Microsoft HPC Pack
Si vous avez besoin d’un haut niveau de contrôle de votre infrastructure haute performance ou gérer à la fois des machines virtuelles locales et cloud, envisagez d’utiliser le pack Microsoft HPC.
Dans votre société d’ingénierie, vous voulez migrer une infrastructure hautes performances à partir de centres de données locaux vers Azure. Étant donné que ces systèmes sont vitaux pour l’entreprise, vous voulez effectuer la migration de manière progressive. Vous devez vous assurer que vous pouvez rapidement répondre à la demande et gérer les machines virtuelles de manière flexible pendant la migration, quand il y a à la fois des machines virtuelles locales et cloud.
Ici, vous allez découvrir comment le pack HPC peut gérer l’infrastructure HPC.
Qu’est-ce que HPC Pack ?
Quand vous avez recherché des options pour l’organisation d’ingénierie, vous vous êtes penché sur les instances Azure Batch et Azure HPC. Mais qu’en est-il si vous souhaitez avoir un contrôle total sur la gestion et la planification de vos clusters de machines virtuelles ? Qu’en est-il si vous avez beaucoup investi dans l’infrastructure locale de votre centre de données ? HPC Pack met à votre disposition une série de programmes d’installation pour Windows qui vous permettent de configurer votre propre plan de contrôle et de gestion ainsi que des déploiements hautement flexibles de nœuds locaux et cloud. Contrairement à Batch, qui est exclusivement basé sur le cloud, HPC Pack offre la possibilité d’effectuer un déploiement local et sur le cloud. Ainsi, il peut s’étendre au cloud quand vos réserves locales sont insuffisantes.

HPC Pack est une version de la couche de contrôle de la gestion et de la planification Batch, qui vous permet d’assumer entièrement le contrôle et la responsabilité. Le déploiement d’HPC Pack nécessite Windows Server 2012 ou version ultérieure.
Planifier HPC Pack
En règle générale, vous devez préparer l’installation de HPC Pack en procédant à un examen complet des exigences. Vous avez besoin de SQL Server et d’un contrôleur Active Directory. Vous devez également planifier une topologie. Combien de nœuds principaux ou de contrôle et combien de nœuds Worker doit-il y avoir ? Avez-vous besoin d’étendre la configuration à Azure ? Dans ce cas, vous préprovisionnez des nœuds Azure dans le cadre du cluster. La taille des machines principales qui composent le plan de contrôle (nœuds principaux et de contrôle, SQL Server et contrôleur de domaine Active Directory) dépend de la taille de cluster projetée.
Quand vous installez HPC Pack, il affiche un planificateur de travaux avec prise en charge des travaux HPC et parallèles. Le planificateur apparaît dans l’interface de passage de messages Microsoft. HPC Pack étant hautement intégré à Windows, vous pouvez utiliser Visual Studio pour le débogage parallèle. Vous pouvez voir tous les événements de l’application, du réseau et du système d’exploitation à partir des nœuds de calcul du cluster dans un affichage unique de débogueurs.
HPC Pack offre également un planificateur de travaux avancé. Vous pouvez rapidement effectuer un déploiement sur des nœuds Linux et sur des nœuds Azure, mêmes sur des nœuds qui ne sont pas exclusivement dédiés à HPC Pack. Cela signifie que vous pouvez utiliser une capacité de rechange au sein de votre centre de données. HPC Pack offre un moyen idéal d’exploiter les investissements existants en matière d’infrastructure et de maintenir un contrôle plus discret sur la manière dont le travail est divisé par rapport à Batch.
Utiliser un mélange de technologies
Les options que vous envisagez dans ce module ne sont pas mutuellement exclusives. Vous pouvez utiliser les machines virtuelles de la série H, que vous avez examinées dans la dernière unité, en tant que nœuds Azure possibles dans une configuration HPC. Bien que vous vous soyez concentré sur des cas d’usage mettant en évidence les différences par rapport à Batch, HPC Pack est flexible. Il autorise les déploiements exclusivement locaux et les déploiements exclusivement basés sur le cloud. Cette flexibilité est utile quand vous souhaitez un contrôle plus précis que celui offert par Batch.
Déploiement et gestion des systèmes HPC
Orchestration des systèmes HPC
L’un des concepts clés du cloud computing est l’orchestration. Il s’agit de superviser le déploiement, l’exécution et le monitoring de tous les composants d’une application dans le cluster.
En outre, un orchestrateur peut effectuer d’autres tâches telles que la réparation (gérer les erreurs), la mise à l’échelle et la journalisation. Les orchestrateurs, comme les bien connus Kubernetes ou Mesos, peuvent accéder directement aux ressources de cluster cloud par virtualisation.
