Explorer Microsoft Dataverse
Microsoft Dataverse est une solution cloud qui structure facilement diverses données et une logique métier pour prendre en charge les applications et processus interconnectés de manière sécurisée et conforme. Gérée et maintenue par Microsoft, Dataverse est disponible dans le monde entier mais déployée géographiquement pour se conformer à votre résidence potentielle de données. Elle n’est pas conçue pour une utilisation autonome sur vos serveurs, donc vous avez besoin d’une connexion Internet pour y accéder et l’utiliser.
Dataverse est différente des bases de données traditionnelles en ce qu’elle ne se résume pas à des tables. Elle intègre la sécurité, la logique, les données et le stockage à un emplacement central. Elle est conçue pour être votre référentiel de données central pour les données métier, et vous l’utilisez peut-être déjà. En arrière-plan, elle optimise de nombreuses solutions Microsoft Dynamics 365 telles que Field Service, Customer Insights, Customer Service et Sales. Elle est également disponible dans le cadre de Power Apps et Power Automate avec une connectivité native intégrée. Les fonctionnalités AI Builder et Portails de Microsoft Power Platform utilisent également Dataverse.
L’image illustre une visualisation rassemblant les nombreuses offres de Microsoft Dataverse :
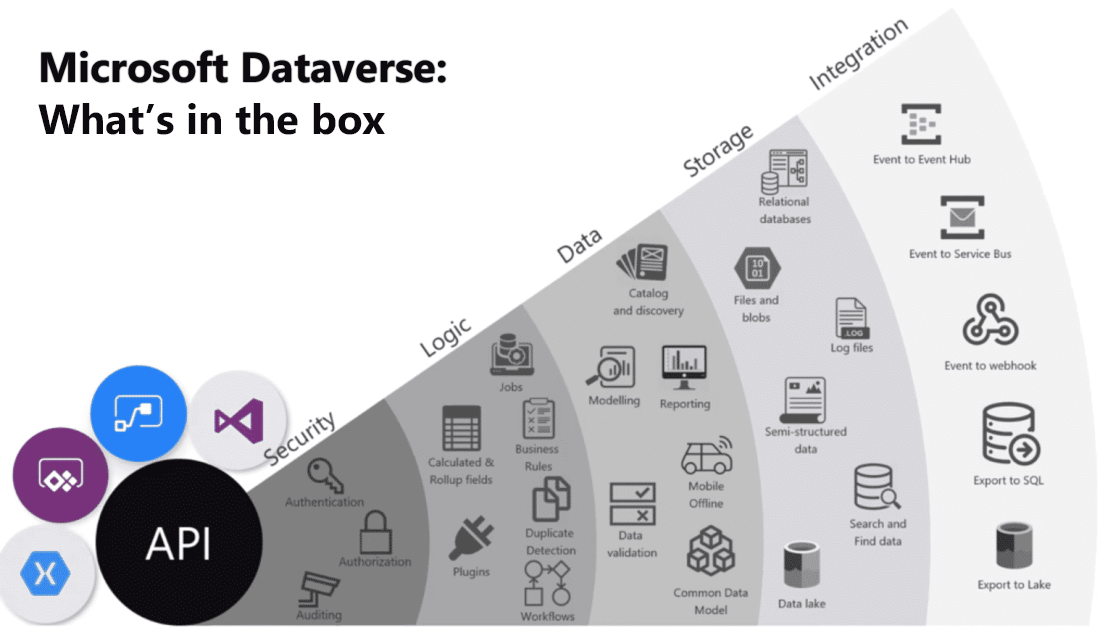
Voici une brève explication de chaque catégorie de fonctionnalités :
Sécurité : Dataverse gère l’authentification avec Azure Active Directory (Azure AD) pour permettre l’accès conditionnel et l’authentification multifacteur. Elle prend en charge l’autorisation jusqu’au niveau de la ligne et de la colonne et fournit de riches fonctionnalités d’audit.
Logique : Dataverse vous permet d’appliquer facilement une logique métier au niveau des données. Quel que soit le mode d’interaction d’un utilisateur avec les données, les mêmes règles s’appliquent. Ces règles peuvent être liées à la détection des doublons, aux règles métier, aux flux de travail, etc.
