La hiérarchie de la fiabilité de Dickerson
Le schéma pour le parcours d’apprentissage Améliorer votre fiabilité est basé sur un modèle de l’ingénierie de fiabilité des sites, appelé Hiérarchie de la fiabilité de Dickerson. Mikey Dickerson était un ingénieur de la fiabilité des sites, qui est devenu l’administrateur fondateur de United States Digital Services. Il a créé cette hiérarchie en faisant face à l’une des plus grandes crises de fiabilité de tous les temps.
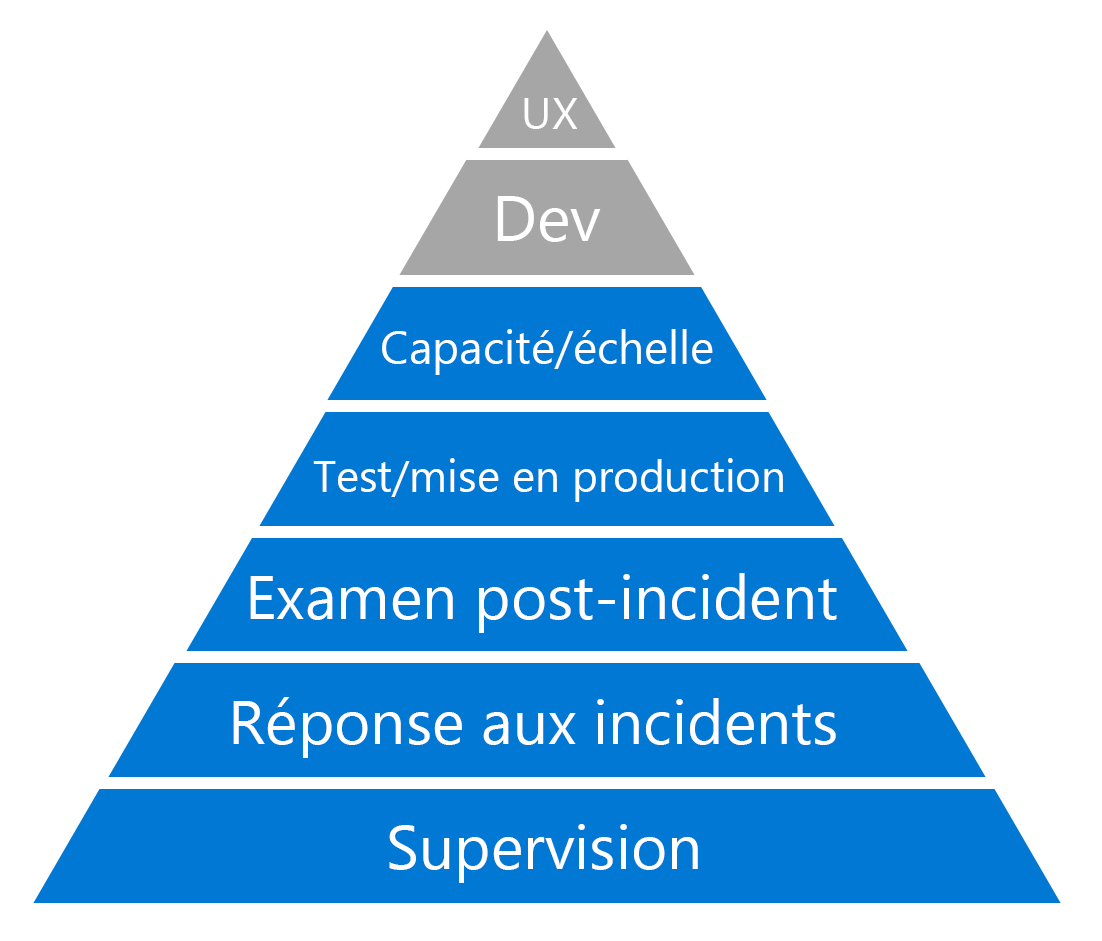
Le modèle est calqué sur la hiérarchie des besoins d’Abraham Maslow, qui schématise les motivations des êtres humains. Comme avec la hiérarchie de Maslow, pour progresser dans la hiérarchie, il faut s’assurer que chaque niveau inférieur a été abordé en premier. Les niveaux sur lesquels nous allons nous concentrer sur ce parcours d’apprentissage, sont les suivants, de bas en haut :
Supervision
Ce niveau est le fondement important sur lequel les autres niveaux s’appuient. C’est la source d’informations qui vous permet d’avoir des conversations concrètes sur la fiabilité de votre organisation, autour de données objectives. Quand vous faites des modifications, cette pratique vous permet d’en connaître l’effet. En d’autres termes, cette pratique vous permet de savoir si les choses s’améliorent ou non. Tant que votre analyse n’est pas solidement établie, vous ne pouvez pas faire le reste du travail.
Réponse aux incidents
Chaque environnement de production connaît une interruption de service de quelque sorte. Ce fait est incontestable. Les questions deviennent alors « que faire quand un incident se produit ? Que se passe-t-il quand les systèmes sont indisponibles et que les clients sont impactés ? » Vous avez besoin d’un processus standard qui est efficace pour caractériser le problème, obtenir que les ressources appropriées soient engagées, puis atténuer le problème. En même temps, vous voulez aussi être sûr que vous communiquez avec des parties prenantes du problème.
Révision après incident (apprentissage suite à un échec)
Ce processus nous permet de faire passer au niveau supérieur nos pratiques opérationnelles en investiguant collectivement, en révisant et en discutant de l’expérience de chaque incident significatif. L’évaluation après incident nous permettent d’apprendre des échecs et sont essentielles pour garantir la fiabilité.
Test/mise en production (déploiement)
Le niveau suivant est axé sur nos processus de test, de mise en production et de déploiement. Vous pouvez penser ce niveau dans ces termes : « à quel point nous sommes capable de créer des systèmes et des processus qui peuvent détecter les problèmes avant qu’ils ne causent des incidents ? »
Planification/mise à l’échelle des capacités
La réussite et la croissance qui l’accompagne peuvent s’avérer être une menace pour la fiabilité, tout comme d’autres problèmes relatifs à un système. Un client ne peut pas voir la différence entre un système défaillant dû à un bogue dans le code et un système défaillant dû à un trop grand nombre de personnes qui essaient d’y accéder en même temps. Ce niveau de la hiérarchie nous incite à faire attention à la planification et à la mise à l’échelle des capacités pour faire face à cette menace.
Processus de développement et expérience utilisateur
Il y a deux niveaux supplémentaires dans la hiérarchie qui ne sont pas traités dans le parcours d’apprentissage Améliorer votre fiabilité : le processus de développement et le travail qui consiste à offrir une bonne expérience utilisateur (UX). Ces deux sujets ne sont pas abordés dans le parcours d’apprentissage “Améliorez votre fiabilité” ; d’autres modules Learn intéressants sont disponibles sur ces sujets.
Nous avons créé un module Learn distinct pour chaque niveau de la hiérarchie de fiabilité. Nous espérons que vous participerez aux cinq modules de ce parcours d’apprentissage.