Sensibilisation opérationnelle
Pour commencer à travailler sur la supervision de la fiabilité, une étape préalable est nécessaire. Tout d’abord, nous devons nous assurer que nous avons un niveau raisonnable de sensibilisation opérationnelle.
Afin d’expliquer cela, le plus simple est de comprendre que pour optimiser la fiabilité des systèmes en production, nous devons tout d’abord avoir une bonne compréhension de ces systèmes et de la façon dont ils fonctionnent en production.
Collecter des informations sur la configuration actuelle
Cela peut sembler étrange, mais dans de nombreux environnements, la première question à se poser est « Qu’est-ce qui s’exécute exactement en production ? ». De nos jours, les environnements de production et leurs chemins de déploiement sont tellement complexes qu’il peut être utile de commencer par quelques étapes de découverte. Pour une application spécifique, quels sont ses composants ? Quelles parties communiquent avec d’autres parties ? Quelles sont les dépendances évidentes (et non évidentes) pour cette application ?
Collecter des informations sur les performances normales et passées
Une fois que nous obtenons ces informations, nous pouvons tenter d’obtenir un niveau de référence quant aux performances et au comportement « normal » pour le système. Ces informations sont nécessaires pour de nombreuses raisons, notamment quand nous devons hiérarchiser un problème de l’application. En cas d’interruption du service, ce n’est vraiment pas le bon moment pour vous demander si une valeur de serveurs de base de données qui s’exécutent à 80 % d’utilisation du processeur constitue une performance satisfaisante ou insuffisante.
Dans le cadre de l’obtention de ce niveau de référence, nous souhaitons étudier les performances passées. Il est vrai que les performances passées ne garantissent pas les résultats futurs, toutefois ces valeurs permettent parfois d’étalonner nos attentes. De même, si nous avons accès à des informations sur les interruptions passées ou les pannes temporaires d’un service, ces données peuvent nous donner une idée des modes d’échec potentiels que nous devrons intégrer dans notre approche de la fiabilité.
Collecter des informations sur le contexte
Enfin, il est utile d’obtenir des connaissances contextuelles concernant un système. Le contexte peut couvrir un large éventail de domaines, souvent socio-techniques. Si on considère l’aspect social par exemple, nous souhaitons recueillir des informations correctes sur les parties prenantes associées à un service ou à une application.
Vous pensez peut-être : « Oh, nous savons très bien qui possède une application/un service particulier ou qui s’y intéresse ». Toutefois, dans des situations d’entreprise ou d’autres organisations complexes, cela peut s’avérer beaucoup plus difficile qu’il n’y paraît.
Malheureusement, nous ne pouvons pas améliorer sensiblement la fiabilité d’un système sans connaître précisément les parties prenantes, pour des raisons qui deviendront évidentes quand nous aborderons les indicateurs SLI et les objectifs SLO ultérieurement.
Concernant l’aspect technique du contexte, il est vraiment utile de prendre en compte les questions techniques comme : Comment cette application a-t-elle été lancée en production ? A-t-elle été déployée manuellement lors d’un déploiement de type épopée ou via un pipeline CI/CD automatisé avec une série importante de tests unitaires ?
Ces informations peuvent présenter de nombreuses ramifications, notamment la facilité d’itération si nous devons effectuer des mises à jour améliorant la fiabilité. Il peut également s’agir d’un indicateur de travail utile qui fera une grande différence.
Outils Azure donnant des informations sur l’exploitation
La sensibilisation opérationnelle est souvent difficile à atteindre. Cependant, nous allons examiner quelques outils fournis par Azure qui peuvent nous y aider. Il s’agit d’une analyse très superficielle. À la fin de ce module, nous indiquerons des liens vers d’autres modules et la documentation Microsoft Learn si vous souhaitez découvrir plus en détail l’un de ces sujets.
Application Insights
Les premiers outils que nous allons examiner nous permettent de répondre à la question : « Qu’est-ce que nous exécutons réellement ? ». Pour les personnes liées à l’exploitation, il n’est pas rare de devoir utiliser une application qui est déjà en production. Dans l’idéal, nous devrions faire partie du cycle de vie entier du logiciel, dès la phase de conception, mais ce n’est pas toujours (voire pas souvent) le cas. Quand cela se produit, en particulier dans le cas d’applications complexes multicouches ou basées sur des microservices, la simple compréhension de ce que tous les éléments font peut demander des efforts.
