Comment fonctionne Azure Data Factory
Ici, vous découvrez les composants et les systèmes interconnectés d’Azure Data Factory et leur fonctionnement. Ces connaissances doivent vous aider à déterminer comment utiliser au mieux Azure Data Factory pour répondre aux besoins de votre organisation.
Azure Data Factory est un ensemble de systèmes interconnectés qui s’associent pour fournir une plateforme d’analytique données de bout en bout. Dans cette unité, vous découvrez les fonctions d’Azure Data Factory suivantes :
- Se connecter et collecter
- Transformer et enrichir
- Intégration continue et livraison continue (CI/CD) puis publication
- Surveillance
Vous découvrez également les principaux composants d’Azure Data Factory suivants :
- Pipelines
- Activités
- Groupes de données
- Services liés
- Flux de données
- Runtimes d’intégration
Fonctions d’Azure Data Factory
Azure Data Factory est constitué de plusieurs fonctions qui s’associent pour fournir à vos ingénieurs données une plateforme complète d’analytique données.
Se connecter et collecter
La première partie du processus consiste à collecter les données nécessaires à partir des sources de données appropriées. Ces sources peuvent se trouver à différents emplacements, notamment des sources locales et dans le cloud. Ces données peuvent être :
- Données structurées
- Données non structurées
- Données semi-structurées
Ces données disparates peuvent aussi arriver à des vitesses et à des intervalles différents. Avec Azure Data Factory, vous pouvez utiliser l’activité de copie pour déplacer des données de différentes sources vers un magasin de données centralisé situé dans le cloud. Après avoir copié les données, vous utilisez d’autres systèmes pour les transformer et les analyser.
L’activité de copie effectue les étapes générales suivantes :
Lire les données dans le magasin de données source.
Effectuer les tâches de données suivantes :
- Sérialisation/désérialisation
- Compression/Décompression
- Mappage de colonnes
Notes
Il peut y avoir des tâches supplémentaires.
Écrire des données dans le magasin de données de destination (appelé récepteur).
Ce processus est récapitulé dans le schéma suivant :

Transformer et enrichir
Après avoir copié les données dans un emplacement informatique central, vous pouvez traiter et transformer les données selon vos besoins à l’aide de flux de données de mappage Azure Data Factory. Les flux de données vous permettent de créer des graphes de transformation de données qui s’exécutent sur Spark. Toutefois, vous n’avez pas besoin de connaître les clusters Spark ou la programmation Spark.
Conseil
Même si cela n’est pas nécessaire, vous pouvez programmer vos transformations manuellement. Dans ce cas, Azure Data Factory prend en charge les activités externes pour l’exécution de vos transformations.
CI/CD et publication
La prise en charge de CI/CD vous permet de développer et de livrer vos processus d’extraction, transformation et chargement (ETL) de manière incrémentielle avant la publication. Azure Data Factory fournit le CI/CD de vos pipelines de données avec :
- Azure DevOps
- GitHub
Notes
L’intégration continue consiste à tester automatiquement et, dès que possible, chaque modification apportée à votre codebase. La livraison continue vient après ce test et permet de pousser (push) les modifications vers un système de production ou de préproduction.
