Qu’est-ce que la scalabilité ?
Dans le monde de l’entreprise, la croissance peut être bénéfique. Toutefois, lorsque la croissance est trop rapide et que vous ne l’avez pas correctement préparée, elle peut entraîner des problèmes. Un de ces problèmes est l’impact de la croissance sur la fiabilité des applications et des services qui n’ont pas été conçus pour gérer une hausse importante du trafic.
Pour vos clients et vos utilisateurs, une panne est une panne. Ils ne savent pas si leur incapacité à accéder à votre site provient d’une mauvaise programmation ou d’un trop grand nombre de personnes voulant accéder au même moment à votre site parfaitement codé, et cela ne les intéresse pas.
La scalabilité est la capacité à s’adapter à une augmentation de la demande ou à des besoins changeants. Vos applications et services doivent être en mesure de gérer une plus grande charge de travail pour accompagner la croissance. Les applications scalables sont en mesure de gérer un nombre croissant de demandes au fil du temps, sans incidence négative sur la disponibilité et les performances.
Dans cette unité, vous découvrez la relation entre scalabilité et fiabilité, l’importance de la planification de capacité pour assurer la scalabilité, et vous passez brièvement en revue quelques concepts et termes de base liés à la mise à l’échelle.
Relation entre scalabilité et fiabilité
La bonne nouvelle est que le fait de rendre votre application plus scalable peut également la rendre plus fiable. Par exemple, si votre système est mis à l’échelle automatiquement, dans le cas d’une défaillance d’un composant sur une machine virtuelle individuelle, le service de mise à l’échelle automatique provisionne une autre instance pour maintenir le nombre minimal requis de machines virtuelles. Votre système gagne en fiabilité. Dans un autre exemple, vous utilisez un service de niveau supérieur, comme le Stockage Azure, qui est intrinsèquement scalable. Si vous avez un problème de stockage, comme le service est conçu pour être fiable, vos données sont répliquées.
Voici une analogie : prenons l’exemple des rampes d’accessibilité souvent installées en dehors des bâtiments, dont l’objectif initial était d’aider les personnes en fauteuil roulant. Elles sont utilisées à cet effet. Toutefois, elles sont également utilisées par les parents avec des enfants en poussette ou landau, ou par les jeunes enfants pour lesquels les marches d’escalier sont trop hautes. Cette utilisation est un avantage secondaire.
La fiabilité est souvent un avantage secondaire de la scalabilité. Si vous concevez vos systèmes pour qu’ils soient scalables, ils seront également plus fiables.
Scalabilité et planification de la capacité
La planification de la capacité consiste à déterminer les ressources dont vous avez besoin pour répondre aux demandes actuelles et futures. Pour faire cette planification, vous analysez l’utilisation actuelle des ressources, puis prévoyez la croissance future.
Pour estimer les besoins de capacité à l’avenir, vous devez prendre en compte des facteurs tels que :
- La croissance d’activité prévue
- Les fluctuations périodiques (saisonnières, etc.)
- Les contraintes d’application
- L’identification de goulots d’étranglement et de facteurs limitants
Vous devez également définir des objectifs de niveau de service pour pouvoir créer un plan de gestion de capacité dans le but d’atteindre ou de dépasser ces objectifs de manière fiable quand la charge de travail et l’environnement changent.
La planification de la capacité est un processus itératif. Dans ce module, vous apprenez à planifier les besoins en ressources des composants d’application.
Concepts et terminologie
Pour comprendre pleinement les concepts et les stratégies que vous rencontrez dans ce module, vous avez besoin de connaître certains concepts de base et termes fondamentaux liés à la mise à l’échelle.
- Scale-up : augmentation de la taille d’un composant afin de gérer une charge de travail accrue. Également appelé mise à l’échelle verticale.
- Scale-out : ajout de composants ou de ressources supplémentaires pour répartir la charge sur une architecture distribuée. Par exemple, en utilisant une architecture simple dotée de plusieurs back-ends derrière un ensemble de front-ends. À mesure que la charge augmente, nous ajoutons des serveurs back-end (et front-end) pour la gérer. Également appelé mise à l’échelle horizontale.