Déploiement des systèmes HPC
Les déploiements HPC dans Azure peuvent varier selon vos besoins de charge de travail et votre budget spécifiques. Chaque déploiement comporte des composants standard, dont ceux-ci :
- Azure Resource Manager : permet le déploiement d’applications sur des clusters en utilisant des fichiers de script ou des modèles.
- Nœud principal HPC : permet de planifier des travaux et des charges de travail sur des nœuds Worker. C’est une machine virtuelle utilisée pour gérer les clusters HPC.
- Réseau virtuel : permet de créer un réseau isolé de clusters et de stockage via des connexions sécurisées avec ExpressRoute ou un VPN IPsec. Vous pouvez intégrer des serveurs DNS et des adresses IP établis dans votre réseau et contrôler avec précision le trafic entre les sous-réseaux.
- Virtual Machine Scale Sets : permet le provisionnement de machines virtuelles de clusters et inclut des fonctionnalités pour la mise à l’échelle automatique, les déploiements multizones et l’équilibrage de charge. Vous pouvez utiliser des groupes de machines virtuelles identiques pour exécuter plusieurs bases de données, y compris MongoDB, Cassandra et Hadoop.
- Stockage : permet de monter des clusters de stockage persistant sous la forme de stockage Blob, sur disque, de fichiers, hybride ou data lake.
Gestion des déploiements Azure HPC
Azure propose quelques services natifs pour vous aider à gérer vos déploiements HPC. Ces outils permettent une gestion flexible, et facilitent la planification des charges de travail dans Azure et dans les ressources hybrides.
- Microsoft HPC Pack : ensemble d’utilitaires que vous pouvez utiliser pour configurer et gérer les clusters de machines virtuelles, superviser les opérations et planifier les charges de travail. HPC Pack inclut des fonctionnalités utiles pour migrer les charges de travail locales ou continuer à utiliser un déploiement hybride. L’utilitaire ne provisionne pas et ne gère pas les machines virtuelles ou l’infrastructure réseau à votre place.
- Azure CycleCloud : interface pour le planificateur de votre choix. Vous pouvez utiliser Azure CycleCloud avec une gamme d’options natives et tierces, comme HPC Pack, Grid Engine, Slurm et Symphony. CycleCloud vous permet de gérer et d’orchestrer les charges de travail, de définir des contrôles d’accès avec Active Directory et de personnaliser les stratégies de cluster.
- Azure Batch : outil managé que vous pouvez utiliser pour mettre à l’échelle les déploiements automatiquement et définir des stratégies de planification des travaux. Le service Azure Batch gère le provisionnement, l’attribution, les runtimes et le monitoring de vos charges de travail. Pour l’utiliser, il vous suffit de charger vos charges de travail et de configurer votre pool de machines virtuelles.
Les charges de travail Azure HPC offrent des capacités de machine learning, de visualisation et de rendu qui, réunies, renforcent les applications dans le secteur des semi-conducteurs. Il permet une intégration cloud transparente et résiliente des charges de travail pétrole et gaz, ainsi que la conception de semi-conducteurs et le séquençage génomique dans le cloud.
Bonnes pratiques pour les déploiements Azure HPC
Les bonnes pratiques suivantes peuvent vous aider à obtenir les performances attendues et à en retirer de la valeur.
Distribuer les déploiements entre les services cloud : la distribution de déploiements à grande échelle entre plusieurs services cloud peut vous aider à éviter les limitations engendrées par la surcharge ou l’utilisation d’un seul service. En divisant votre déploiement en segments plus petits, vous pouvez :
- Arrêter les instances inactives après la fin des travaux sans interrompre les autres processus
- Démarrer et arrêter les clusters de nœuds de manière flexible
- Trouver plus facilement des nœuds disponibles dans vos clusters
- Utiliser plusieurs centres de données pour assurer la reprise d’activité après sinistre
Utiliser plusieurs comptes Stockage Azure pour les déploiements de nœuds : en plus de répartir les déploiements entre les services, il est recommandé d’associer plusieurs comptes de stockage à chaque déploiement. Cette pratique peut offrir de meilleures performances pour les déploiements à grande échelle, les applications restreintes par les opérations d’entrée et de sortie, et les applications personnalisées. Quand vous configurez vos comptes de stockage, vous devez prévoir un compte pour le provisionnement des nœuds et un autre pour le déplacement des données de travail ou de tâche afin de garantir une cohérence et une faible latence.
