Automatisation des tests et pipeline de livraison
Vous avez découvert le déploiement et la livraison continus de logiciels et de services, mais ces deux aspects font en fait partie d’un trio. Les pratiques DevOps ciblent trois opérations : intégration continue, déploiement continu et livraison continue.
Revenons au premier aspect : l’intégration. Elle fait partie du processus de développement qui précède le déploiement. DevOps recommande une pratique de développement dans laquelle les membres de l’équipe intègrent fréquemment du code dans un dépôt partagé contenant un code base « principal » singulier. L’objectif est de permettre à tout le monde de contribuer au code qui sera livré par opposition à un travail individuel qui sera rassemblé uniquement à la dernière minute.
Les tests automatisés peuvent ensuite vérifier l’intégration de chaque membre de l’équipe. Ces tests permettent de déterminer si le code est « sain », une fois que tous les changements et ajouts ont été effectués. Les tests font partie de ce que nous appellerions un pipeline. Nous aborderons les pipelines un peu plus loin, car cette unité sera axée sur les pipelines de test et de livraison intégrés.
Pipeline de livraison continue
Pour comprendre le rôle des tests automatisés dans le modèle de déploiement de livraison continue, vous devez voir où il s’intègre dans le pipeline de livraison. Un pipeline de livraison continue est l’implémentation de l’ensemble des étapes du code au fur et à mesure que des changements sont apportés durant le processus de développement et avant le déploiement en production. Voici une représentation graphique d’exemples d’étapes dans un pipeline de livraison simplifié :
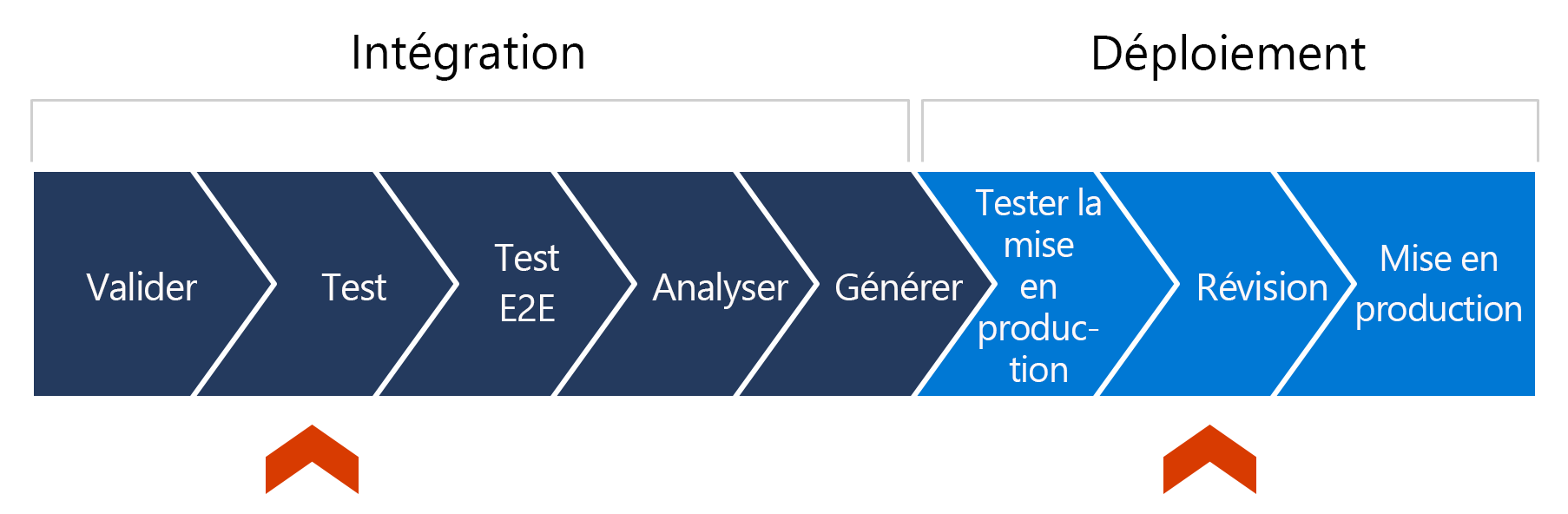
Passons en revue ce pipeline étape par étape.
Une instance du pipeline démarre au fur et à mesure que les changements apportés au code ou à l’infrastructure sont commités dans un dépôt de code, éventuellement à l’aide d’une demande de tirage (pull request).
Des tests unitaires sont ensuite exécutés, par exemple des tests d’intégration ou des tests de bout en bout, et dans l’idéal les résultats de ces tests sont communiqués à la partie qui les demande.
À ce stade, le code du dépôt fait éventuellement l’objet d’analyses permettant de rechercher les secrets, les vulnérabilités et les aspects de la configuration.