Données : Dataverse vous offre le contrôle nécessaire pour façonner vos données, vous permettant ainsi de découvrir, modéliser, valider et générer des états sur vos données. Ce contrôle garantit que vos données ont l’aspect que vous souhaitez, quel que soit leur mode d’exploitation.
Stockage : Dataverse stocke vos données physiques dans le cloud Azure. Ce stockage cloud élimine le souci de l’emplacement de vos données ou de leur évolutivité. Toutes ces préoccupations sont traitées pour vous.
Intégration : Dataverse se connecte de différentes manières pour répondre à vos besoins métier. Les API, les webhooks, les événements et les exportations de données vous permettent de gérer des données entrantes et sortantes.
Comme vous pouvez le voir, Microsoft Dataverse est une puissante solution cloud vous permettant de stocker et d’utiliser vos données métier. Dans les sections suivantes, vous allez examiner Microsoft Dataverse sous l’angle du stockage de données pour Microsoft Power Platform, où vous commencez votre parcours. Gardez à l’esprit les autres fonctionnalités enrichies abordées, que vous pouvez explorer davantage à mesure que votre utilisation augmente.
Pour commencer, Microsoft Dataverse vous permet de créer une ou plusieurs instances cloud d’une base de données standardisée. La base de données comprend des tables et colonnes prédéfinis qui stockent des données que l’on trouve couramment dans la quasi-totalité des organisations et entreprises. Vous pouvez personnaliser et étendre ce qui est stocké en ajoutant de nouvelles colonnes ou tables. La facilité de configuration d’une base de données Microsoft Dataverse et du modèle de données standardisé sous-jacent simplifient votre capacité à concentrer vos efforts sur la création de solutions sans vous soucier de l’infrastructure, du stockage et de l’intégration des données. Une fois vos données stockées dans Microsoft Dataverse, de nombreux moyens vous permettent d’y accéder. Vous pouvez utiliser les données de manière native avec des outils tels que Power Apps ou Power Automate. Toute solution métier peut se connecter à Dataverse à l’aide d’API de connecteurs. Grâce à la puissance de fonctionnalités telles que la sécurité basée sur les rôles et les règles métier, vous pouvez être sûr que vos données sont protégées, quel que soit le mode d’accès.
Scalabilité
Une base de données Dataverse prend en charge des jeux de données volumineux et des modèles de données complexes. Les tables peuvent comporter des millions d’éléments et vous pouvez étendre le stockage dans chaque instance d’une base de données Microsoft Dataverse à 4 téraoctets. Le volume de données disponibles dans votre instance de Microsoft Dataverse est basée sur le nombre et le type de licences qui lui sont associées. Le stockage de données est mis en commun entre tous les utilisateurs disposant d’une licence, donc vous pouvez allouer de l’espace de stockage selon les besoins de chaque solution que vous créez. Un espace de stockage incrémental peut être acheté si vous avez besoin d’un espace de stockage supérieur à celui proposé dans le cadre de la licence standard.
Structure et avantages de Microsoft Dataverse
La structure d’une base de données Microsoft Dataverse est basée sur les définitions et le schéma de Common Data Model. L’utilisation de Common Data Model comme base d’une base de données Microsoft Dataverse simplifie l’intégration de solutions utilisant un schéma Common Data Model. En effet, Common Data Model est la base d’une base de données Microsoft Dataverse et utilise un schéma Common Data Model. Les tables standard de la solution sont les mêmes. Vous pouvez tirer parti d’un riche écosystème de solutions que les fournisseurs ont créé à partir de l’utilisation de Common Data Model. Mieux encore, l’extension d’une base de données Microsoft Dataverse est pratiquement illimitée.