Augmenter les instances de nœuds proxy en fonction de la taille du déploiement : les nœuds proxy permettent la communication entre les nœuds principaux que vous exécutez localement et les nœuds Worker dans Azure. Ces nœuds sont attachés automatiquement lorsque vous déployez des nœuds Worker dans Azure. Si vous exécutez des travaux volumineux qui ont besoin de toutes les ressources fournies par les nœuds proxy, voire davantage, envisagez d’augmenter le nombre de nœuds exécutés. Il est particulièrement important d’augmenter leur nombre à mesure que votre déploiement grossit.
Vous connecter à votre nœud principal avec les utilitaires clients HPC :
les utilitaires clients HPC Pack sont la méthode recommandée pour la connexion à votre nœud principal, en particulier si vous exécutez des travaux volumineux. Vous pouvez installer ces utilitaires sur les stations de travail des utilisateurs et accéder à distance au nœud principal selon les besoins plutôt que d’utiliser les Services Bureau à distance. Ces utilitaires sont surtout utiles dans les scénarios où de nombreux utilisateurs se connectent en même temps.
Planification des tâches
La planification des tâches est un autre service HPC proposé. Vous pouvez utiliser le planificateur dans votre application pour distribuer le travail, ce qui permet l’exécution efficace des travaux par lots. Les objectifs principaux du planificateur peuvent être généralement classés comme suit :
- réduire le temps entre la soumission du travail et la fin du travail aucun travail ne doit rester dans la file d’attente pendant de longues périodes
- optimiser l’utilisation du processeur en particulier, diminuer les temps d’arrêt du processeur
- maximiser le débit des travaux avec une mise à l’échelle des travaux par unité de temps
Présentation de la planification des tâches
Les utilisateurs soumettent des travaux de traitement par lots non interactifs au planificateur. Le planificateur stocke les programmes de traitement par lots, évalue leurs besoins en ressources et leurs priorités et distribue les travaux aux nœuds de calcul appropriés. Ils constituent la majeure partie des clusters HPC (environ 98 %) consommant le plus d’énergie.
Contrairement aux nœuds de connexion et à leur utilisation interactive, les nœuds de calcul ne sont pas directement accessibles via ssh. Le planificateur sur le nœud de connexion agit comme une interface entre le nœud de calcul et l’utilisateur. L’utilisateur doit spécifier l’application dans un script de travail en fonction du temps et des ressources mémoire alloués.
Le script de travail soumis par le biais du planificateur ajoute le travail à une file d’attente de travaux. En fonction des ressources disponibles dont le travail a besoin, le planificateur détermine quand le travail va quitter la file d’attente et sur quels nœuds back-end (ou quelle partie de ces nœuds) le travail va s’exécuter.
L’utilisateur doit s’assurer que les ressources demandées entrent dans les limites du système. Par exemple :
- Le planificateur exécute le travail dans le temps alloué, même s’il demande plus de temps.
- Le travail reste bloqué dans la file d’attente s’il demande plus de mémoire que ce qui est disponible sur le système.
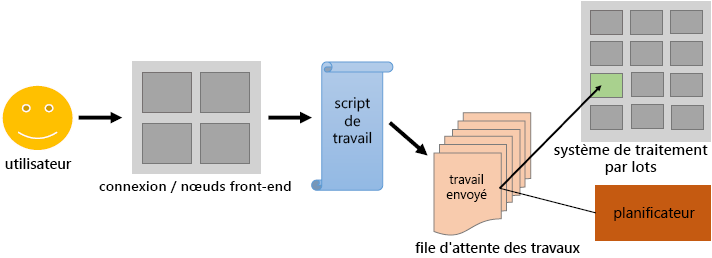
Illustration
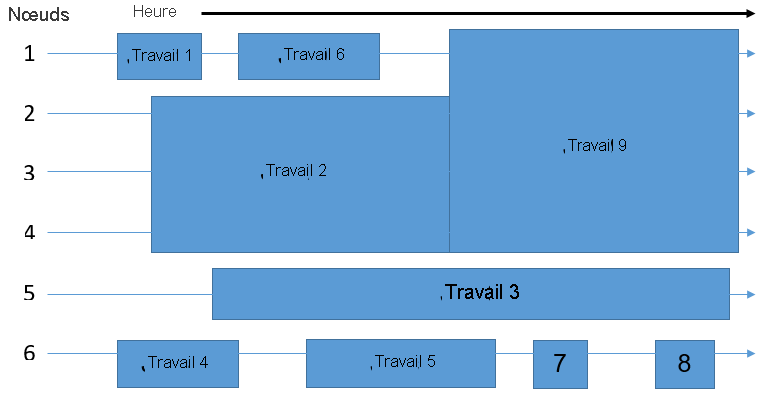
En supposant que le système de traitement par lots que vous utilisez se compose de six nœuds, le planificateur doit déterminer comment placer les neuf travaux dans la file d’attente sur les nœuds disponibles. L’objectif est d’éliminer les ressources gaspillées, représentées dans le diagramme suivant par des zones libres montrant des nœuds sans travail exécuté.