Une fois que tout est vérifié, le code est généré et préparé au déploiement.
Le code est ensuite déployé sur un environnement de test. Une notification relative au nouveau déploiement peut éventuellement être envoyée à une personne spécifique pour qu’elle jette un œil à la solution de préproduction. Cette personne peut ensuite approuver ou refuser le déploiement en production, dernière partie du processus de déploiement qui démarre la mise en production du code.
Dans ce pipeline, vous pouvez remarquer la délimitation entre l’intégration et le déploiement. Les marqueurs rouges indiquent certains emplacements logiques où vous pouvez arrêter le pipeline via une logique et une automatisation incluses, voire une intervention humaine.
Outils d’intégration et de livraison continues : Azure Pipelines
Pour utiliser l’intégration continue et la livraison continue, vous avez besoin des outils appropriés. Azure Pipelines fait partie d’Azure DevOps Services, qui vous permet d’automatiser la génération et le test cohérent de votre code. Vous pouvez également utiliser Azure Pipelines pour déployer du code sur les services, les machines virtuelles et d’autres cibles Azure, à la fois dans le cloud et en local.
L’entrée dans un pipeline (notre code ou nos configurations) réside dans un système de gestion de versions, par exemple GitHub ou tout autre fournisseur Git.
Azure Pipelines exécuté sur un élément de calcul, par exemple une machine virtuelle ou un conteneur, offre des agents de build exécutant Windows, Linux et macOS. Il offre également une intégration avec les plug-ins de test, de sécurité et de qualité du code. Pour finir, il est facilement extensible pour que vous puissiez apporter votre propre automatisation dans Azure Pipelines.
Les pipelines sont définis à l’aide de la syntaxe YAML ou via l’interface utilisateur classique du portail Azure. Quand vous utilisez un fichier YAML, vous pouvez stocker ce fichier avec votre code. Les pipelines fournissent également des modèles que vous pouvez utiliser pour créer facilement des pipelines, par exemple un pipeline qui génère une image Docker ou un projet Node.js. Vous pouvez également réutiliser un fichier YAML existant.
Que vous utilisiez un fichier YAML ou l’interface classique, voici les étapes de base :
- Configurez Azure Pipelines pour utiliser votre dépôt Git.
- Définissez votre build, soit en modifiant le fichier azure-pipelines.yml, soit à l’aide de l’éditeur classique.
- Poussez (push) votre code vers votre dépôt de gestion de versions. Cette action déclenche le pipeline de build et de test de votre code.
Une fois le code mis à jour, généré et testé, vous pouvez le déployer sur la cible de votre choix.
Certaines fonctionnalités (telles que l’exécution de travaux de conteneur) sont disponibles uniquement quand vous utilisez YAML, tandis que d’autres (telles que les groupes de tâches) sont disponibles uniquement via l’interface classique.
Construction d’un pipeline Azure
Les pipelines sont structurés en :
Travaux : un travail est un regroupement de tâches ou d’étapes qui s’exécute sur un seul agent de build. Un travail est la plus petite partie d’une activité dont vous pouvez planifier l’exécution. Toutes les étapes d’un travail s’exécutent de manière séquentielle. Ces étapes peuvent correspondre à n’importe quelle sorte d’action, notamment la génération/compilation de logiciels, la préparation d’échantillons de données à des fins de test, l’exécution de tests spécifiques, etc.
Phases : une phase est un regroupement logique de travaux associés.
Chaque pipeline a au moins une phase. Utilisez plusieurs phases pour organiser le pipeline en divisions principales, puis marquez les points de votre pipeline où vous pouvez effectuer des interruptions et des vérifications.
Les pipelines peuvent être aussi simples ou complexes que vous le souhaitez. Il existe d’excellents tutoriels dédiés à la construction et l’utilisation de pipelines dans le parcours d’apprentissage Générer des applications avec Azure DevOps.
Traçabilité de l’environnement
Il existe un autre aspect des pipelines lié à la fiabilité, et qui mérite d’être mentionné. Vous pouvez construire vos pipelines de façon à permettre la corrélation des éléments exécutés en production avec une instance de build spécifique. Dans l’idéal, nous devons pouvoir tracer une build jusqu’à une demande de tirage (pull request) ou un changement de code spécifique. Cela peut s’avérer très utile pendant un incident ou par la suite durant la révision post-incident, quand vous essayez d’identifier le changement impliqué dans l’apparition d’un problème. Certains systèmes CI/CD (par exemple Azure Pipelines) facilitent cette tâche, tandis que d’autres nécessitent que vous construisiez manuellement un pipeline qui propage une sorte d’« ID de build » dans l’ensemble des phases.