Qu’est-ce qu’Azure HDInsight ?
Passons en revue les fonctionnalités et les utilisations de HDInsight. Cette vue d’ensemble vous permettra de déterminer si HDInsight répond aux besoins de votre organisation.
Qu’est-ce que le Big Data ?
Le terme Big Data décrit les grandes quantités de données structurées et non structurées que collectent les organisations. Ces données peuvent être extrêmement utiles pour les organisations. Plus précisément, si une organisation peut tirer des insights des données, elle est mieux à même de prendre des décisions. Ainsi, ces décisions peuvent aider une organisation à être plus performante. Par exemple, l’analyse du Big Data peut permettre à une organisation commerciale de reconnaître les habitudes des clients, ce qui peut entraîner une augmentation des ventes.
Définition d’Azure HDInsight
Azure HDInsight est un service d’analytique open source cloud complètement managé qui s’adresse aux entreprises. HDInsight vous permet de contrôler et de gérer votre Big Data. HDInsight :
Est une distribution cloud des composants Hadoop.
Permet de traiter de gros volumes de données de manière plus simple, plus rapide et plus économique.
Prend en charge l’utilisation de frameworks open source comme :
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Notes
Avec ces infrastructures, vous pouvez activer un large éventail de scénarios, tels que l’extraction, la transformation et le chargement (ETL) ; l’entreposage de données ; l’apprentissage automatique ; et IoT.
HDInsight offre plusieurs avantages pour les organisations qui manipulent du Big Data. Il est :
Open source : il vous permet de créer des clusters optimisés pour différents frameworks open source.
Fiable : il fournit un contrat SLA de bout en bout pour toutes les charges de travail de production.
Scalable : il vous permet de mettre à l’échelle les charges de travail de façon à répondre aux évolutions de la demande.
Conseil
En créant des clusters à la demande, vous pouvez réduire vos coûts. Vous ne payez que pour ce que vous utilisez.
Sécurisé : il vous permet de protéger vos ressources de données d’entreprise grâce à l’intégration des éléments suivants :
- Réseau virtuel Azure
- Technologies de chiffrement Azure
- Microsoft Entra ID
Conforme : il répond aux normes de conformité courantes au niveau industriel et gouvernemental.
Surveillé : il est compatible avec les journaux Azure Monitor pour fournir une interface unique. Supervisez tous les clusters en utilisant la même interface unique.
Comment HDInsight peut vous aider à manipuler du Big Data
Vous pouvez utiliser HDInsight pour de nombreux scénarios faisant appel au traitement de Big Data. Vos données peuvent être :
- Données historiques : ces données sont déjà collectées et stockées.
- Données en temps réel : ces données sont transmises directement en continu à partir de la source.
Les catégories suivantes récapitulent les scénarios de traitement pour ces données :
- Traitement par lots
- Entrepôt de données
- IoT
- Science des données
- Hybride
Examinons ces catégories plus en détail.
Traitement par lots
Les organisations utilisent des tâches de traitement par lots pour préparer le Big Data à une analyse plus poussée. En général, ce processus implique trois étapes :
- Lecture des fichiers de données sources à partir de sources de données hétérogènes.
- Traitement des données.
- Écriture des données dans un stockage scalable.
Notes
Ce processus est souvent appelé ETL.
Vous pouvez utiliser les données transformées pour l’entreposage de données ou la science des données.
Conseil
L’une des exigences significatives de l’ETL est le scale-out du calcul. Cela permet de traiter de grands volumes de données.
Entrepôt de données
Un entrepôt de données permet à une organisation de stocker du Big Data quelque part en attendant de l’analyser. L’entreposage de données permet d’effectuer les opérations suivantes :
- Stocker vos données.
- Préparer vos données en vue d’une analyse.
- Fournissez les données préparées dans un format structuré. Vous pouvez ensuite interroger les données avec des outils analytiques.
Le diagramme suivant illustre la façon dont Apache Hadoop sur HDInsight recueille et stocke les données de plusieurs sources. Apache Spark et Apache Hive préparent et analysent les données. Enfin, les données sont modélisées pour être utilisées avec des outils décisionnels. Power BI est utilisé pour la visualisation des données.
