Choisir une stratégie de flux de code
Il est important de choisir une stratégie de flux de code qui corresponde à la façon dont votre équipe travaille. Il existe plusieurs stratégies à prendre en compte. À la fin du module, vous pourrez explorer les options. L'équipe web de Tailspin décide de développer une stratégie de flux de code basée sur Git et GitHub.
Quand Mara a configuré Azure Boards, l’équipe et elle-même ont identifié quelques tâches initiales à traiter. Une tâche consistait à créer un workflow basé sur Git.
Écoutons l’équipe au fur et à mesure qu’elle cherche une meilleure façon de collaborer. Actuellement, elle utilise un système de contrôle de version centralisé, le but étant de passer à Git, un système distribué.
Alors que Mara travaille assidument sur les fonctionnalités qui lui sont attribuées, Andy entre.
Andy : Bonjour Mara. Ce matin, au cours de la réunion avec la direction, il a été signalé que notre équipe et l'équipe de développement de jeux utilisent des systèmes de gestion de versions différents. Pour simplifier la façon dont nous partageons les ressources entre les équipes, il nous a été demandé de passer à un système de gestion de versions distribué qui peut mieux gérer la collaboration.
Mara : C’est bon à savoir. Comme vous vous en souvenez peut-être, nous avions inscrit ce point dans notre tableau. Nous utilisons un système de gestion de versions centralisé. Il nous convient parfaitement, mais je suis d'accord avec le fait qu'un système de gestion de versions distribué est un choix plus approprié quand nous commençons à partager des ressources avec d'autres équipes et que notre équipe s'agrandit. Notre tableau comporte également une tâche visant à augmenter la visibilité afin que toutes les parties prenantes sachent ce que tout le monde fait. Je pense qu'un système de contrôle de code source distribué, comme Git, pourrait également s'avérer utile.
Andy : Je souhaiterais effectivement essayer Git. Mais il semble que je n’en ai jamais eu le temps. Est-il difficile à apprendre ou à configurer ? Si cela semble raisonnable, peut-être pourrions-nous travailler dessus maintenant. Je suis fatigué de remettre systématiquement les choses à plus tard. Et il serait agréable de pouvoir voir ce que tout le monde fait et d’avoir accès à l’ensemble du dépôt. Bon, de quoi s’agit-il ?
Mara : Je vais vous expliquer. Vous pourrez ensuite décider s’il vous semble bien de l’implémenter tout de suite.
Mara et Andy passent au tableau blanc afin de discuter de la gestion de versions.
Qu’est-ce que Git et la gestion de versions distribuée ?

Mara : Le dessin de gauche illustre la gestion de versions centralisée, à l’image de ce que nous utilisons aujourd’hui. Nous avons une version centrale du codebase  dans TFVC (Team Foundation Version Control) que tout le monde utilise. Nous travaillons chacun sur les fichiers que nous devons changer, puis nous les fusionnons dans le dépôt principal quand nous avons terminé.
dans TFVC (Team Foundation Version Control) que tout le monde utilise. Nous travaillons chacun sur les fichiers que nous devons changer, puis nous les fusionnons dans le dépôt principal quand nous avons terminé.
Andy : Oui, et cela fonctionne pour nous. Bon, sauf quand j’ai été bloqué la fois où un changement cassant a été fusionné dans le dépôt central.
Mara : Oui ! Vous avez été bloqué  . Nous pourrions utiliser une stratégie de branchement avec TFVC pour résoudre le problème de blocage, mais dans notre configuration actuelle, la fusion pourrait devenir un peu plus compliquée. À la suite de cette rupture
. Nous pourrions utiliser une stratégie de branchement avec TFVC pour résoudre le problème de blocage, mais dans notre configuration actuelle, la fusion pourrait devenir un peu plus compliquée. À la suite de cette rupture  , personne ne pouvait travailler tant que le problème n'était pas résolu. Ce problème est toujours latent, car nous utilisons tous la même copie du code.
, personne ne pouvait travailler tant que le problème n'était pas résolu. Ce problème est toujours latent, car nous utilisons tous la même copie du code.
Sur la droite se trouve un dessin illustrant la gestion de versions distribuée. Nous disposons toujours d'un référentiel central  qui constitue la version stable de la base de code, dont chaque développeur dispose de sa propre copie
qui constitue la version stable de la base de code, dont chaque développeur dispose de sa propre copie  pour travailler. Cela nous permet d’expérimenter et de tester diverses approches sans affecter le dépôt central.
pour travailler. Cela nous permet d’expérimenter et de tester diverses approches sans affecter le dépôt central.