- Mise à l’échelle manuelle : une action humaine est nécessaire pour augmenter la quantité de ressources.
- Mise à l’échelle automatique : le système ajuste automatiquement la quantité de ressources en fonction de la charge. Pour être clair, la quantité est ajustée à la hausse ou à la baisse en fonction d’une augmentation ou d’une diminution de la charge.
- Mise à l’échelle par vous-même : mise à l’échelle autonome dans le cadre de laquelle vous devez configurer la mise à l’échelle automatique.
- Échelle intrinsèque : services qui ont été conçus pour être scalables et gérer cette mise à l’échelle pour vous en arrière-plan, sans aucune intervention de votre part. De votre point de vue, ils affichent une scalabilité presque infinie, car vous pouvez consommer plus de ressources sans avoir besoin de les provisionner manuellement.
Architecture de Tailwind Traders
Dans ce module, nous allons utiliser un exemple d’architecture d’une société fictive de fabrication de matériel, appelée Tailwind Traders. Leur plateforme d’e-commerce ressemble à ceci :
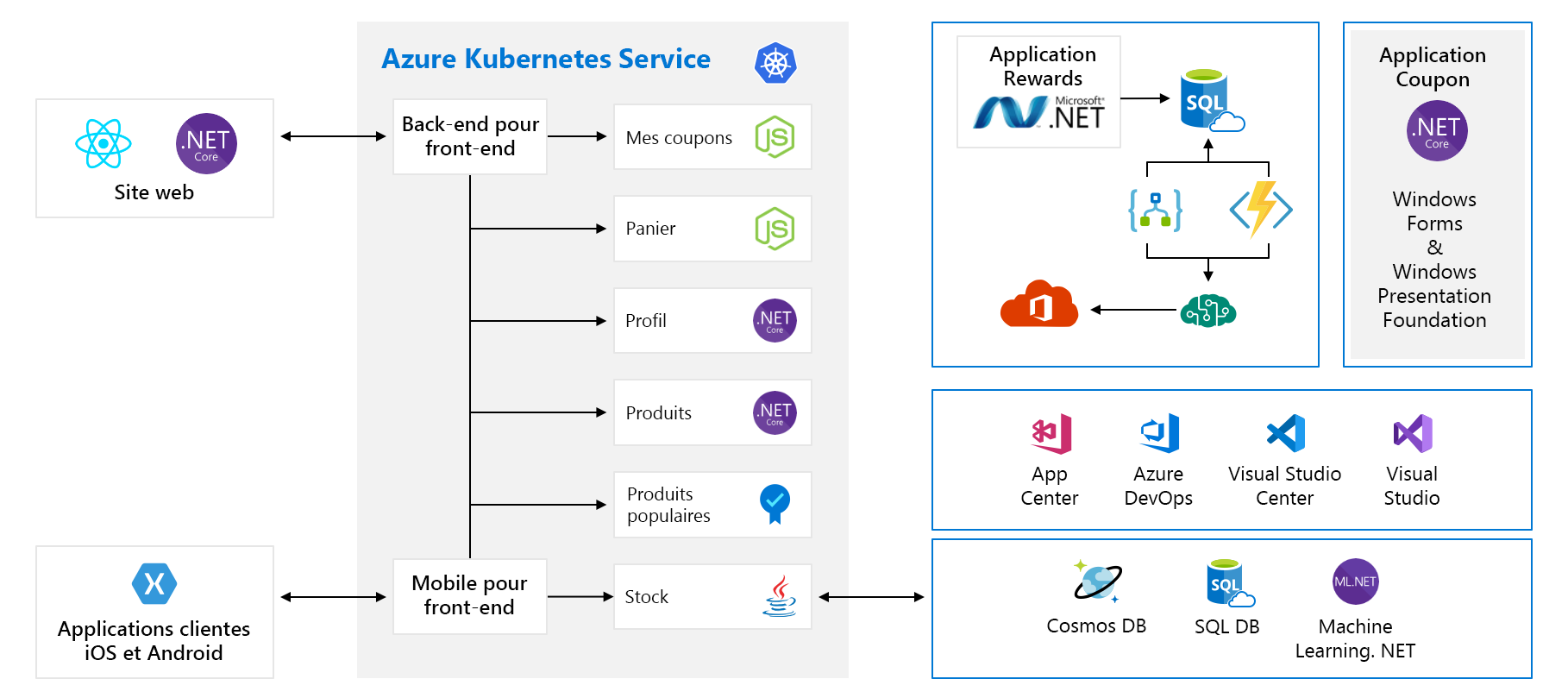
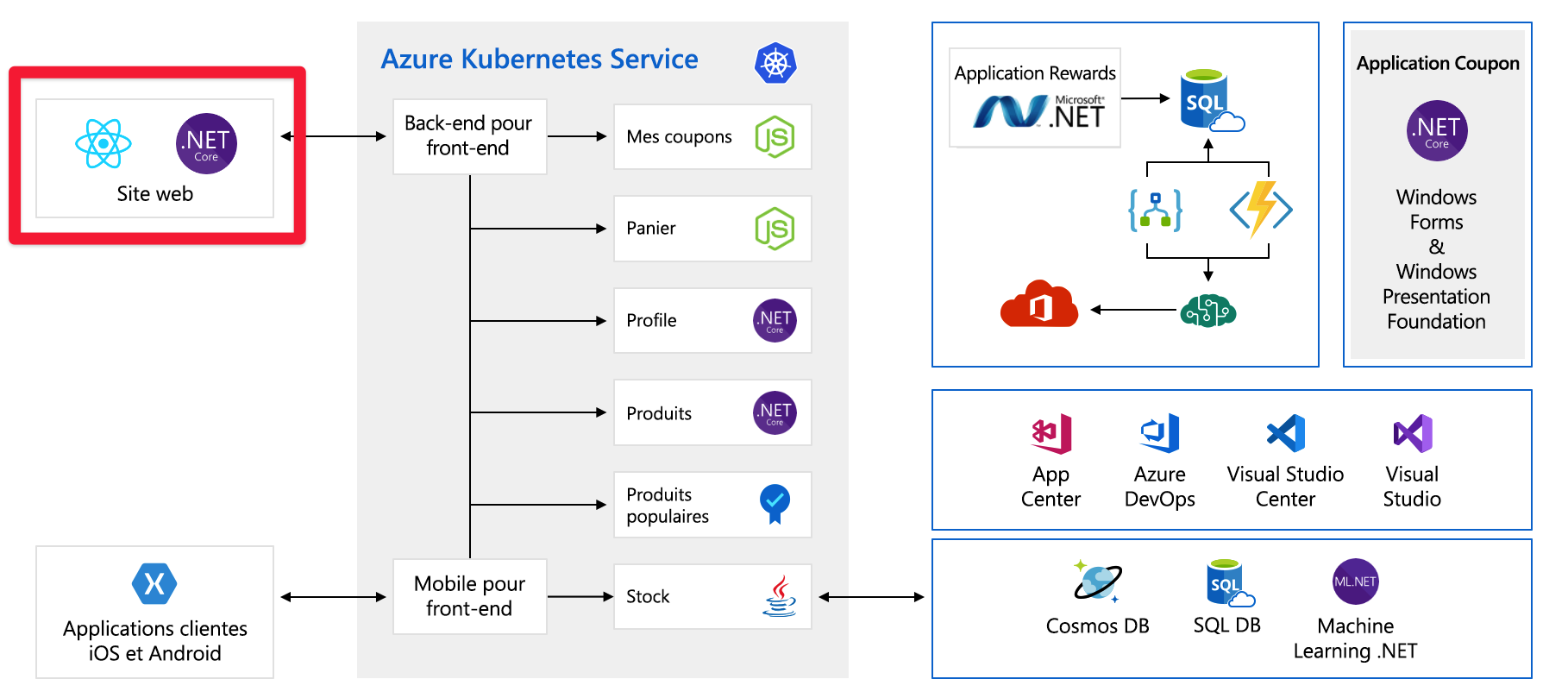
Ce diagramme semble assez complexe à première vue, voyons ce qu’il en est. Le site web a un front-end. C’est ce à quoi on parle quand on va sur tailwindtraders.com.