Application Insights est un outil permettant de réduire ces efforts et qui fournit des informations sur le comportement de l’application en production. Avec un minimum d’efforts, les développeurs peuvent instrumenter leur application afin qu’elle envoie automatiquement des informations de télémétrie aux collecteurs exécutés dans Azure. Avec ces informations, Application Insights peut créer une carte visuelle des composants de l’application et de la communication entre eux.
Voici un exemple :
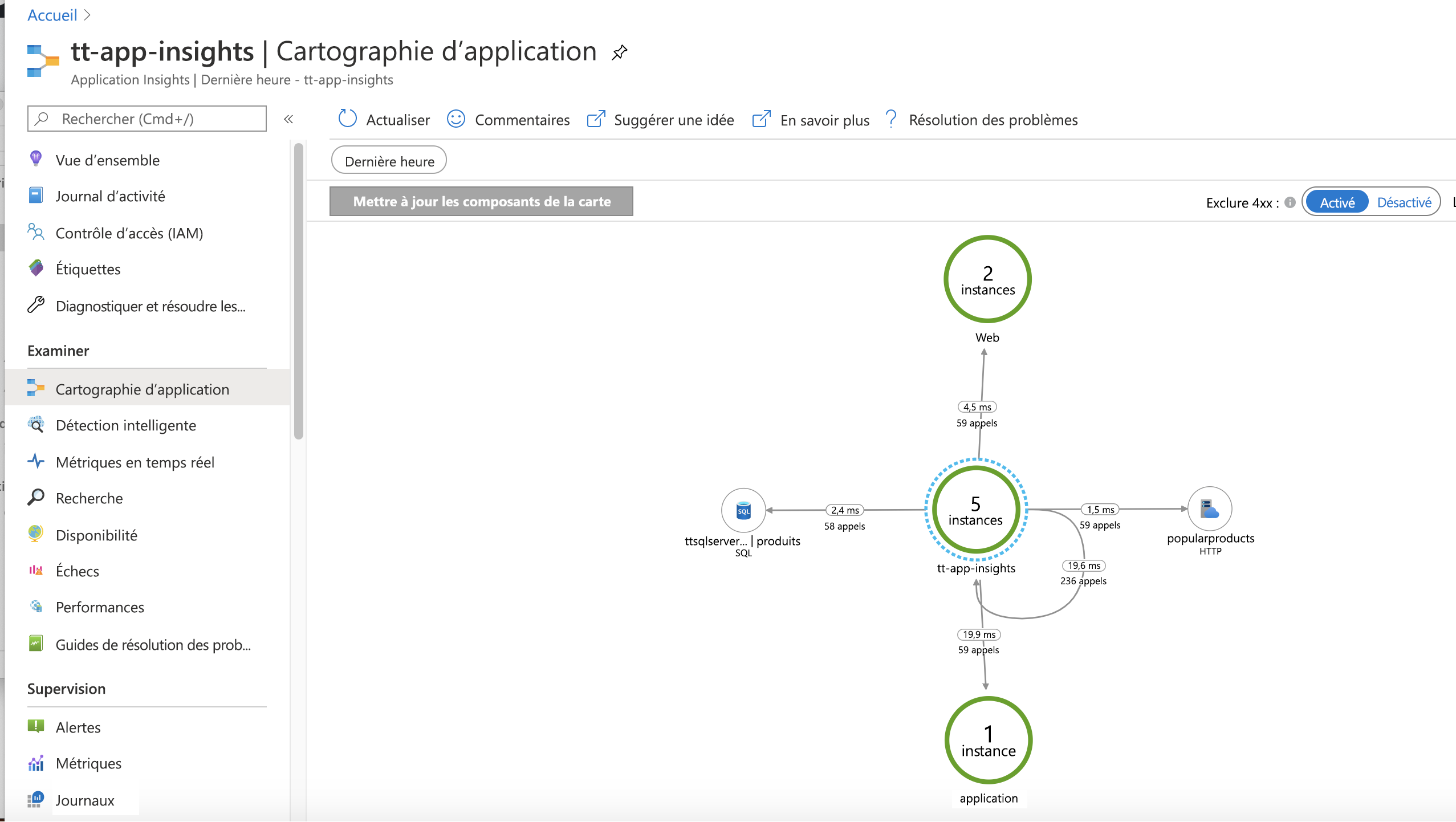
Dans l’image précédente, vous voyez non seulement les composants de l’application, mais également la communication entre eux. Si vous zoomez sur l’une des connexions entre des composants, vous pouvez afficher le nombre d’appels entre les composants et la latence moyenne pour ces appels. Vous pouvez également voir une représentation du nombre d’appels ayant réussi ou échoué. Si vous sélectionnez l’un de ces éléments cartographiques, Application Insights vous permet d’explorer les informations afin d’obtenir des statistiques détaillées sur les métriques de performances et de réussite/échec de ces appels. Cela peut être un excellent moyen d’obtenir une vue d’ensemble des composants de l’application et de la façon dont ils fonctionnent comme une base de référence. N’oubliez pas que vous devez découvrir votre cartographie d’application, ainsi que les différentes options offertes par Application Insights avant de subir une interruption du service.