Découvrir les tables, les colonnes et les relations
Une table est une structure logique comportant des lignes et colonnes représentant un jeu de données. Dans la capture d’écran, vous voyez la table Compte standard et divers éléments qui peuvent être gérés dans le cadre de celle-ci :
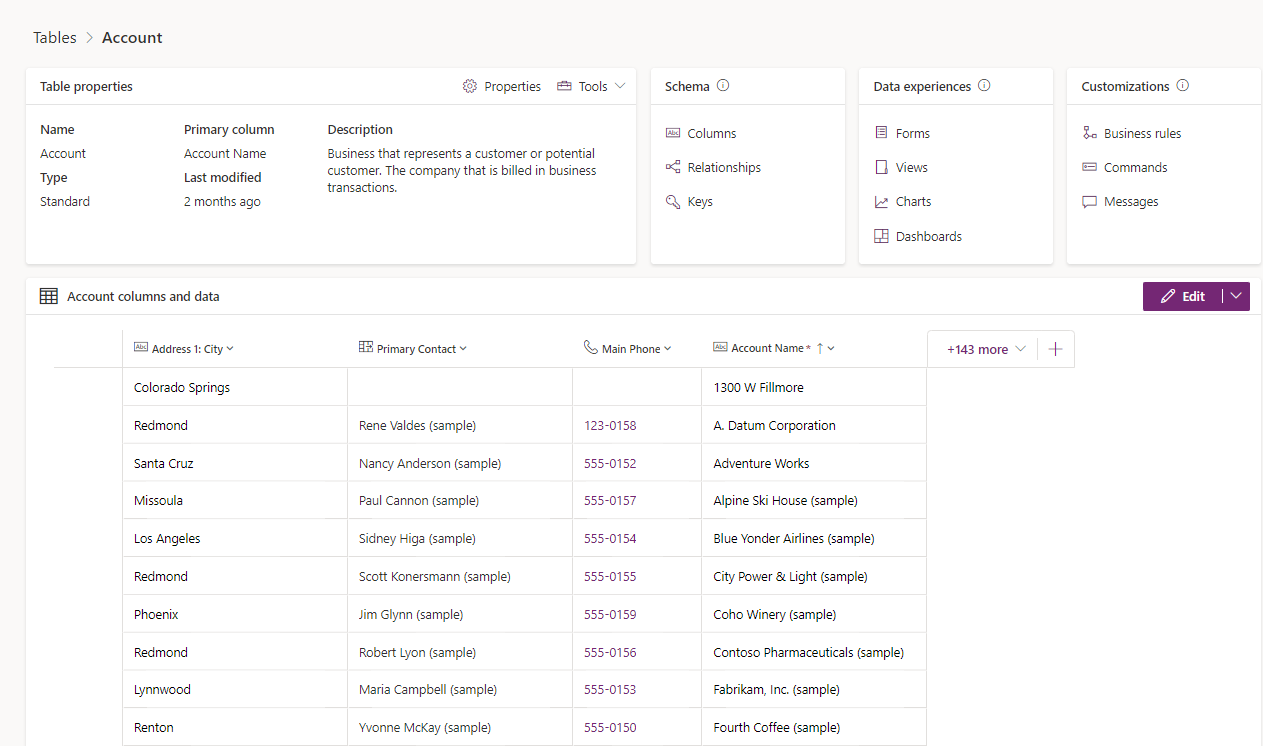
Types de tables
Voici les trois types de tables :
Standard : plusieurs tables standard, également appelées tables prêtes à l’emploi, sont fournies avec un environnement Dataverse. Les tables Compte, Centre de profit, Contact, Tâche et Utilisateur sont des exemples de tables standard dans Dataverse. La plupart des tables standard fournies avec Dataverse peuvent être personnalisées.
Gérée : tables non personnalisables et importées dans l’environnement dans le cadre d’une solution gérée.
Personnalisée : les tables personnalisées sont des tables non gérées qui sont soit importées à partir d’une solution non gérée, soit créées directement dans l’environnement Dataverse.
Colonnes
Les colonnes permettent de stocker une information discrète au sein d’une ligne dans une table. On peut les considérer comme une colonne dans Excel. Les colonnes ont des types de données. Autrement dit, vous pouvez stocker des données d’un certain type dans une colonne qui correspond à ce type de données. Par exemple, si vous avez une solution qui nécessite des dates, comme la capture de la date d’un événement, vous stockez la date dans une colonne avec le type Date. De même, si vous souhaitez stocker un nombre, vous le stockez dans une colonne avec le type Nombre.
Le nombre de colonnes au sein d’une table varie de quelques-unes à une centaine ou plus. Chaque base de données disponible dans Microsoft Dataverse commence par un ensemble standard de tables et chaque table standard dispose d’un ensemble standard de colonnes.