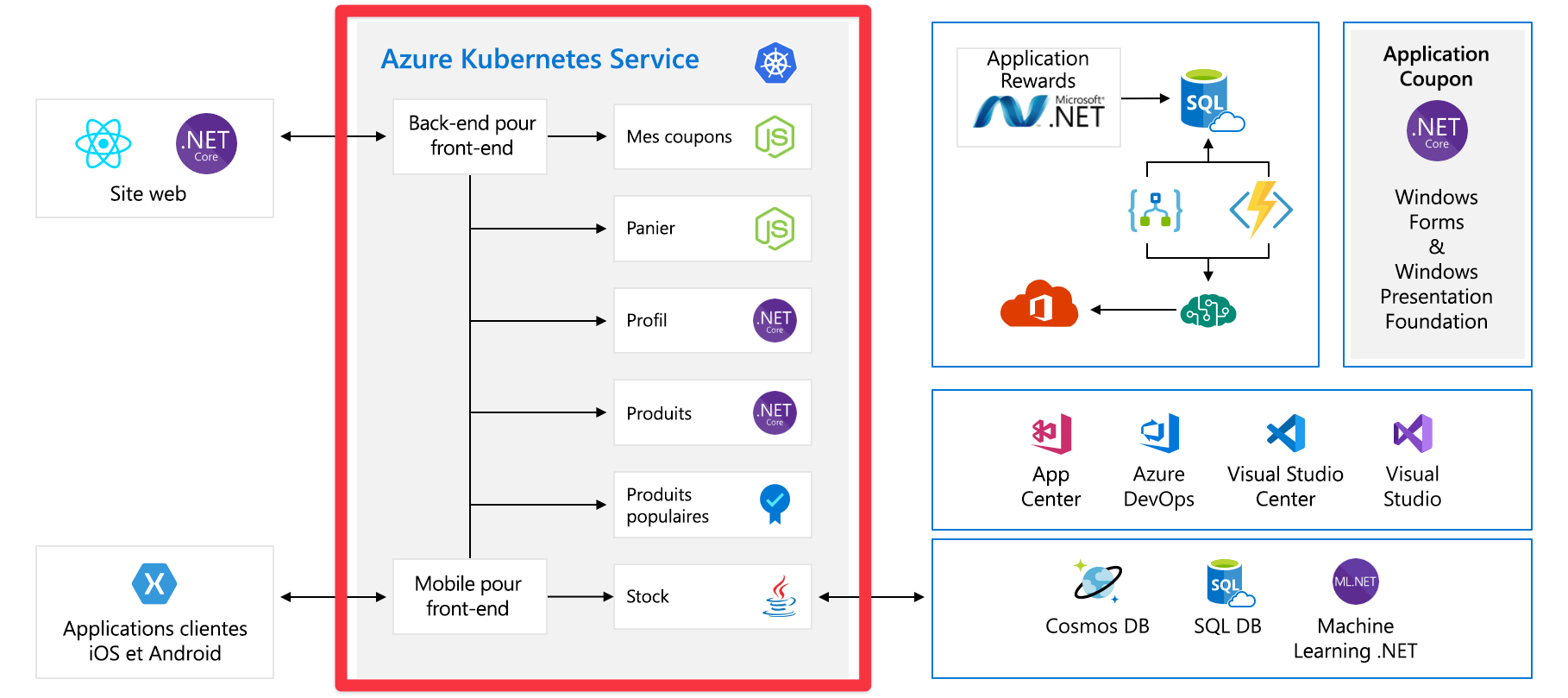
Le front-end communique avec un ensemble de services back-end. Ces services back-end incluent les éléments courants tels qu’un service de coupon, un service de panier d’achat, un service d’inventaire, etc. Ils s’exécutent tous dans Azure Kubernetes Service. Il existe d’autres composants et technologies impliqués avec cette application. Les seules choses sur lesquelles vous devez vous concentrer sont les services front-end et back-end exécutés sur Kubernetes.
Points de défaillance uniques
Maintenant que vous avez vu l’intégralité de l’architecture, prenez le temps d’examiner les points de défaillance uniques et les emplacements à prendre en compte pour la mise à l’échelle.
