Exigences relatives à l’accès hybride aux fichiers
Les unités précédentes étaient principalement axées sur ce que fait votre solution de stockage. Cette unité est axée sur l’emplacement de vos données. Plus spécifiquement, nous présentons des considérations relatives à l’accès hybride aux fichiers et comment les aborder.
Vue d’ensemble de l’accès hybride aux fichiers
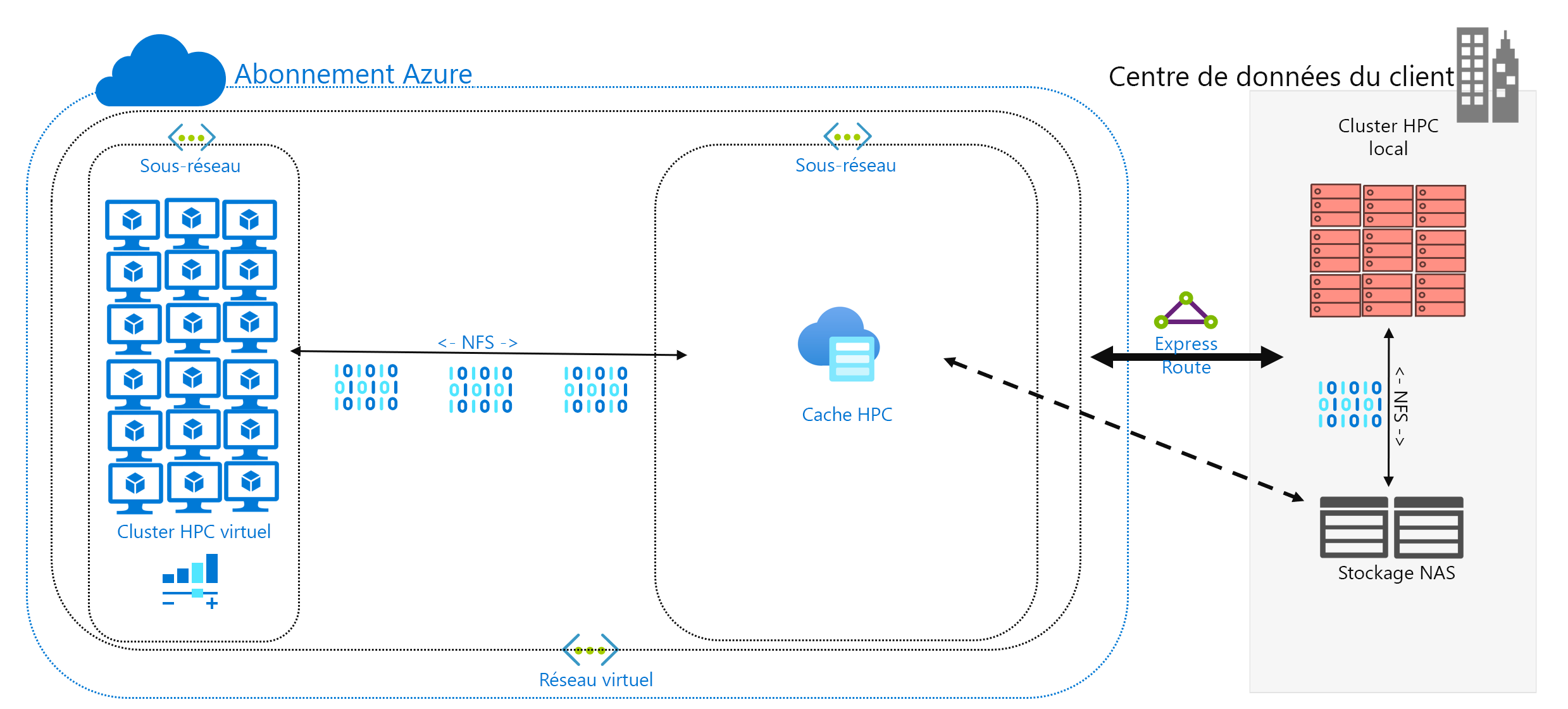
Vous avez décidé d’exécuter une charge de travail HPC dans Azure, qui est actuellement exécutée dans votre centre de données. Votre environnement de calcul accède aux données sur votre NAS, qui sert les opérations NFSv3 à votre charge de travail. Elle s’y exécute depuis des années, mais peut-être que votre environnement NAS atteint la fin de son cycle de vie. Au lieu de la remplacer, vous envisagez une migration à long terme vers le cloud.
Une fois que vous avez pris cette décision, mais avant le déploiement complet dans le cloud de votre charge de travail HPC, vous déterminez votre stratégie Azure et vous établissez votre configuration de compte de base/abonnement/sécurité. Passons maintenant à la partie difficile : déplacer vos charges de travail HPC.
La structure de votre cluster HPC et son plan de gestion n’entrent pas dans le cadre de ce module. Nous supposons que vous avez déterminé les types et les quantités de machines virtuelles que vous voulez exécuter dans votre cluster.
Pour le moment, nous supposons aussi que votre objectif est d’exécuter la charge de travail telle quelle. Autrement dit, vous ne voulez pas modifier la logique ou les méthodes d’accès actuellement déployées localement. Cela implique que votre code s’attend à ce que les données figurent dans les chemins de répertoires des systèmes de fichiers locaux des membres du cluster.