Comprendre les relations
Pour créer une solution efficace et évolutive pour la plupart des solutions que vous créez, vous devez répartir les données dans différents conteneurs (tables). Tenter de tout stocker dans un seul conteneur serait probablement inefficace et difficile à comprendre.
L’exemple suivant illustre ce concept.
Imaginez que vous devez créer un système pour gérer les commandes vente. Vous avez besoin d’une liste de produits avec le stock disponible, le coût de l’article et le prix de vente. Vous avez également besoin d’une liste principale de clients avec leurs adresses et cotes de crédit. Enfin, vous devez également gérer les factures vente pour stocker les données de facturation. La facture doit comprendre des informations telles que les suivantes :
date
numéro de facture
vendeur
informations client, y compris l’adresse et la cote de crédit
un élément de ligne pour chaque article de la facture
Chaque élément de ligne doit comprendre une référence au produit que vous avez vendu. L’élément de ligne doit également indiquer le coût et le prix appropriés pour chaque produit. Enfin, la ligne doit également diminuer la quantité disponible en fonction de la quantité que vous avez vendue dans cet élément de ligne.
Créer une seule table pour prendre en charge les fonctionnalités de l’exemple serait inefficace. Une meilleure façon d’aborder ce scénario métier consiste à créer les quatre tables suivantes :
Clients
Produits
Factures
Éléments de ligne
Créer une table pour chacun de ces éléments et les associer les unes aux autres vous permet de créer une solution efficace et évolutive tout en maintenant des performances élevées. Répartir les données dans plusieurs tables signifie également que vous n’avez pas à stocker de données répétitives ni à prendre en charge des lignes volumineuses avec de grandes quantités de données vides. Le reporting est également bien plus facile si vous répartissez les données dans des tables distinctes.
Les tables associées les unes aux autres ont une connexion relationnelle. Les relations entre les tables existent sous de nombreuses formes, mais les deux plus courantes sont les relations un-à-plusieurs et plusieurs-à-plusieurs, toutes deux prises en charge par Microsoft Dataverse. Pour en savoir plus sur les différents types de relations, consultez Relations de table.
Logique métier dans Microsoft Dataverse
De nombreuses organisations ont une logique métier qui impacte leur utilisation des données. Par exemple, une organisation qui stocke des informations client à l’aide de Dataverse peut souhaiter rendre obligatoire le champ Numéro d’identification. Dans Microsoft Dataverse, vous créez cette logique à l’aide de règles métier. Les règles métier vous permettent d’appliquer et de maintenir la logique métier au niveau de la couche de données au lieu de la couche d’application. En substance, lorsque vous créez des règles métier dans Microsoft Dataverse, elles sont en vigueur quel que soit l’endroit où les utilisateurs interagissent avec les données.
Par exemple, les règles métier permettent de définir ou d’effacer des valeurs dans une ou plusieurs colonnes d’une table au sein d’une application canevas ou pilotée par modèle. Elles permettent également de valider des données stockées ou d’afficher des messages d’erreur. Les applications pilotées par modèle peuvent afficher ou masquer des colonnes, activer ou désactiver des colonnes et créer des recommandations basées sur le décisionnel à l’aide de règles métier.
Les règles métier vous offrent un moyen puissant d’appliquer des règles, de définir des valeurs ou de valider des données, quel que soit le formulaire permettant de saisir des données. En outre, les règles métier contribuent efficacement à augmenter la précision des données, simplifier le développement d’applications et rationaliser les formulaires présentés aux utilisateurs finaux.
Prenons cet exemple d’utilisation simple et puissante des règles métier. La règle métier est configurée pour rendre le champ Approbateur VP du crédit autorisé obligatoire si le crédit autorisé est défini sur une valeur supérieure à $1,000,000. Si le crédit autorisé est inférieur à $1,000,000, le champ reste facultatif.