La gestion de versions distribuée garantit également que seul le code de travail  est fusionné dans le dépôt central. Nous pourrions même la configurer de manière à ce que le code ne puisse pas être fusionné tant qu’il n’a pas été revu.
est fusionné dans le dépôt central. Nous pourrions même la configurer de manière à ce que le code ne puisse pas être fusionné tant qu’il n’a pas été revu.
La particularité d'Azure DevOps est qu'il fonctionne aussi bien avec des systèmes de contrôle de version centralisés qu'avec des systèmes de contrôle de version distribués.
Andy : Que se passe-t-il quand plusieurs personnes changent le même fichier ?
Mara : Souvent, Git peut fusionner automatiquement plusieurs modifications. Bien entendu, nous voulons nous assurer systématiquement que la combinaison des modifications aboutit à du code opérationnel. Quand Git ne peut pas fusionner automatiquement les modifications, il marque les conflits directement dans les fichiers afin qu’un utilisateur puisse choisir les modifications à accepter.
Andy : Pour le moment, notre code est stocké sur notre propre serveur. Si nous passons à l’utilisation du contrôle de version distribué, où le code sera-t-il stocké ?
Mara : C’est une très bonne question. C’est là qu’intervient l’hébergement.
Où héberger mon dépôt ?
Mara : Quand nous décidons de l’emplacement où sont hébergés nos dépôts, nous avons plusieurs options. Par exemple, nous pouvons les héberger sur un serveur local, dans Bitbucket ou dans GitHub. Bitbucket et GitHub sont des solutions d’hébergement basées sur le web. Nous pouvons y accéder depuis n’importe où.
Andy : Avez-vous utilisé l’un ou l’autre ?
Mara : j’ai utilisé GitHub par le passé. Il présente des caractéristiques importantes pour les développeurs, comme un accès facile aux journaux des modifications et aux fonctions de contrôle des versions, que ce soit à partir de la ligne de commande ou du portail en ligne.
Andy : Comment fonctionne Git ?
Comment utiliser Git ?
Mara : Comme je l’ai déjà mentionné, avec les systèmes distribués, les développeurs peuvent accéder à n’importe quel fichier dont ils ont besoin sans affecter le travail des autres développeurs, car ils disposent de leur propre copie du dépôt. Un clone est votre copie locale d’un dépôt.
Quand nous travaillons sur une fonctionnalité ou un correctif de bogue, nous voulons généralement essayer différentes approches jusqu’à ce que nous trouvions la meilleure solution. Cependant, il n'est pas conseillé d'essayer du code sur votre copie de la base de code principale, car vous ne voudrez peut-être pas conserver les premiers essais.
Git met à votre disposition une meilleure option, au travers d’une fonctionnalité appelée « branchement », qui vous permet de conserver autant de copies que vous le souhaitez et de fusionner uniquement celle que vous voulez conserver. Ainsi, la branche primaire demeure stable.
Andy : Jusque là, je comprends les concepts. Comment archiver mon code ?
Comment mes modifications locales sont-elles répercutées dans le codebase principal ?
Mara : Dans Git, la branche par défaut, ou tronc, est généralement appelée main.
Quand vous pensez que votre code est prêt à être fusionné dans la branche main du dépôt central qui est partagé par tous les développeurs, vous créez ce que l’on appelle une demande de tirage (pull request). Quand vous créez une demande de tirage, vous indiquez aux autres développeurs que vous avez du code prêt à être revu et que vous souhaitez le fusionner dans la branche main. Quand votre demande de tirage est approuvée et fusionnée, elle est intégrée au codebase central.
À quoi ressemble un workflow de branchement ?
Étape 1 : Quand vous commencez à travailler sur une nouvelle fonctionnalité ou un correctif de bogue, la première chose à faire est de vous assurer que vous commencez avec le dernier codebase stable. Pour ce faire, vous pouvez synchroniser votre copie locale de la branche main avec la copie du serveur. Cette opération permet de récupérer dans votre copie locale toutes les autres modifications des développeurs qui ont été envoyées à la branche main sur le serveur depuis votre dernière synchronisation.
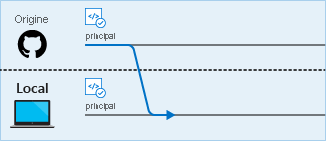
Étape 2 : Pour vous assurer que vous travaillez seulement sur votre copie du code, vous créez une branche uniquement pour cette fonctionnalité ou ce correctif de bogue. Comme vous pouvez l’imaginer, il peut être difficile de retenir toutes les branches créées pour toutes les tâches en cours. Il est donc essentiel d’utiliser une bonne convention de nommage.
