Rendre les applications scalables
Maintenant que vous comprenez les bases de la préparation à la croissance et que vous connaissez les facteurs à prendre en compte dans la planification de la capacité, vous pouvez relever le défi de rendre vos applications aussi scalables que possible.
Examens architecturaux
Il est essentiel d’effectuer régulièrement un examen architectural de vos systèmes.
Vous savez que vous pouvez appliquer des pratiques comme l’infrastructure en tant que code pour améliorer le déploiement de vos ressources cloud. Vous mettez à jour et améliorez régulièrement votre code d’application, et vous devez faire de même avec vos ressources de plateforme sous-jacentes.
L’examen architectural vous aide à identifier les domaines à améliorer.
Le Centre des architectures Azure propose une multitude de ressources pour vous aider à concevoir vos applications dans le cloud, et de nombreuses recommandations de scalabilité sont disponibles dans le guide d’architecture d’application sur le lien suivant :
Centre des architectures Azure
Scénario : Architecture de Tailwind Traders
La première étape consiste à effectuer une évaluation de l’architecture et de l’application, non seulement pour en déterminer les faiblesses, mais aussi les forces. Quels sont les points positifs ?
Réexaminez le scénario que vous avez vu dans l’unité précédente. Voici le schéma de l’architecture de l’organisation.
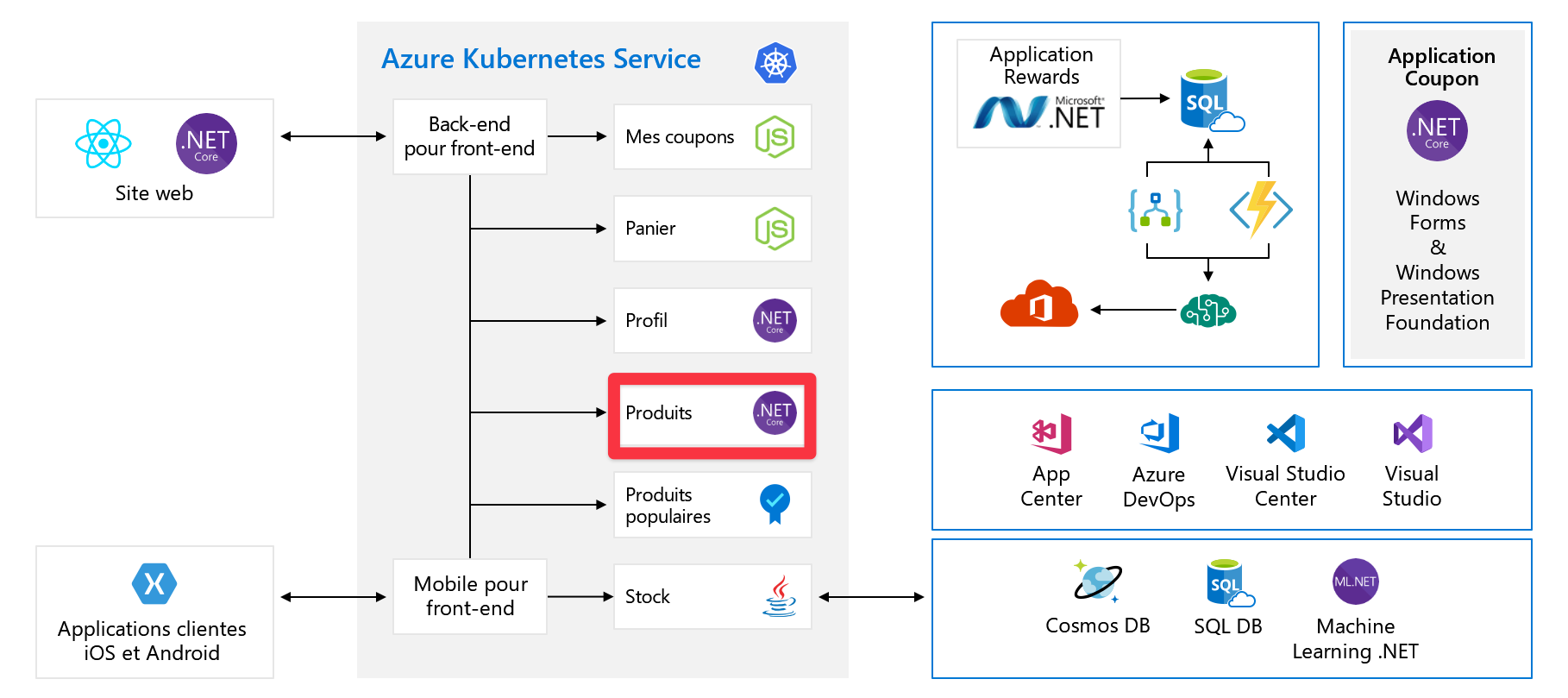
L’application a été décomposée en microservices plus petits et certains de ces services figurent en tant que conteneurs sur Azure Kubernetes Service ou peuvent s’exécuter sur des machines virtuelles ou App Service. Vous utilisez des services intrinsèquement scalables, comme Functions et Logic Apps.