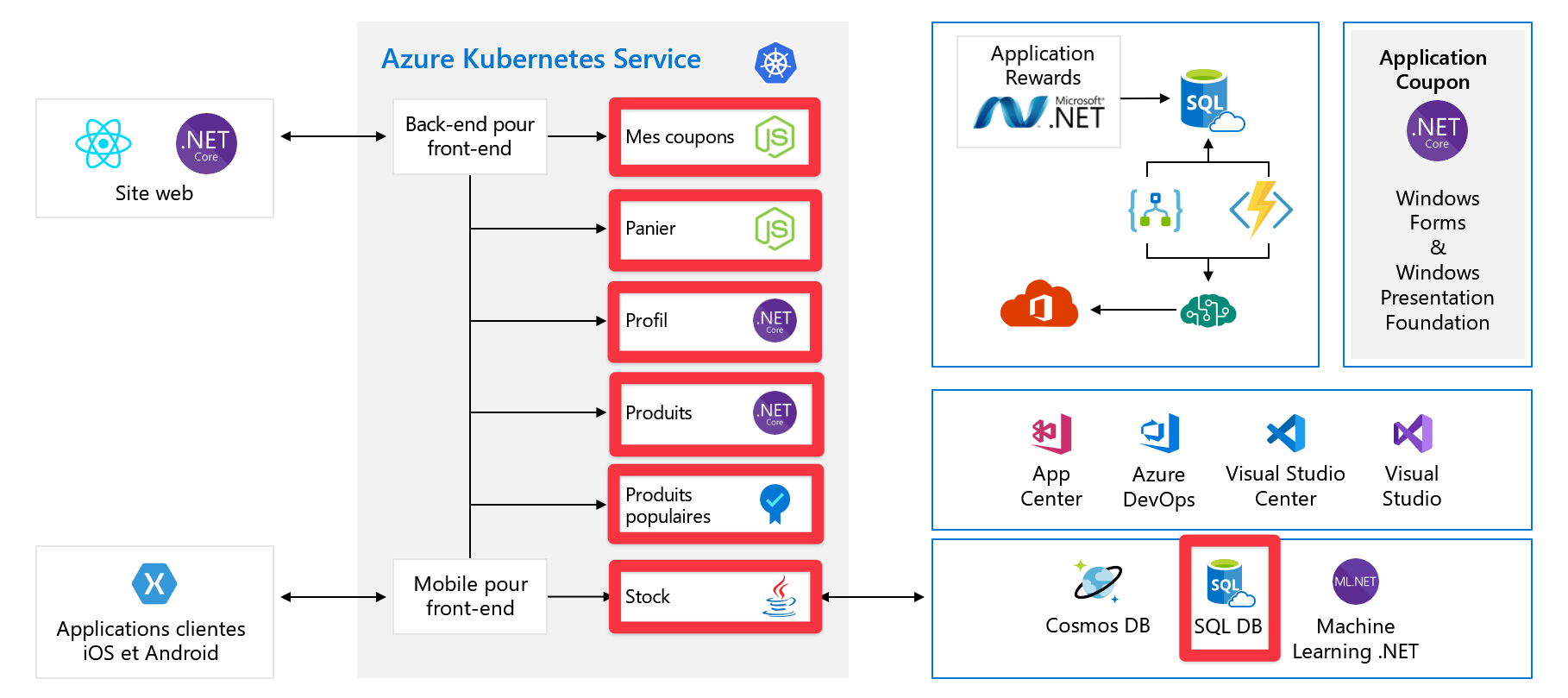
Tous ces services constituent un point de défaillance unique. Ils ne sont pas conçus pour la résilience ni la mise à l’échelle. Si l’un d’eux est surchargé, il va se bloquer et il n’y a aucun moyen simple de le résoudre sur le moment.
Plus loin dans ce module, nous voyons d’autres façons de concevoir ce service pour qu’il soit plus scalable et plus fiable.