Azure Resource Graph
Application Insights est une excellente fonctionnalité pour acquérir une sensibilisation opérationnelle concernant une application. Cependant, comment procéder si vous souhaitez obtenir une vue plus globale et afficher l’ensemble des ressources en jeu sur Azure dans un abonnement ? Par le passé, vous pouviez télécharger des rapports ou écrire des scripts PowerShell pour recueillir ces informations, mais il existe désormais un moyen beaucoup plus simple.
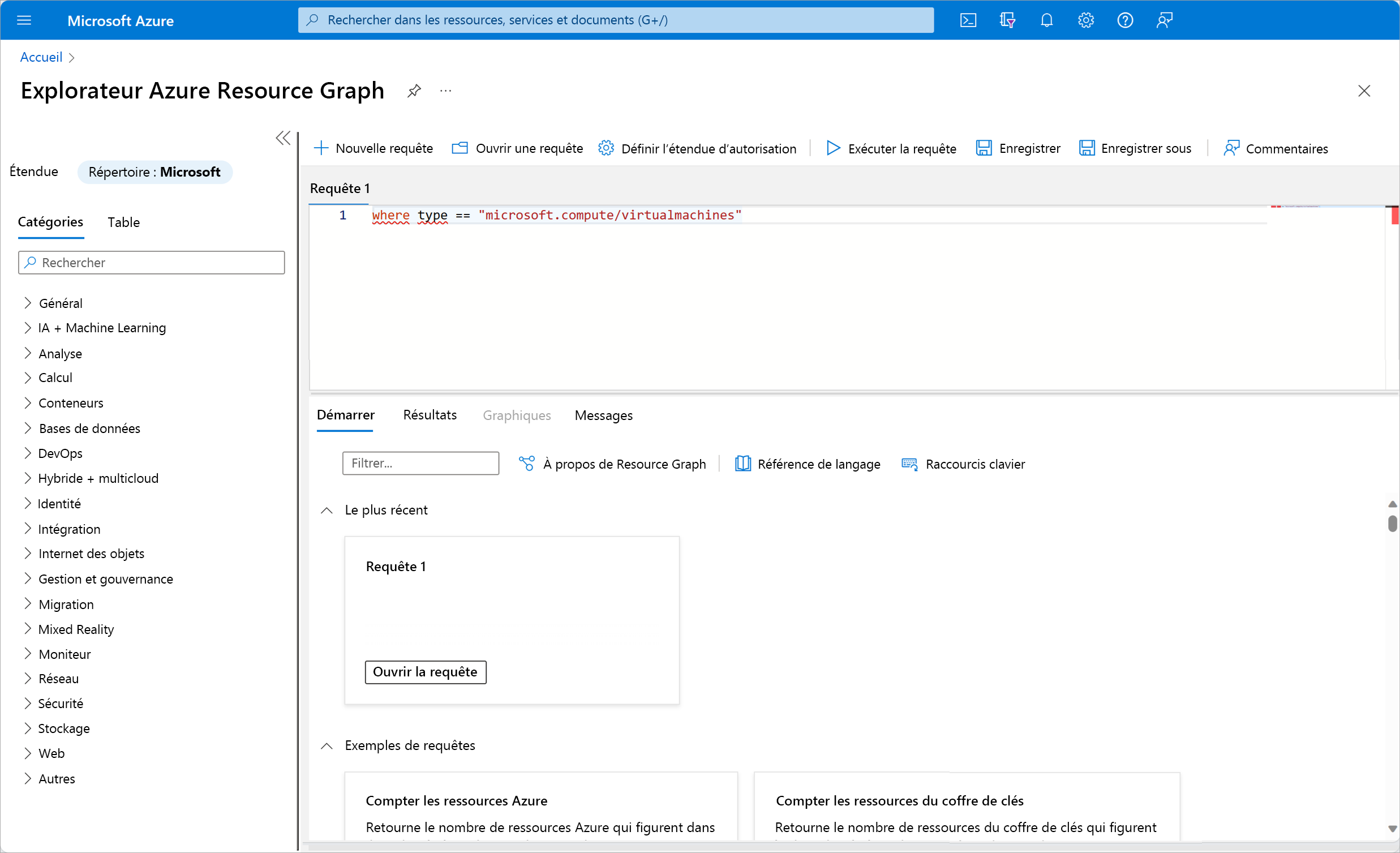
L’explorateur Azure Resource Graph fournit un environnement de requête interactif directement disponible dans le portail Azure pour les