Correction
Diviser le cycle de vie de la réponse aux incidents en cinq phases, comme vous l’avez vu dans ce module, vous aide à comprendre le processus, mais les phases ne sont pas toujours aussi distinctes qu’elles en ont l’air dans le diagramme. Plus particulièrement, la séparation entre les phases de réponse et de correction devient souvent floue. Cela se vérifie particulièrement quand des actions prévues pour atténuer ou améliorer la situation ont un effet inverse. Dans ce cas, les phases de réponse et de correction ont tendance à se chevaucher ou à faire des allers-retours entre elles.
Dans cette unité, vous allez découvrir la phase de correction et les étapes qui la composent, ainsi que des conseils et des outils utiles. Notez ce point important : ne considérez pas les mesures décrites ici comme une liste de vérification normative.
Si vous avez déjà une check-list en place pour la correction, cela indique souvent qu’il est temps d’intégrer une certaine automatisation. Quand vous pouvez décrire exactement ce qui doit être fait et dans quel ordre pour corriger un problème, c’est alors le bon moment pour enseigner ces étapes à une machine afin que le système puisse le faire à votre place.
Où commencer
Vous avez découvert l’importance de réduire le temps nécessaire pour répondre à un incident. Examinons à présent quelques éléments qui peuvent vous aider à accélérer le processus de correction ou de résolution du problème.
Les différents membres de l’équipe peuvent avoir des modes de pensée différents sur la façon dont les choses fonctionnent et leur opinion peut varier concernant la première chose à faire. Une personne peut d’abord examiner les journaux, quand une autre pourrait commencer par exécuter des requêtes et examiner les métriques. Il n’y a pas qu’un seul chemin qui mène à Rome.
En revanche, il s’avère utile de fournir du contexte et des instructions, ainsi que d’indiquer où aller et quels éléments examiner.
Comment faire remonter et à qui
Une question importante pour savoir comment déterminer votre point de départ pour la correction est la suivante : quand vous êtes bloqué, à qui pouvez-vous faire remonter le problème ? Vous devez essayer de vous décharger de certaines responsabilités sur l’équipe d’astreinte en général, pas seulement sur les équipes d’ingénierie des opérations ou de fiabilité du site. Il incombe à tous les membres de l’équipe de faire en sorte que les systèmes soient opérationnels pour remplir vos objectifs de fiabilité.
Quelles sont les ressources utiles aux premiers intervenants ?
La considération suivante consiste à déterminer ce que les premiers intervenants peuvent utiliser pour démarrer le processus. Il peut s’agir de métriques, journaux, requêtes, etc. Essayez de les inclure dans un classeur/guide de résolution des problèmes Azure, dans la mesure du possible. Nous en reparlerons dans un instant.
Il s’avère également utile de fournir des liens simples vers les ressources (souvent dans un guide de résolution des problèmes). Si votre objectif est de répondre au problème et de le corriger aussi rapidement que possible, aider les personnes à trouver les réponses aux questions sans avoir à rechercher le document ou l’URL nécessaire va accélérer le processus.
Mettre au courant les parties prenantes
Vous pouvez parfois être si concentré sur la résolution du problème que vous en oubliez que de nombreuses personnes ne sont pas impliquées directement dans la réponse à l’incident, mais qui ont tout de même besoin de savoir ce qui se passe.
Il est important de communiquer avec les membres des autres équipes internes et de les tenir informés de ce qui se passe lorsqu’un incident se produit. Si vous ne les tenez pas au courant systématiquement, ils risquent de vouloir vous contacter pour savoir ce qui se passe. Ils ont le droit d’accéder à ces informations, mais il vous faut un moyen plus efficace de les tenir informés du problème et de ce qui est fait pour y remédier.
Vous avez besoin de reconnaître ce droit de manière transparente pour vos équipes internes. Soyez clair quand vous faites part d’informations et de ce qui est effectué, et définissez le moment où vous reviendrez vers eux.
La formule pour vos communications aux parties prenantes est simple :
- Voici ce que nous savons.
- Voici ce que nous faisons.
- Nous reviendrons vers vous dans un délai de X.
Ainsi, vous éviterez que les parties prenantes vous contactent et vous interrompent au beau milieu de vos tentatives de résolution de problèmes.
Une façon de distribuer ces informations consiste à utiliser une page web de statut facilement modifiable comme celle que nous avons mentionnée dans la dernière unité. Dans de nombreux cas, vous préférerez peut-être utiliser une page de statut distincte et plus détaillée pour les parties prenantes internes et une page externe pour vos clients. La formule précédente fonctionne pour les deux cas.
Utiliser des classeurs et guides de résolution des problèmes Azure Monitor
Azure propose deux fonctionnalités étroitement liées qui peuvent s’avérer extrêmement utiles pour une équipe en phase de correction : Les classeurs Azure Monitor et les guides de résolution des problèmes Application Insights. Pour les besoins de ce module, ils sont interchangeables et présentent la même interface utilisateur. Vous trouverez des classeurs Azure Monitor dans le portail Azure sous Azure Monitor. Vous trouverez des guides de résolution des problèmes Azure Insights dans le portail Azure lorsqu’une instance Applications Insights est sélectionnée.
Vous pouvez considérer les classeurs et les guides de résolution des problèmes comme « documents dynamiques » que vous pouvez créer à l’aide d’une interface de création de page. Quand vous en créez un nouveau, vous pouvez ajouter à la page les éléments suivants :
- Texte libre comme une liste à puces d’éléments à faire ou autres informations utiles à toute personne qui consulte la page
- Liens vers d’autres systèmes, par exemple, vers d’autres tableaux de bord ou vers une documentation
- Des requêtes KQL (Kusto Query Language).