Capacité préconfigurée
Nous allons examiner un autre problème qui pourrait s’avérer gênant. Voici les services/composants qui nécessitent une capacité préprovisionnée :
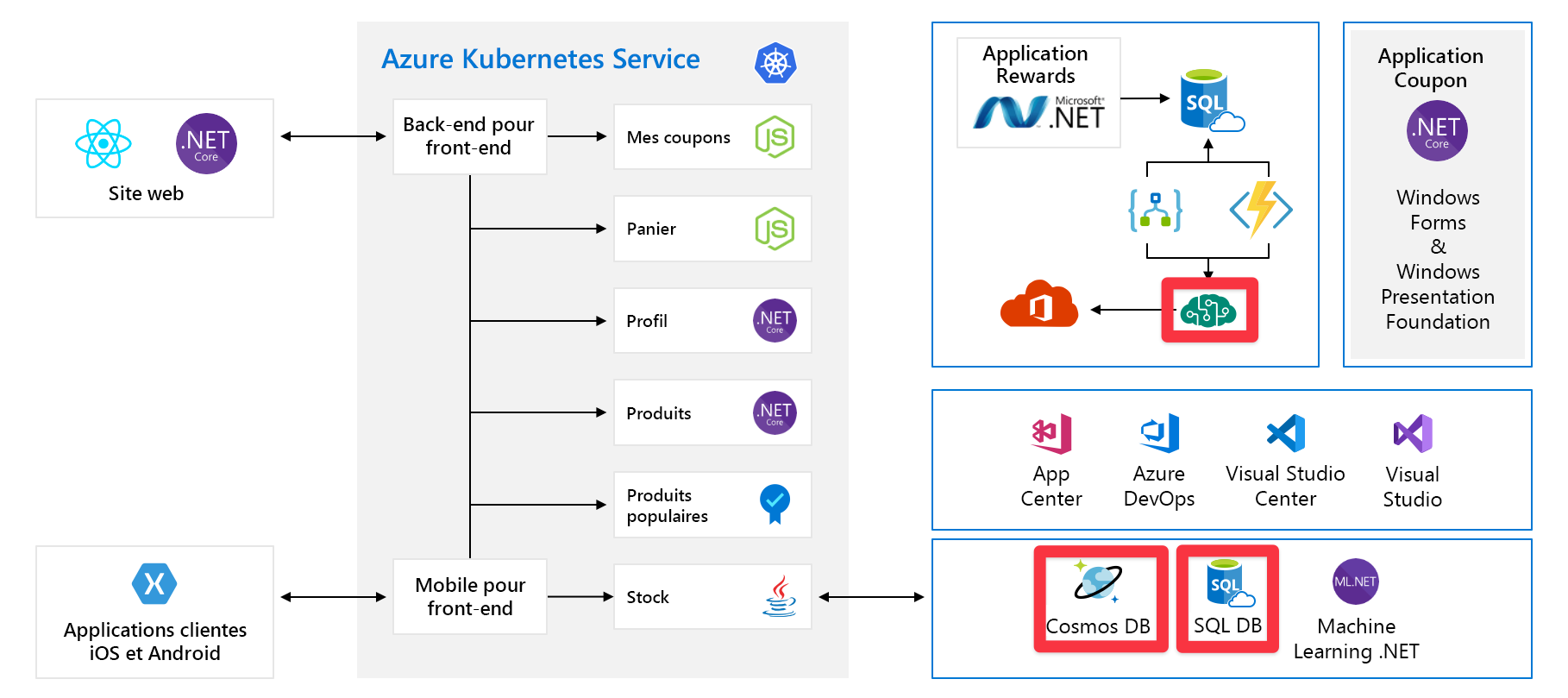
Par exemple, Cosmos DB nous permet de préconfigurer le débit. Si nous dépassons ces limites, nous allons commencer à renvoyer des messages d’erreur à nos clients. Avec Azure AI services, nous sélectionnons le niveau et ce niveau a un nombre maximal de demandes par seconde. Une fois que nous avons atteint une de ces limites, les clients sont dans un goulot d’étranglement.
Un pic important du trafic, comme le lancement d’un nouveau produit, peut-il nous faire atteindre ces limites ? À ce stade, nous ne le savons pas. C’est un autre point que nous abordons plus loin dans ce module.