données dont vous avez besoin. Elle vous permet d’exécuter des requêtes arbitraires qui renvoient des réponses en temps réel en fonction des ressources en cours d’utilisation. Si vous souhaitez par exemple afficher l’ensemble des machines virtuelles en cours d’exécution, vous pouvez exécuter la requête suivante :
et vous obtenez une liste complète détaillée des machines virtuelles utilisées dans l’abonnement :
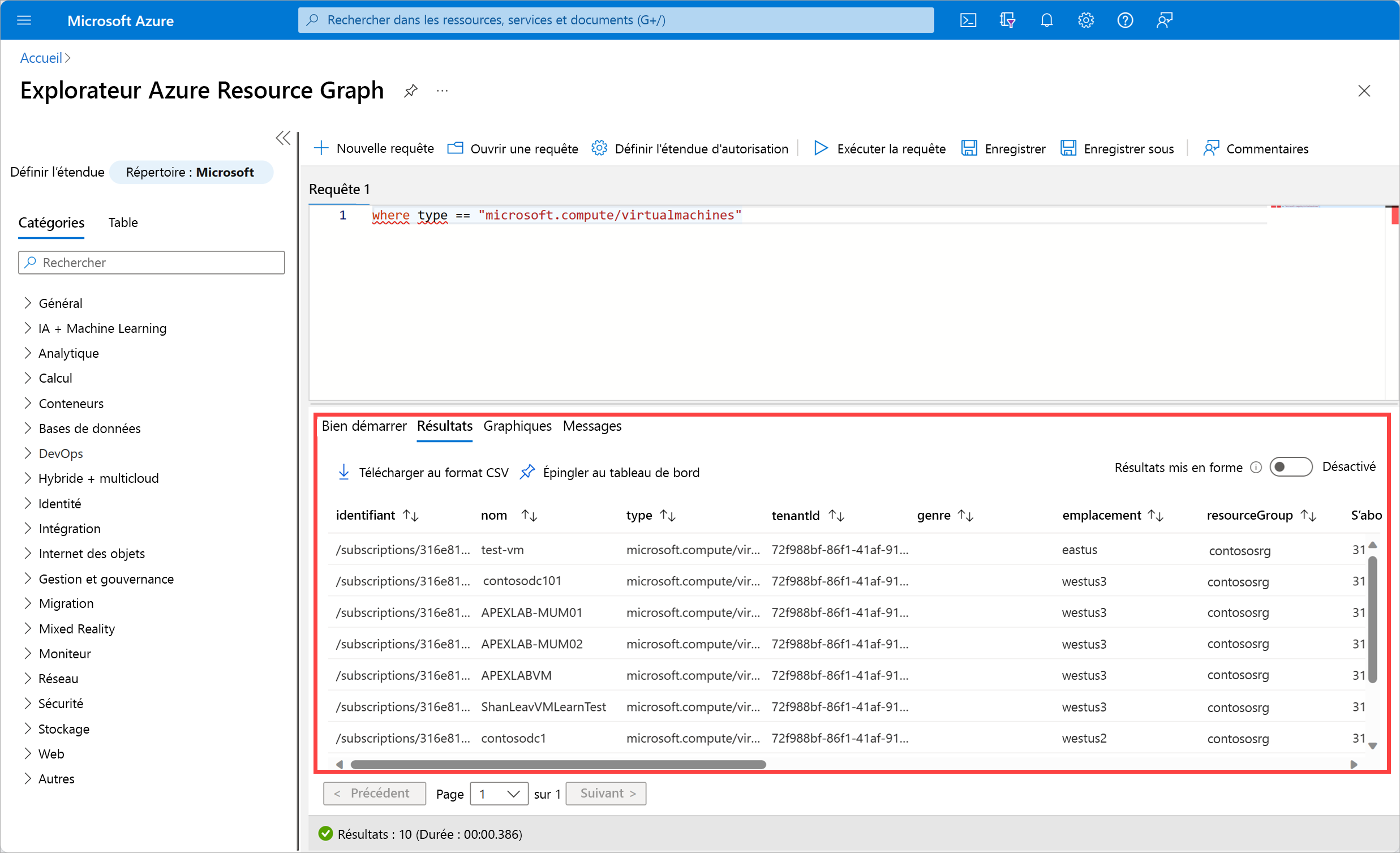
Le langage de requête utilisé dans cet environnement est le langage de requête Kusto (KQL). Nous en parlerons plus en détail plus loin dans ce module, lorsque nous aborderons Azure Monitor Log Analytics.