Avant d’apporter des modifications à un fichier, vous pouvez extraire une nouvelle branche afin de savoir que vous travaillez sur les fichiers de cette branche et non d’une branche différente. Vous pouvez changer de branche à tout moment en extrayant la branche concernée.
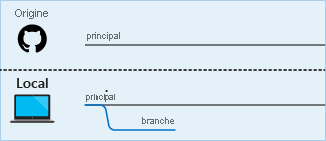
Étape 3 : Vous pouvez désormais effectuer toutes les modifications que vous souhaitez, car celles-ci ne se trouvent que dans votre branche. À mesure que vous travaillez, vous pouvez valider vos modifications dans votre branche pour éviter de perdre du travail et avoir la possibilité de restaurer les modifications que vous avez apportées aux versions précédentes. Avant de pouvoir commiter des modifications, vous devez indexer vos fichiers afin que Git sache quels sont celles que vous êtes prêt à commiter.
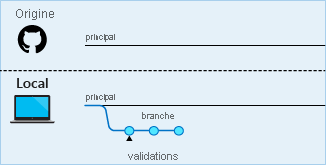
Étape 4 : L’étape suivante consiste à pousser, ou charger, votre branche locale vers le dépôt distant (par exemple, GitHub) afin que d’autres personnes puissent voir ce sur quoi vous travaillez. Ne vous inquiétez pas, cette opération ne fusionne pas encore vos modifications. Vous pouvez pousser votre travail aussi souvent que vous le souhaitez. En réalité, c'est un bon moyen de sauvegarder votre travail ou de vous permettre de travailler à partir de plusieurs ordinateurs.
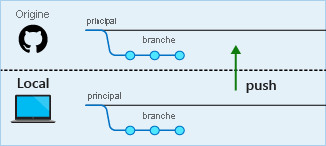
Étape 5 : Cette étape est courante, mais pas obligatoire. Quand vous êtes sûr que votre code fonctionne comme vous voulez, vous pouvez tirer (pull), ou fusionner, la branche main distante dans votre branche main locale. Des modifications y ont été apportées, dont ne dispose pas encore votre branche main locale. Une fois que vous avez synchronisé la branche main distante avec la vôtre, fusionnez votre branche main locale dans votre branche de travail et retestez votre build.
Vous pouvez ainsi vous assurer que votre fonctionnalité marche avec le code le plus récent, et que votre travail s’intègre correctement quand vous envoyez votre demande de tirage.
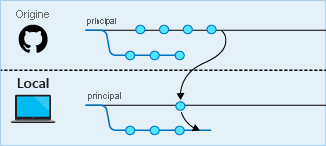
Étape 6 : Votre code local doit maintenant être commité et poussé vers le dépôt hébergé. Cette étape est identique aux étapes 3 et 4.
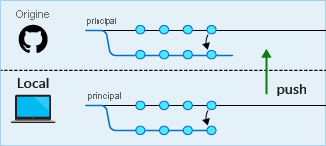
Étape 7 : Vous êtes enfin prêt à proposer vos modifications à la branche main distante. Pour ce faire, vous commencez une demande de tirage. Quand elle est configurée dans Azure Pipelines ou un autre système CI/CD, cette étape déclenche le processus de génération et vous pouvez observer le déplacement de vos modifications dans le pipeline. Une fois la génération réussie et votre demande de tirage approuvée par d’autres personnes, votre code peut être fusionné dans la branche main distante. (Il revient toujours à une personne de fusionner les modifications.)
Andy : Tout cela semble compliqué et difficile à apprendre.
Mara : Le Git peut sembler intimidant parce qu'il est très puissant, mais une fois que l'on a pris le rythme, il devient naturel.
Au quotidien, vous vous servez seulement de quelques commandes. Voici un résumé :
| Catégorie | Pour effectuer cette tâche | Utiliser cette commande |
|---|---|---|
| Gestion du dépôt | Créer un dépôt Git | git init |
| Télécharger un dépôt distant | git clone |
|
| Branche | Créer une branche | git checkout |
| Indexer et commiter des modifications | Voir quels fichiers ont été modifiés | git status |
| Indexer les fichiers à commiter | git add |
|
| Commiter les fichiers dans votre branche | git commit |
|
| Synchronisation à distance | Télécharger une branche à partir d’un dépôt distant | git pull |
| Charger une branche sur un dépôt distant | git push |
Andy : Cela ressemble à un excellent point de départ. Je peux sans aucun doute m’en occuper. Je peux apprendre des commandes plus avancées quand j’en ai besoin.