Ce changement est judicieux, mais certaines améliorations pourraient renforcer la scalabilité de l’application. À titre d’exemple, examinons maintenant le service de produit. Dans le diagramme, le service de produit s’exécute dans Kubernetes, mais nous supposons pour cette explication qu’il s’exécute sur une machine virtuelle dans Azure. Les concepts de mise à l’échelle peuvent être appliqués aux applications, éventuellement avec une implémentation légèrement différente, qu’elles s’exécutent sur des serveurs, sur App Service ou dans des conteneurs.
Le produit est actuellement exécuté sur une seule machine virtuelle, connectée à une base de données Azure SQL unique. Vous devez activer cette machine virtuelle pour effectuer un scale-out. Pour cela, vous pouvez utiliser les groupes de machines virtuelles identiques Azure, qui vous permettent de créer et de gérer un groupe de machines virtuelles identiques à charge équilibrée. Comme vous avez maintenant plusieurs machines virtuelles, vous devez introduire un équilibreur de charge pour répartir le trafic entre les machines virtuelles.
Groupes identiques de machines virtuelles
En appliquant des groupes de machines virtuelles identiques sur des machines virtuelles individuelles, vous bénéficiez de certains avantages :
- Vous pouvez mettre à l’échelle automatiquement en fonction des métriques de l’hôte, des métriques de l’invité, des insights de l’application ou d’une planification.
- Vous pouvez utiliser des zones de disponibilité, qui sont des centres de données autonomes indépendants au sein d’une région Azure. La prise en charge des zones de disponibilité vous permet de répartir vos machines virtuelles sur plusieurs zones de disponibilité, ce qui rend votre application plus fiable et la protège contre les défaillances du centre de données. Les nouvelles instances dans un groupe identique sont automatiquement réparties uniformément entre les zones de disponibilité.
- L’ajout d’un équilibreur de charge en est facilité. Les groupes de machines virtuelles identiques prennent en charge Azure Load Balancer pour la distribution du trafic de couche 4 (L4) de base. Ils prennent également en charge Azure Application Gateway pour la distribution de trafic L7 plus avancée et la terminaison SSL.
Vous devez prendre en compte certains facteurs importants avant d’implémenter des groupes identiques. En particulier :
- Évitez l’adhérence des instances, pour qu’aucun client ne soit bloqué sur un back-end spécifique.
- Supprimez les données persistantes de la machine virtuelle et stockez-les ailleurs, par exemple dans le stockage Azure ou dans une base de données.
- Concevez en vue d’un scale-in. Il est également important que votre application puisse ensuite effectuer facilement un scale-down. Elle doit bien gérer le fait que des instances supplémentaires soient ajoutées au pool des serveurs qui traitent le trafic, mais également la résiliation brutale d’instances lorsque la charge diminue. L’aspect du scale-down de la mise à l’échelle est souvent négligé.
Découplage
Vous avez ajouté des machines virtuelles supplémentaires avec des groupes identiques. Le scale-out est la réponse classique au besoin de mise à l’échelle, mais vous pouvez mettre à l’échelle sur une seule métrique, et cette réponse peut ne pas être appropriée pour toutes les tâches effectuées par votre service de produit.
Dans notre scénario, le service de produit a une tâche. Il prend une image de produit et cette image est ensuite chargée. Il transcode cette image et la stocke dans différentes tailles pour les miniatures, les images de catalogue, etc. Le traitement des images est très consommateur de processeur, mais l’utilisation générale est gourmande en mémoire.
Le traitement des images est une tâche asynchrone qui peut être décomposée en un travail en arrière-plan. Pour ce faire, vous devez découpler votre service de traitement d’images en utilisant une file d’attente. Le découplage vous permet de mettre à l’échelle les deux services de manière indépendante : un pour la mémoire (service de produit) et l’autre (service de traitement d’images) pour le processeur, voire pour la longueur de file d’attente. Il vous permet aussi d’avoir un autre groupe identique qui consomme les messages et traite les images.
Mettre à l’échelle avec les files d’attente
Azure propose deux types de file d’attente :
- Files d’attente Azure Service Bus Offre de mise en file d’attente plus avancée qui fait partie du produit Azure Service Bus plus large et propose le modèle publication/abonnement ainsi que des modèles d’intégration plus avancés.