Tableaux de bord
L’outil d’exploitation le plus traditionnel pour la sensibilisation opérationnelle est le vénérable tableau de bord. Souvent, lorsque nous considérons les personnes qui effectuent des opérations, nous les imaginons assises devant d’énormes écrans, scrutant intensément des analyses volumineuses qui s’apparient à des tableaux de bord remplis de graphiques et de compteurs. Dans ce module, nous n’allons pas étudier comment construire, modifier et utiliser des tableaux de bord. Cela s’effectue en grande partie en épinglant le contenu d’autres emplacements dans le portail, puis en l’arrangeant selon vos besoins.
Examinons plutôt deux fonctionnalités des tableaux de bord moins couramment utilisées et qui pourraient vous être utiles. Ces fonctionnalités se trouvent en haut de chaque tableau de bord.

Les deux flèches mises en évidence permettent de charger et d’exporter des représentations JSON des tableaux de bord.
Commençons par la fonctionnalité d’exportation. Si vous sélectionnez Exporter, puis Télécharger, un fichier JSON représentant le tableau de bord actuel est téléchargé sur votre ordinateur. Si vous le souhaitez, essayez cette fonctionnalité dès maintenant en vous connectant au portail, en choisissant Tableau de bord dans le menu du produit, puis en sélectionnant Exporter>Télécharger.
Ce fichier permet d’effectuer au moins deux opérations que vous pourriez trouver pratiques :
Vous pouvez vérifier ce fichier dans notre système de contrôle de code source. Cela vous permet d’effectuer le suivi des différentes versions des tableaux de bord, ainsi que d’autoriser l’accès à d’autres utilisateurs souhaitant utiliser votre tableau de bord. Certains pourraient les qualifier de « tableaux de bord en tant que code ».
Vous pouvez utiliser ce fichier comme base pour un nouveau tableau de bord. Voici un exemple concret que nous allons réexaminer ultérieurement dans ce parcours d’apprentissage : imaginons que vous devez montrer à un collègue un tableau de bord particulier, tel qu’il était à une période donnée lors d’une interruption du service qui s’est produite la semaine précédente. Vous pouvez publier votre tableau de bord et lui demander de sélectionner la période et l’heure précises. Une méthode beaucoup plus simple et moins sujette aux erreurs consiste à télécharger le tableau de bord avec la configuration exacte nécessaire, puis à partager ce fichier JSON. Si vous souhaitez mettre en évidence une autre période du même tableau de bord, par exemple une heure plus tard, il est facile de modifier le fichier JSON.
Voilà pour la fonctionnalité d’exportation. Nous allons maintenant nous pencher sur les utilisations de la fonctionnalité de chargement. Outre la possibilité de charger les fichiers avec gestion de version ou modifiés à partir de la dernière section, la fonctionnalité de chargement permet d’utiliser le travail d’autres utilisateurs lors de la création de tableaux de bord.