C’est ce dernier élément qui rend le document « dynamique ». Dans un précédent module de ce parcours d’apprentissage, nous avons examiné le langage de requête KQL intégré à Log Analytics et à d’autres composants d’Azure Monitor. En utilisant ce langage, nous pourrions écrire nos propres requêtes pour retourner et afficher des informations de diagnostic à partir de notre application et de notre infrastructure Azure. Quand une requête KQL est insérée dans un classeur ou un guide de résolution des problèmes, les résultats actualisés de cette requête sont présentés en temps réel auprès des lecteurs du document. Cela signifie que votre guide de résolution des problèmes peut non seulement indiquer de « vérifier le taux d’erreur sur le serveur web », mais il peut également montrer un graphique actualisé de ce taux d’erreur en regard des instructions. Il peut comporter un lien vers la « documentation sur le redémarrage du serveur web » qui permet au premier intervenant d’accéder directement à la documentation dont il a besoin.
Azure fournit également des modèles existants pour vous aider à bien démarrer avec la création de vos propres documents. Voici une capture d’écran de certains des modèles prédéfinis qui vous seront éventuellement proposés :
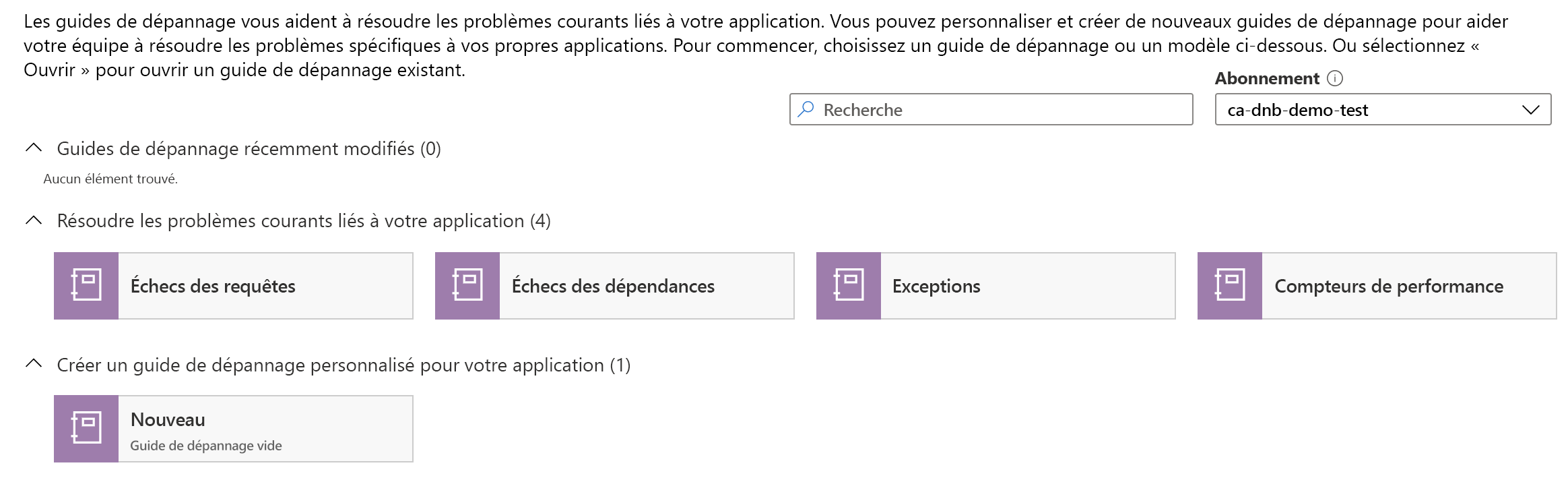
Il existe une fonctionnalité d’éditeur avancé pour les classeurs et les guides de résolution des problèmes qui vous permet d’accéder à une représentation de modèle JSON ou Azure Resource Manager de ce document afin de l’insérer. Cela signifie qu’il est possible de suivre et de distribuer ces documents à l’aide du système de contrôle de code source de votre choix. Vous avez aussi la possibilité d’automatiser l’approvisionnement des classeurs ou des guides de dépannage, ce qui est utile quand vous approvisionnez une autre infrastructure. Grâce à cette pratique recommandée, créer un ensemble de documents de résolution des problèmes personnalisés pour un nouveau service au moment où le service est approvisionné devient facile à faire.
Autres outils et conseils utiles
Tout au long de ce module, vous avez découvert les différents outils et raccourcis que vous pouvez utiliser pour augmenter l’efficacité et réduire le temps de réponse de votre incident. Pour conclure cette dernière unité, nous allons présenter brièvement certains outils et certaines techniques utiles pour diagnostiquer les problèmes au sein de vos systèmes.
- Utilisez le lien Tableau de bord de l’application dans Application Insights pour générer automatiquement un tableau de bord qui contient la plupart des éléments clés dont vous aurez besoin pour démarrer. Notez qu’il n’inclut pas Azure Service Health. Vous devez épingler ce dernier à votre tableau de bord pour pouvoir vérifier si le problème est lié à vos systèmes ou au service cloud lui-même.
- Utilisez la cartographie d’application dans Application Insights pour rechercher la cause précise des problèmes. Vous pouvez suivre les barres de navigation pour trouver la cause de l’erreur (par exemple, une URL incorrecte).
- Utilisez Log Analytics pour interroger n’importe quelle partie du système.
Tous ces outils sont extrêmement précieux lors de la résolution de problèmes.