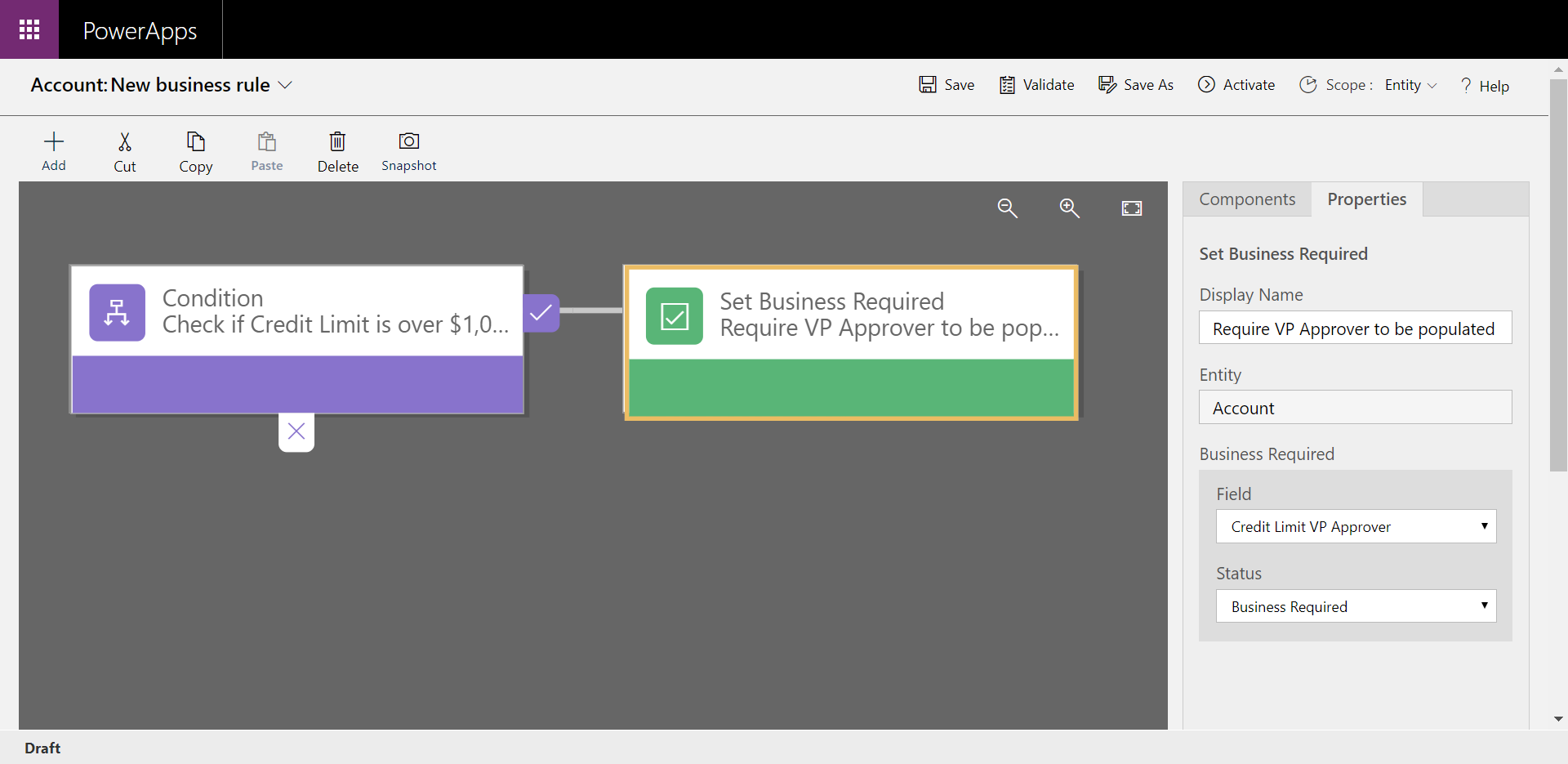
En appliquant cette règle métier au niveau des données plutôt qu’au niveau de l’application, vous contrôlez mieux vos données. Ainsi, votre logique métier est respectée, que vous y accédiez directement depuis Power Apps, Power Automate, voire au moyen d’une API. La règle est liée aux données, et non à l’application.
Pour en savoir plus sur l’utilisation de règles métier dans Dataverse, consultez Créer une règle métier pour une table.
Utilisation de flux de données
Les flux de données sont une technologie cloud en libre-service de préparation des données. Les flux de données permettent d’ingérer, de transformer et de charger des données dans des environnements Microsoft Dataverse, des espaces de travail Power BI ou le compte Azure Data Lake Storage de votre organisation. Les flux de données sont créés à l’aide de Power Query, une expérience de connectivité et de préparation des données déjà incluse dans de nombreux produits Microsoft, comme Excel et Power BI. Les clients peuvent déclencher des flux de données afin qu’ils s’exécutent soit à la demande, soit automatiquement selon un calendrier, les données étant toujours tenues à jour.