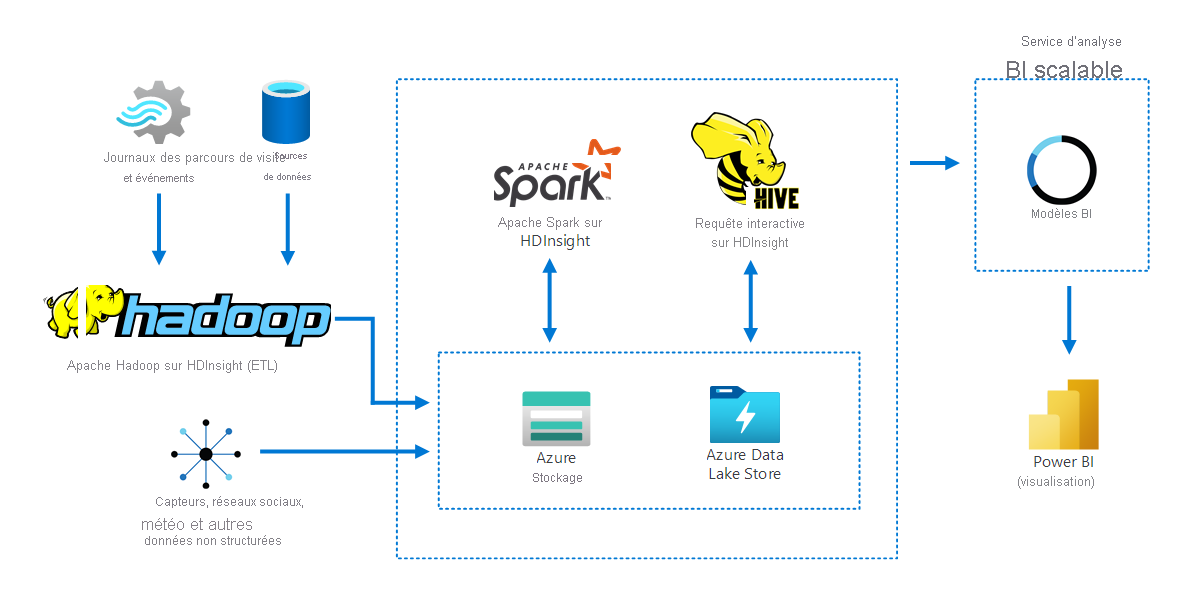
Les composants inclus dans ce scénario sont les suivants :
- Apache Spark est un framework de traitement parallèle. Il prend en charge le traitement en mémoire, qui aide à améliorer les performances des applications d’analytique de Big Data.
- Apache Hive dans HDInsight est un système d’entrepôt de données pour Apache Hadoop. Hive permet de synthétiser, d’interroger et d’analyser les données. Vous pouvez utiliser ces composants pour exécuter des requêtes sur des pétaoctets de données structurées et non structurées dans n’importe quel format.
Conseil
Les requêtes Hive sont écrites en HiveQL, langage de requête semblable à SQL.
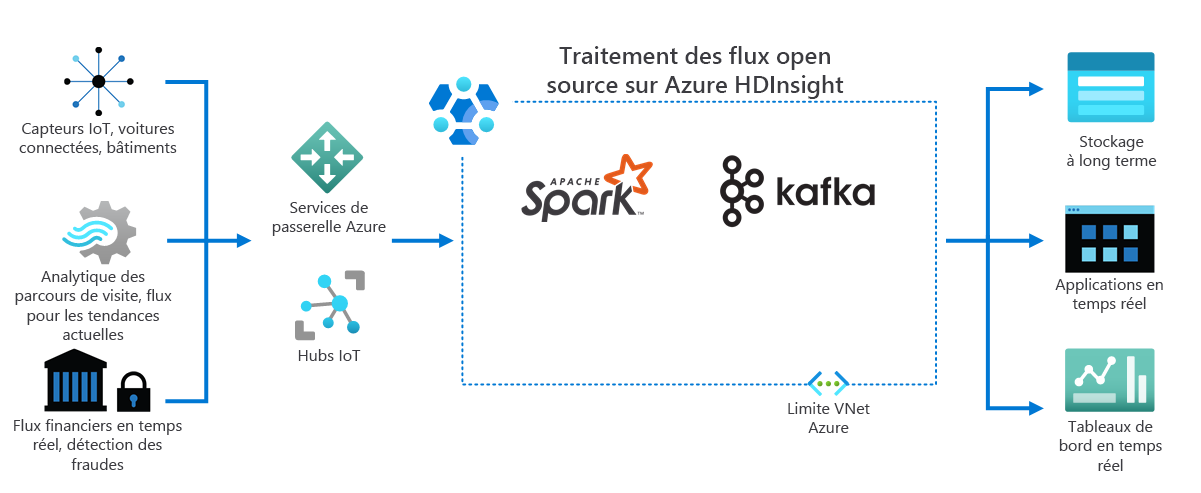
Internet des objets
Comme le montre le diagramme suivant, HDInsight traite les données de streaming reçues en temps réel à partir de différents appareils et capteurs. Dans cet exemple, plusieurs frameworks open source assurent le traitement des flux, notamment Apache Spark et Apache Kafka.
Les services de passerelle Azure et les hubs IoT dirigent les données de différentes sources vers ces frameworks. Les frameworks traitent ensuite les données et les passent aux éléments suivants :
- Un stockage à long terme.
- Applications en temps réel
- Tableaux de bord en temps réel
Science des données
Vous pouvez utiliser HDInsight pour effectuer des tâches courantes de science des données, telles que :
- Ingestion des données.
- Conception de fonctionnalités.