Une fois qu’Azure Data Factory a affiné les données brutes, vous pouvez charger les données dans le moteur d’analytique auquel vos utilisateurs professionnels peuvent accéder à partir de leurs outils décisionnels, notamment :
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Monitor
Après avoir créé et déployé votre pipeline d’intégration de données, il est important que vous puissiez surveiller vos activités et pipelines planifiés. La supervision vous permet d’effectuer le suivi des taux de réussite et d’échec. Azure Data Factory prend en charge la supervision des pipelines à l’aide d’une des méthodes suivantes :
- Azure Monitor
- API
- PowerShell
- Journaux d’activité Azure Monitor
- Les panneaux d’intégrité du portail Azure
Composants d’Azure Data Factory
Les composants d’Azure Data Factory sont décrits dans le tableau suivant :
| Composant | Description |
|---|---|
| Pipelines | Regroupement logique des activités qui effectuent une unité de travail spécifique. Ensemble, ces activités effectuent une tâche. L’avantage d’utiliser un pipeline est que vous pouvez gérer les activités comme un ensemble plutôt qu’une par une. |
| Activités | Étape de traitement au sein d’un pipeline. Azure Data Factory prend en charge trois types d’activités : les activités de déplacement des données, les activités de transformation des données et les activités de contrôle. |
| Groupes de données | Représentent les structures de données de vos magasins de données. Les jeux de données pointent vers (ou référencent) les données que vous souhaitez utiliser dans vos activités, comme des entrées ou des sorties. |
| Services liés | Définissent les informations de connexion qui sont nécessaires pour qu’Azure Data Factory puisse se connecter à des ressources externes, comme des sources de données. Azure Data Factory utilise des services liés à deux fins : représenter un magasin de données ou une ressource de calcul. |
| Flux de données | Permettent à vos ingénieurs données de développer la logique de transformation des données sans avoir à écrire de code. Les flux de données sont exécutés comme des activités dans les pipelines Azure Data Factory qui utilisent des clusters Apache Spark ayant fait l’objet d’un scale-out. |
| Runtimes d’intégration | Azure Data Factory utilise l’infrastructure de calcul pour fournir les fonctionnalités d’intégration de données suivantes dans différents environnements réseau : flux de données, déplacement des données, répartition des activités et exécution des packages SQL Server Integration Services (SSIS). Dans Azure Data Factory, un runtime d’intégration permet de créer une passerelle entre l’activité et les services liés. |
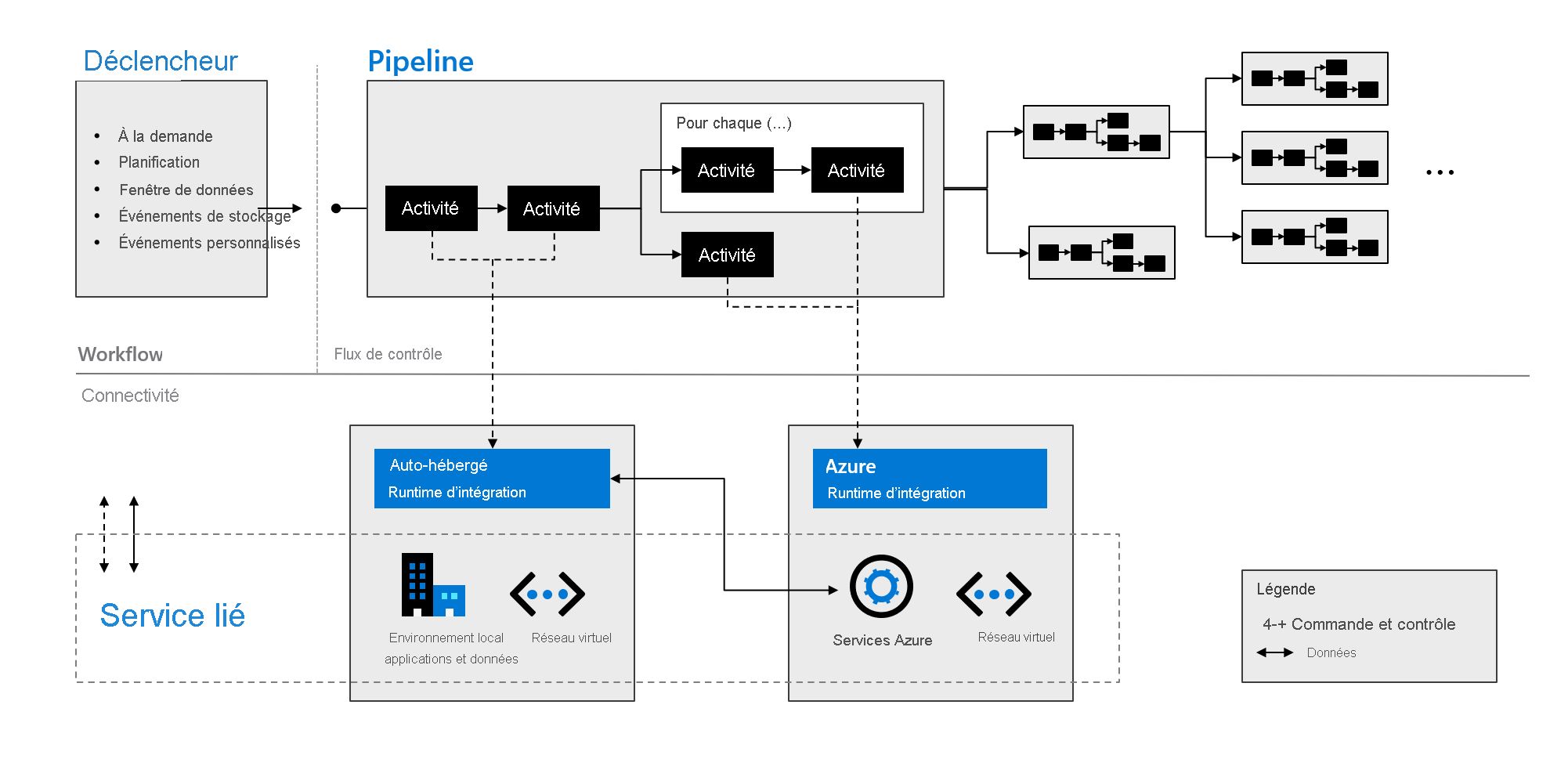
Comme indiqué dans le schéma suivant, ces composants fonctionnent ensemble pour fournir une plateforme complète de bout en bout pour les ingénieurs données. Avec Data Factory, vous pouvez :
- Définir des déclencheurs à la demande et planifier le traitement des données en fonction de vos besoins.
- Associer un pipeline à un déclencheur, ou le démarrer manuellement quand vous en avez besoin.
- Vous connecter aux services liés (comme les applications et les données locales) ou aux services Azure via des runtimes d’intégration.
- Superviser toutes les exécutions de pipeline en mode natif dans l’expérience utilisateur Azure Data Factory, ou à l’aide d’Azure Monitor.