Comprendre les grands modèles de langage
Un grand modèle de langage (LLM) est un type d’IA qui peut traiter et produire du texte en langage naturel. Il apprend à partir d’une grande quantité de données collectées à partir de sources telles que des livres, des articles, des pages web et des images pour découvrir des modèles et des règles de langage.
Quelle est leur grandeur ?
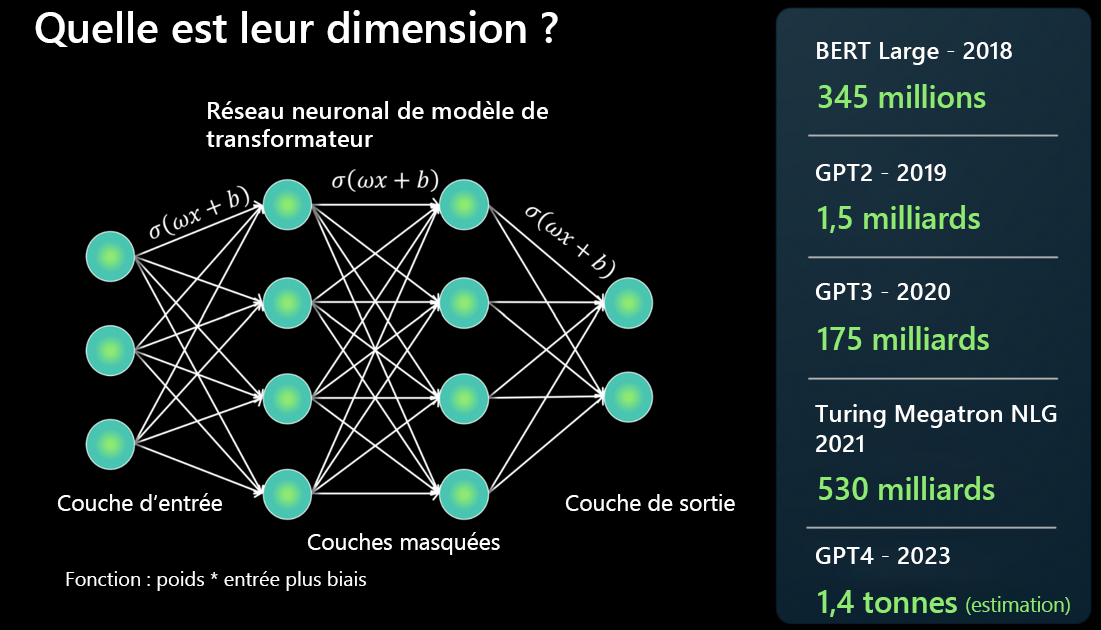
Un LLM est créé à l’aide d’une architecture de réseau neuronal. Il prend une entrée, décompose différents aspects du langage à l’aide de plusieurs couches masquées et produit au niveau de la couche de sortie.
On signale souvent que le dernier modèle fondamental est plus grand que le précédent, mais que cela signifie-t-il ? En bref, plus un modèle a de paramètres, plus il peut traiter, apprendre et générer des données.
Pour chaque connexion entre deux neurones de l’architecture de réseau neuronal, il existe une fonction : poids * entrée + biais. Ce réseau produit des valeurs numériques qui déterminent la façon dont le modèle traite le langage.
Les LLM sont en effet grands et leur taille augmente rapidement. Certains modèles pouvaient calculer des millions de paramètres en 2018. Mais aujourd’hui GPT-4 peut calculer des billions de paramètres.
Où les modèles fondamentaux s’intègrent-ils aux LLM ?
Un modèle fondamental fait référence à une instance ou version spécifique d’un LLM. Par exemple, GPT-3, GPT-4 ou Codex.
Les modèles fondamentaux sont formés et affinés sur un grand corpus de texte, ou de code s’il s’agit d’une instance du modèle Codex.
Un modèle fondamental prend des données d’apprentissage dans tous les formats différents et utilise une architecture de transformateur pour créer un modèle général. Les adaptions et spécialisations peuvent être créées pour effectuer certaines tâches via des invites ou des ajustements.
Comment un LLM diffère-t-il du traitement du langage naturel (NLP) plus traditionnel ?
Il existe quelques éléments qui séparent les NLP traditionnels des LLM.
| NLP traditionnel | Grands modèles de langage |
|---|---|
| Un modèle par fonctionnalité est nécessaire. | Un modèle unique est utilisé pour de nombreux cas d’usage en langage naturel. |
| Fournit un ensemble de données étiquetées pour former le modèle ML. | Utilise de nombreux téraoctets de données non étiquetées dans le modèle fondamental. |
| Décrit en langage naturel ce que vous souhaitez que le modèle fasse. | Hautement optimisé pour des cas d’usage spécifiques. |
Qu’est-ce qu’un LLM ne fait pas ?
Aussi important que de comprendre ce qu’un LLM peut faire, il faut également comprendre ce qu’il ne peut pas faire afin de choisir l’outil approprié pour le travail.
Comprendre la langue : Un LLM est un moteur prédictif qui extrait des modèles basés sur du texte préexistant pour produire plus de texte. Il ne comprend pas la langue ou les mathématiques.
Comprendre les faits : Un LLM n’a pas de modes distincts pour la récupération d’informations et l’écriture créative. Il prédit simplement le jeton le plus probable suivant.
Comprendre les manières, l’émotion ou l’éthique : Un LLM ne peut pas exposer d’anthropomorphisme ni comprendre l’éthique. La sortie d’un modèle fondamental est une combinaison de données de formation et d’invites.