Coûts
Même lorsque nous faisons bien les choses, nous devons tout de même planifier la croissance. Voici les services de paiement à l’utilisation :
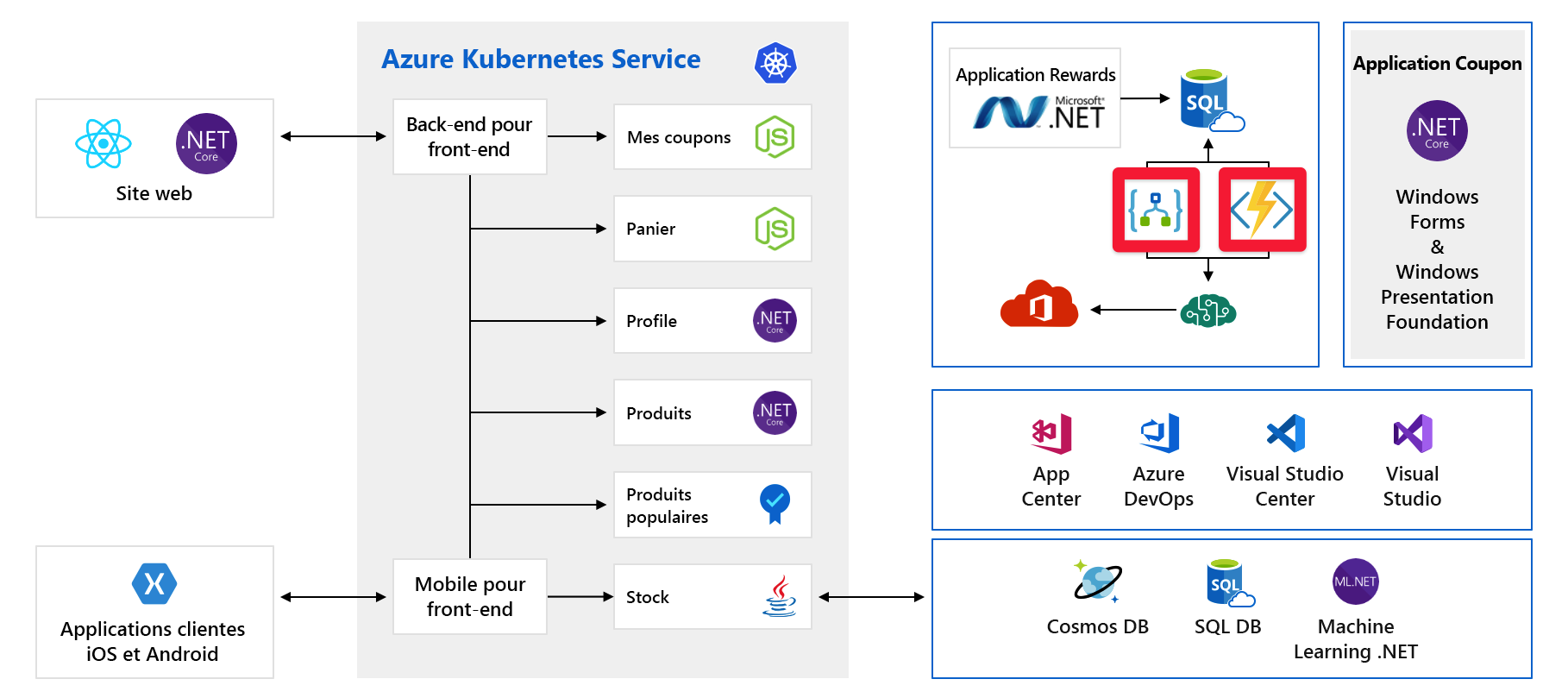
Ici, nous utilisons Azure Logic Apps et Azure Functions, qui sont deux exemples de technologie serverless. Ces services sont mis à l’échelle automatiquement et nous payons à la demande. Votre facture croît avec votre clientèle. Nous devrions au moins être conscient de l’impact des événements à venir, tels qu’un lancement de produit sur nos dépenses cloud. Nous cherchons à comprendre et prédire nos dépenses cloud également plus loin dans ce module.