Comme un flux de données stocke les entités résultantes dans un stockage cloud, d’autres services peuvent interagir avec les données produites par les flux de données.
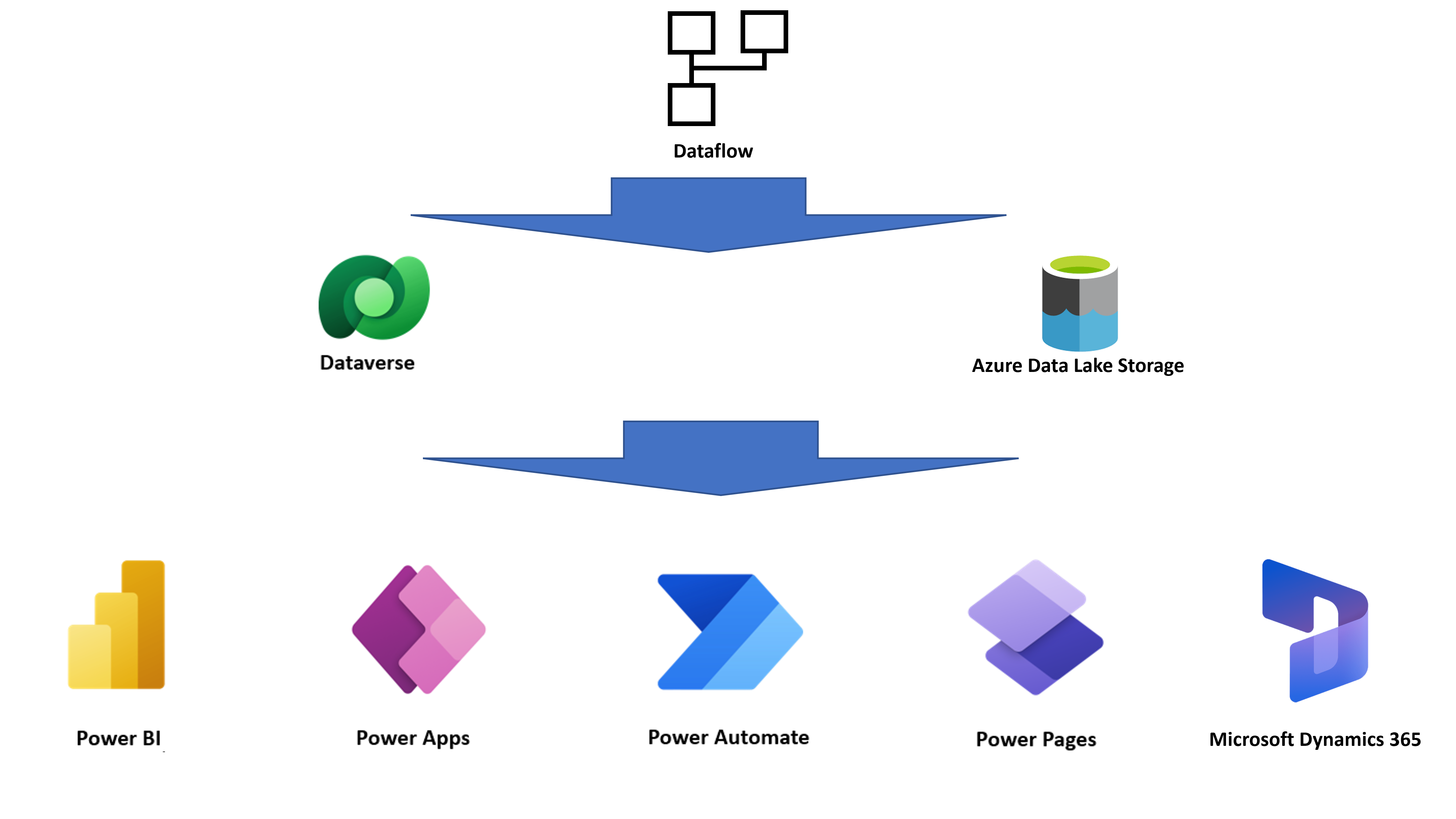
Par exemple, Power BI, Power Apps, Power Automate, Power Virtual Agents et les applications Dynamics 365 peuvent obtenir les données produites par le flux de données en se connectant à Dataverse, un connecteur de flux de données Power Platform. Ils peuvent également obtenir les données directement au moyen du lac, en fonction de la destination configurée au moment de la création du flux de données.