Examinons l’exemple final de cette section qui relie bien deux des idées de cette unité. Si vous téléchargez ce fichier JSON :
sur votre ordinateur, puis que vous le chargez dans un tableau de bord, vous voyez normalement quelque chose comme ceci :
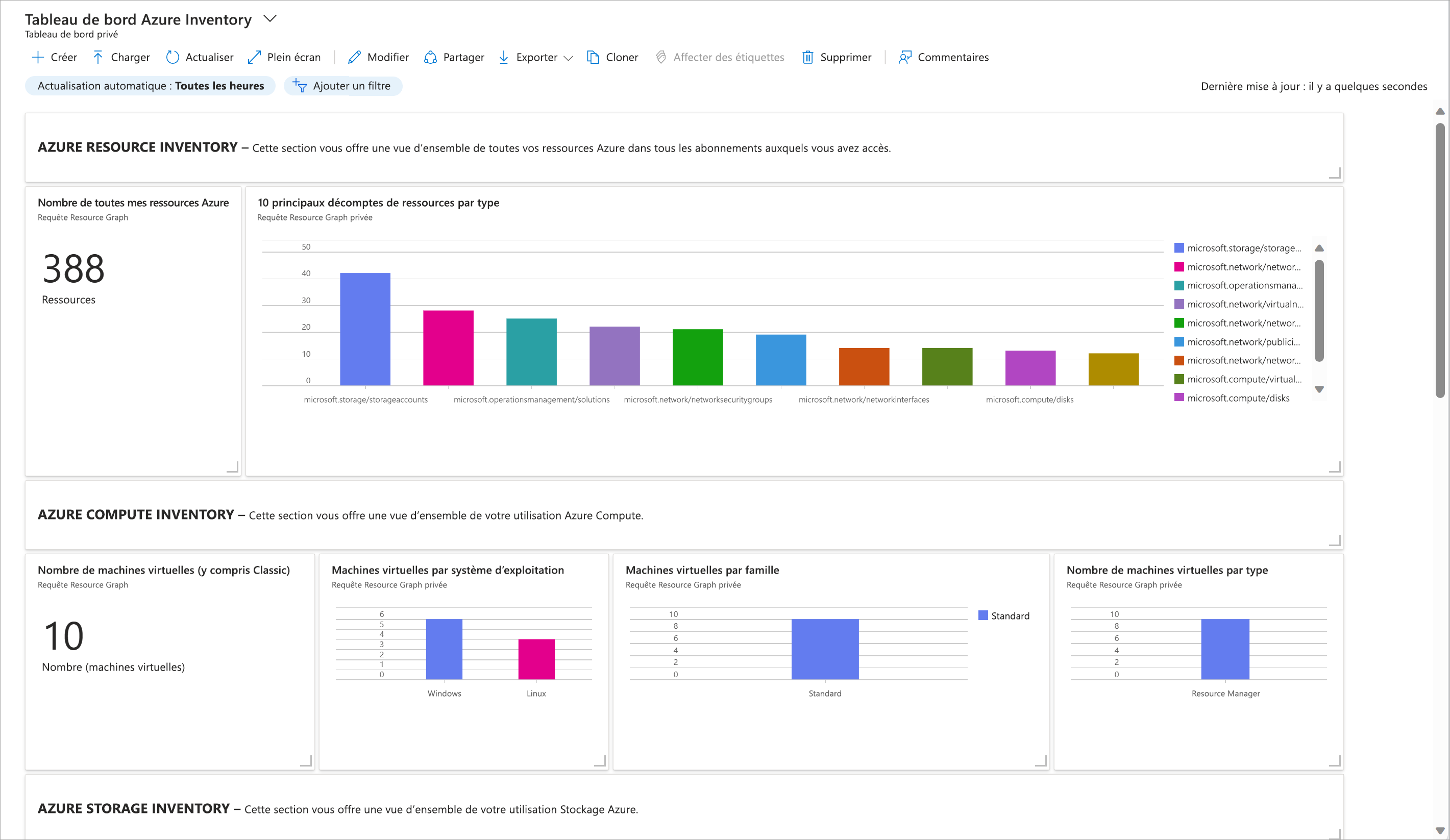
Vous disposez maintenant d’un tableau de bord dynamique qui vous montre un inventaire assez compréhensible de vos ressources en cours d’utilisation dans un abonnement. Les données de ce tableau de bord proviennent de la même source que dans l’explorateur Azure Resource Graph abordé précédemment. En fait, si vous sélectionnez l’une des vignettes, vous pouvez afficher (voire modifier) la requête exacte qui est exécutée pour générer les informations affichées dans ce carré. Excellent, non ?
Avec cette aide en matière de sensibilisation opérationnelle, commençons à explorer exactement les éléments que nous souhaitons superviser pour améliorer notre fiabilité.