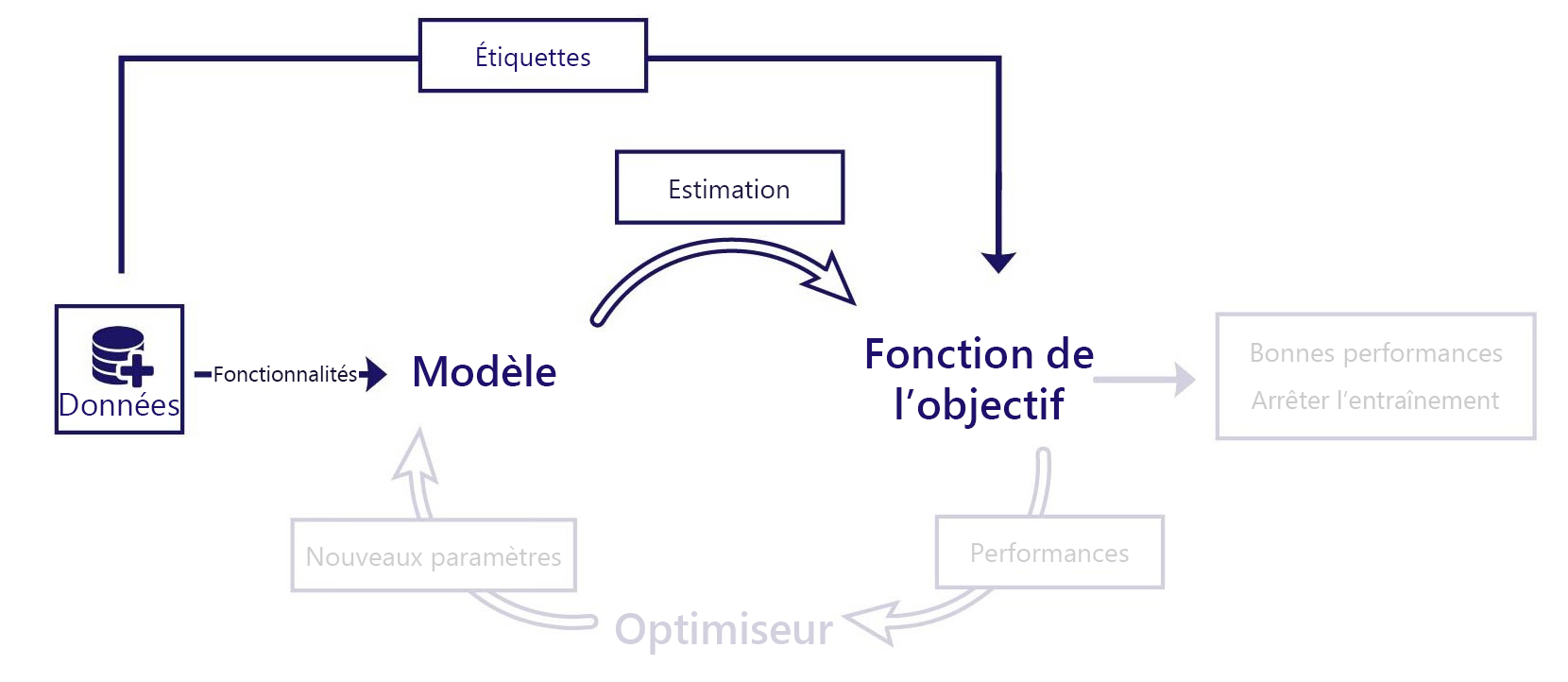
Par exemple, imaginons que vous voulez prédire quelle sera la température le 31 janvier d’une année donnée. Pour cette prédiction, nous avons besoin de données avec deux composants :
- Caractéristique : Date
- Étiquette : Température journalière (par exemple à partir d’enregistrements d’historique)
Dans le scénario, nous fournissons la caractéristique « date » au modèle. Le modèle prédit la température, et nous comparons ce résultat à la température « correcte » du jeu de données. La fonction objectif peut ensuite calculer dans quelle mesure le modèle a bien fonctionné et nous pouvons apporter des ajustements au modèle.
Les étiquettes sont destinées seulement à l’apprentissage
Il est important de se rappeler que, quelle que soit la façon dont les modèles sont entraînés, ils ne traitent que des caractéristiques. Au cours de l’apprentissage supervisé, la fonction objectif est le seul composant qui s’appuie sur l’accès aux étiquettes. Après l’entraînement, nous n’avons pas besoin d’étiquettes pour utiliser notre modèle.