- Files d’attente de stockage Azure Interface de file d’attente simple basée sur REST, s’appuie sur le stockage Azure. Elles offrent une messagerie fiable et persistante.
Vos exigences dans ce scénario sont simples et vous pouvez utiliser des files d’attente de stockage Azure. Votre niveau de produit n’a pas besoin d’être mis à l’échelle, car vous avez découplé cette tâche en arrière-plan.
Mise en cache en mémoire
Une autre façon d’améliorer les performances de votre application consiste à implémenter un cache en mémoire.
Vous savez maintenant que le réglage des performances n’équivaut pas exactement à la scalabilité, mais qu’en améliorant les performances de votre application, vous pouvez réduire la charge sur les autres ressources. Cette amélioration signifie que vous n’aurez peut-être pas besoin de mettre à l’échelle aussi tôt.
Azure Cache pour Redis est une offre Redis managée. Redis peut être utilisé pour de nombreux modèles et cas d’usage. Pour votre service de produit dans ce scénario, vous implémenteriez probablement le modèle cache-aside. Dans ce modèle, vous chargez des éléments de la base de données dans le cache en fonction des besoins. Votre application est alors plus performante et la charge exercée sur la base de données est réduite.
Redis peut également être utilisé comme file d’attente de messagerie, pour mettre en cache le contenu web ou la session utilisateur. Ce type de mise en cache peut être plus adapté à d’autres services dans le système, comme le service de panier d’achat, où vous pouvez stocker les données du panier d’achat par session dans Redis au lieu d’utiliser un cookie.
Mettre à l’échelle la base de données
Maintenant que vous avez rendu vos ressources de calcul plus scalables, examinez votre base de données. Dans ce scénario, vous utilisez une base de données Azure SQL, qui est une offre SQL Server managée d’Azure.
Le scale-out est plus compliqué pour les bases de données relationnelles que pour les bases de données non relationnelles. La première chose que vous pouvez faire pour mettre à l’échelle votre base de données consiste à effectuer un scale-up de la taille de la base de données. Ce redimensionnement peut se faire facilement avec un temps d’arrêt moyen inférieur à quatre secondes. Vous utilisez un simple appel d’API dans Azure SQL ou un curseur dans le portail.
Si cette augmentation de taille ne répond pas à vos besoins, en fonction des caractéristiques du trafic, il peut être approprié d’effectuer un scale-out des lectures dans la base de données. Cela vous permet de router le trafic de lecture vers votre réplica en lecture.
Notes
Avec Azure SQL, si vous utilisez les niveaux Premium ou critique pour l’entreprise, l’option de scale-out en lecture est activée par défaut. Elle ne peut pas être activée sur les niveaux de base ou standard.
Cette modification doit être implémentée dans le code. Il convient de procéder comme suit.
#Azure SQL Connection String
#Master Connection String
ApplicationIntent=ReadWrite
#Read Replica Connection String
ApplicationIntent=ReadOnly
#Full Example
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Mettez à jour l’attribut ApplicationIntent dans votre chaîne de connexion de base de données pour spécifier le serveur auquel vous voulez vous connecter. Utilisez ReadOnly pour vous connecter au réplica ou ReadWrite pour vous connecter au serveur maître.
Comme cette commande doit être implémentée dans le code, ce n’est peut-être pas la bonne solution pour votre situation. Que se passe-t-il si chaque service de produit doit pouvoir lire et écrire ?
Dans ce cas, vous pouvez envisager un scale-out de la base de données SQL avec un partitionnement.
Partitionnement de base de données
Si, après le scale-up ou l’implémentation de réplicas en lecture, vos ressources de base de données ne répondent toujours pas aux besoins de votre système, l’option suivante consiste à effectuer un partitionnement.
Le partitionnement est une technique permettant de distribuer de grandes quantités de données structurées de façon identique entre plusieurs bases de données indépendantes. Le partitionnement peut être nécessaire pour de nombreuses raisons. Par exemple :
- La quantité totale de données est trop importante pour tenir dans les contraintes d’une base de données individuelle.
- Le débit des transactions de la charge de travail globale dépasse les capacités d’une base de données individuelle.
- Des locataires distincts doivent résider sur différentes bases de données physiques pour des raisons de conformité (cette exigence concerne moins la mise à l’échelle, mais constitue une autre situation dans laquelle le partitionnement est utilisé).
Votre application ajoute les données appropriées à la partition appropriée, ce qui rend votre système scalable au-delà des contraintes de la base de données individuelle.
Azure SQL offre les outils de base de données élastique Azure. Ces outils vous aident à créer, gérer et interroger des bases de données SQL partitionnées dans Azure à partir de votre logique d’application.