- Modélisation
- Évaluation du modèle
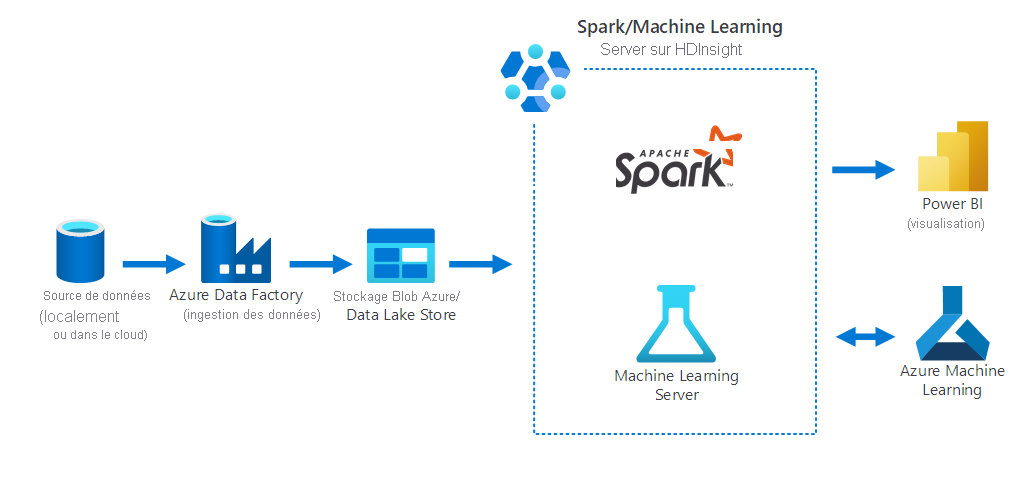
Le diagramme ci-dessous illustre un scénario de science des données, dans lequel sont effectuées les opérations suivantes :
- Les données sont collectées à partir d’une source de données locale avec Azure Data Factory.
- Les données ingérées sont ensuite stockées dans un stockage Azure (Stockage Blob Azure ou Data Lake Store).
- Azure Spark sur HDInsight traite et prépare les données pour Azure Machine Learning. Les données sont également visualisées avec Power BI.
Hybride
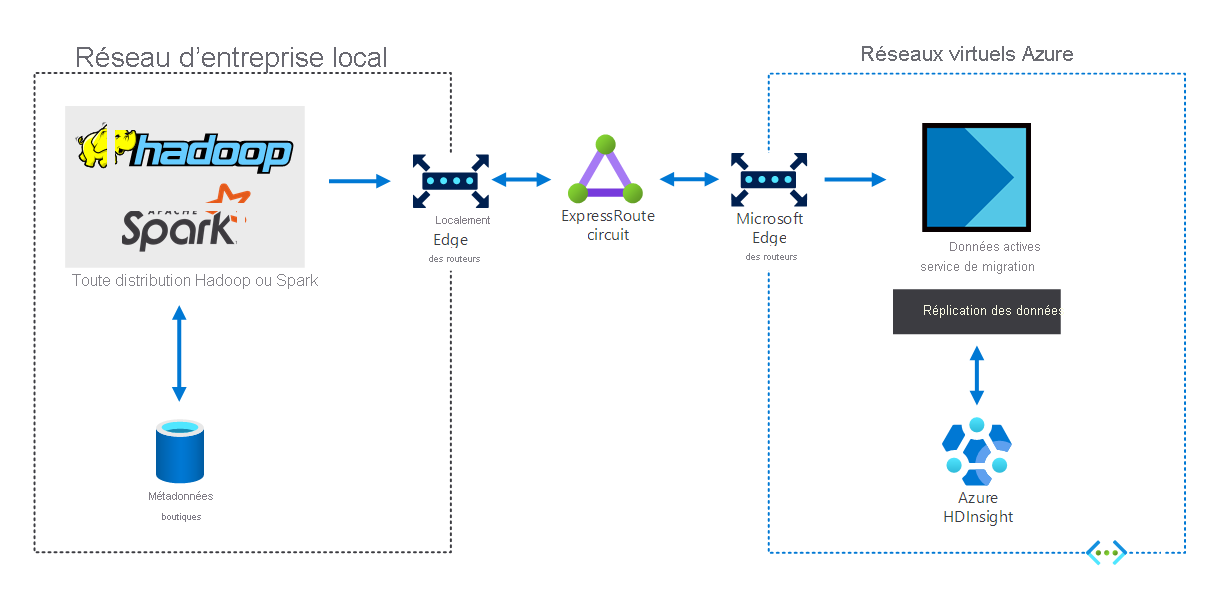
Les organisations qui ont une infrastructure de Big Data locale peuvent utiliser HDInsight pour s’étendre dans Azure. Elles bénéficient ainsi des avantages des fonctionnalités d’analytique avancée du cloud Azure. Le diagramme suivant illustre le scénario hybride, dans lequel :
- L’infrastructure de Big Data locale se compose de magasins de métadonnées et d’une distribution de Hadoop ou Spark sur des machines virtuelles locales.
- Un circuit Azure ExpressRoute connecte l’environnement réseau d’entreprise local aux réseaux virtuels Azure.
- Un outil de migration de données dynamique pour Azure réplique les données reçues du site local vers HDInsight.