La liste suivante met en évidence certains des avantages de l’utilisation de flux de données :
Un flux de données dissocie la couche de transformation des données de la couche de modélisation et de visualisation dans une solution Power BI.
Le code de transformation des données peut résider dans un endroit central, un flux de données, au lieu d’être réparti entre plusieurs artefacts.
Un créateur de flux de données n’a besoin que de compétences Power Query. Dans un environnement avec plusieurs créateurs, le créateur du flux de données peut faire partie d’une équipe qui crée ensemble l’intégralité de la solution décisionnelle ou de l’application opérationnelle.
Un flux de données est indépendant du produit. Il ne s’agit pas uniquement d’un composant de Power BI, car vous pouvez obtenir ses données dans d’autres outils et services.
Les flux de données profitent d’une expérience Power Query puissante, graphique et en libre-service de transformation de données.
Les flux de données s’exécutent entièrement dans le cloud. Aucune autre infrastructure n’est requise.
Plusieurs options s’offrent à vous pour commencer à utiliser les flux de données, à l’aide de licences pour Power Apps, Power BI et Customer Insights.
Les flux de données permettent d’effectuer des transformations avancées, mais ils sont conçus pour les scénarios en libre-service et ne nécessitent aucune formation en informatique ou en développement.
Common Data Model
Lors de la création de solutions métier, vous devez souvent intégrer des données sur l’ensemble des différentes applications métier de votre organisation. Cette intégration inter-applications peut parfois s’avérer difficile. Bien que les données soient similaires, elles ne sont pas nécessairement stockées de la même manière dans différentes applications. Pour simplifier cette démarche, plusieurs leaders technologiques ont créé l’initiative Common Data Model. L’objectif est de disposer d’une structure commune facilement applicable dans différentes applications. Les organisations peuvent créer et partager leurs propres types et balises de données à l’aide de Common Data Model de Microsoft, qui dispose d’un système de métadonnées étendu. Cela permet de capturer de précieux insights métier, qui peuvent être intégrés et enrichis avec des données pour fournir des informations exploitables.
Avec Common Data Model, vous pouvez structurer vos données pour représenter des concepts et activités couramment utilisés et bien compris. Vous pouvez interroger et analyser ces données, les réutiliser et interagir avec d’autres entreprises et applications qui utilisent le même format. Les organisations peuvent créer et partager leurs propres types et balises de données à l’aide de Common Data Model de Microsoft, qui dispose d’un système de métadonnées étendu.
Au lieu de créer un modèle de données pour votre application, vous pouvez simplement utiliser les définitions de table à votre disposition. Common Data Model est utilisé par divers services et applications, notamment Microsoft Dataverse, Dynamics 365, Microsoft Power Platform et Azure. Ce point commun du modèle de données garantit que tous vos services peuvent accéder aux mêmes données. Les fonctionnalités de préparation des données dans les flux de données Power BI sont un bon exemple d’utilisation de Common Data Model. Ces flux de données créent des fichiers de données qui suivent la définition Common Data Model. Ces fichiers de données sont stockés dans Azure Data Lake. Les définitions Common Data Model sont ouvertes et disponibles pour tout service ou toute application qui souhaite les utiliser.

Les données décrites à l’aide de Common Data Model permettent de créer une solution d’analyse évolutive avec les services Azure. Il peut également s’agir d’une source de données sémantiquement riches pour les applications générant des insights exploitables, comme Dynamics 365 Customer Insights. Common Data Model permet de définir des entités pour les applications Dynamics 365 dans Sales, Finance, Supply Chain Management et Commerce, qui sont facilement disponibles dans Azure Data Lake.
Microsoft continue d’étendre Common Data Model en collaboration avec de nombreux partenaires et experts techniques. En créant des accélérateurs sectoriels, Microsoft permet aux secteurs suivants de bénéficier de Common Data Model et des plateformes qui le prennent en charge :