Par conséquent, les travaux ne sont pas forcément distribués aux différents nœuds dans le même ordre qu’ils ont été initialement mis en file d’attente. Le temps et le nombre de nœuds requis pour exécuter une tâche détermine l’espace d’un travail. Le planificateur joue un rôle de rotation multidimensionnel pour remplir uniformément les nœuds du cluster, en équilibrant les besoins en ressources de tous les travaux avec les ressources disponibles dans le cluster.
Algorithmes de planification
Les planificateurs peuvent utiliser deux stratégies de base pour déterminer le prochain travail à exécuter. Les planificateurs modernes n’appliquent pas strictement l’un ou l’autre de ces algorithmes : ils combinent les deux. De plus, un planificateur doit prendre en compte beaucoup d’autres aspects, par exemple la charge système actuelle.
First Come, First Serve (premier arrivé, premier servi) : les travaux sont exécutés dans l’ordre exact de leur ordre d’arrivée dans la file d’attente. L’avantage est que chaque travail est définitivement exécuté. Cependant, seul un petit nombre de travaux risquent de rester en attente trop longtemps par rapport à leur durée d’exécution réelle.
Le travail le plus court en premier : en fonction de la durée d’exécution déclarée dans le script de travail, le planificateur estime la durée d’exécution du travail. Les travaux sont classés dans l’ordre croissant de leur durée d’exécution. Les travaux courts démarrent après un bref délai d’attente, alors que les travaux longs (ou ceux déclarés comme tels) peuvent ne jamais réellement démarrer.
Renvoi : le planificateur applique le concept Premier arrivé, premier servi sans empêcher l’exécution des travaux durables. Le planificateur exécute le travail uniquement quand le premier travail dans la file d’attente peut être exécuté. Sinon, le planificateur parcourt toute la file d’attente pour voir s’il peut exécuter un autre travail sans que cela augmente le temps d’attente du premier travail dans la file d’attente. S’il trouve un travail à exécuter, le planificateur l’exécute immédiatement. Les travaux de petite taille restent généralement peu de temps dans la file d’attente.
Gestion de flux de travail
Traitement « pipeline » et automatisation des tâches
Les opérations répétées telles que l’utilisation d’outils et les exécutions de séquences de tâches de processus logiciel peuvent être organisées dans un pipeline. Leur automatisation contribue à rendre plus efficace l’utilisation globale des logiciels et des outils. Elle apporte des gains d’efficacité en accélérant l’exécution de la tâche proprement dite et en diminuant la charge de gestion pour le travailleur du savoir.
L’automatisation peut réduire le taux d’erreur d’un processus en éliminant la variance dans son exécution. Par ailleurs, le traitement pipeline et l’automatisation d’une tâche peuvent ouvrir la voie à d’autres innovations de processus comme la parallélisation et le déploiement cloud.
Outils de gestion des workflows
Utiliser Azure Batch
Utilisez Azure Batch pour exécuter des programmes de traitement par lots de calcul haute performance (HPC) en parallèle, efficacement et à grande échelle dans Azure. Azure Batch crée et gère un pool de nœuds de calcul (machines virtuelles), installe les applications que vous souhaitez exécuter, et planifie les travaux à exécuter sur les nœuds. Il n’y a aucun logiciel de planificateur de travail ou de cluster à installer, gérer ou mettre à l’échelle. Au lieu de cela, vous utilisez des outils et des API Batch, des scripts de ligne de commande, ou le portail Azure pour configurer, gérer et surveiller vos travaux.
Pour plus d’informations sur Azure Batch, y compris d’autres fonctionnalités et son utilisation, consultez Azure Batch.
Utiliser Azure CycleCloud
Azure CycleCloud est un outil adapté aux entreprises pour l’orchestration et la gestion des environnements HPC (High Performance Computing, calcul haute performance) sur Azure. Avec CycleCloud, les utilisateurs peuvent planifier une infrastructure pour les systèmes HPC, déployer des planificateurs HPC standard et mettre automatiquement à l’échelle l’infrastructure pour exécuter des travaux efficacement à n’importe quelle échelle. Avec CycleCloud, les utilisateurs peuvent créer différents types de systèmes de fichiers et les monter sur les nœuds d’un cluster de calcul en vue d’assurer le traitement des charges de travail HPC.
Pour plus d’informations sur Azure CycleCloud, consultez Azure CycleCloud.