Le premier objectif est de comprendre quelles sont les données nécessaires et quelles en sont les sources. Vos données peuvent se trouver dans un répertoire unique dans un même environnement NAS, ou être réparties entre divers environnements.
L’objectif suivant est de déterminer la quantité de données nécessaires pour exécuter la charge de travail. Les données sources représentent-elles quelques gigaoctets ou des centaines de téraoctets ?
Enfin, vous devez déterminer comment les données sont présentées dans Azure Compute. Sont-elles délivrées localement à chaque machine du cluster HPC ou partagées par une solution NAS basée sur le cloud ?
Considérations sur l’accès aux données à distance
Vous avec une charge de travail génomique que vous voulez exécuter dans Azure. Vos données sont générées par des séquenceurs de gènes locaux et envoyées à un environnement NAS local. Les chercheurs locaux consomment les données pour diverses utilisations. Les chercheurs peuvent également utiliser les résultats de la charge de travail HPC que vous prévoyez d’exécuter dans Azure. Toutefois, certains d’entre eux utilisent des stations de travail locales pour le faire. Supposons également que de nouvelles données génomiques sont générées régulièrement. Vous disposez donc d’un délai limité pour exécuter la charge de travail actuelle avant que les données soient remplacées/actualisées.
Le défi consiste à présenter les données aux capacités de calcul Azure de manière opportune et économique, tout en préservant l’accès local à celles-ci.
Voici quelques-unes des questions principales à poser lorsque vous essayez d’exécuter des charges de travail HPC dans Azure :
- Pouvons-nous déplacer des données sources vers Azure sans en conserver une copie locale ?
- Pouvons-nous enregistrer des données de résultats dans le stockage Azure sans en conserver une copie locale ?
- Les utilisateurs locaux ont-ils besoin d’un accès concurrent aux données sources et aux données de résultats ?
- Si tel est le cas, sont-ils en mesure de travailler sur les données dans Azure ou ont-ils besoin d’un stockage local des données ?
Si les données doivent être conservées localement, quelle quantité de données doit être copiée dans Azure pour la charge de travail ? De combien de temps disposez-vous après le traitement des données, avant de devoir traiter un nouvel ensemble de données ? Votre charge de travail va-t-elle s’exécuter dans ce laps de temps ?
Vous devez également prendre en compte la connectivité réseau à Azure. Disposez-vous seulement d’un accès Internet à Azure ? Cette limitation peut convenir, selon la taille des données à copier/transférer et l’intervalle de temps entre les actualisations. Peut-être avez-vous une grande quantité de données à copier à chaque fois. Vous pouvez avoir besoin d’une connexion de réseau étendu WAN à Azure utilisant Azure ExpressRoute, qui offrirait davantage de bande passante pour copier/transférer les données.
Si vous disposez déjà d’une connexion ExpressRoute à Azure, réfléchissez au point suivant : quelle part de la connexion est-elle disponible pour votre opération de copie de données ? Si la liaison est fortement saturée, tenez compte de l’heure de la journée à laquelle vous transférez les données. Vous pouvez également configurer une connexion ExpressRoute plus large pour prendre en charge de grands transferts de données.
Si vous déplacez ces données vers Azure, vous pouvez réfléchir à la façon dont vous les sécurisez. Par exemple, vous pouvez avoir un environnement NFS local qui utilise un service d’annuaire favorisant l’extension des autorisations à vos utilisateurs. Si vous prévoyez de copier cette sécurité dans Azure, vous devez décider si vous avez besoin d’un service d’annuaire dans le cadre de la structure d’Azure. En revanche, si votre charge de travail est limitée au cluster HPC et que les résultats sont retransférés vers votre environnement local, vous pouvez ignorer ces exigences.
Ensuite, nous examinons les méthodes d’accès aux données : mise en cache, copie et synchronisation.
Mise en cache, copie et synchronisation
Voyons les approches générales que vous pouvez utiliser pour ajouter des données dans Azure. Cette discussion sur le transfert de données porte sur les données actives, et non pas sur l’archivage et la sauvegarde des données.
Supposons que les données transférées dont nous allons parler correspondent à la plage de travail d’une charge de travail HPC. Dans un environnement HPC des sciences de la vie, les données peuvent inclure des données sources comme des données génomiques brutes, des fichiers binaires utilisés pour traiter ces données ou des données supplémentaires comme des génomes de référence. Elle doivent être traitées immédiatement à leur arrivée, ou peu après. Les données doivent également être stockées sur un support ayant le profil de performances approprié en termes d’IOPS, de latence, de débit et de coût. En revanche, les données d’archivage/sauvegarde sont le plus souvent transférées vers la solution de stockage la plus économique, qui n’est pas conçue pour un accès à hautes performances.
Les principales méthodes de transfert de données actives sont la mise en cache, la copie et la synchronisation. Examinons les avantages et les inconvénients de chaque approche, en commençant par la copie.
La copie des données est l’approche la plus courante pour déplacer des données. Les données sont copiées de différentes façons, selon l’outil utilisé.
Tenez compte de ces facteurs :
- La taille des fichiers.
- Le nombre de fichiers.
- La quantité de débit disponible pour le transfert des données.
- Le temps dont vous disposez pour effectuer le transfert.
Un outil de copie élémentaire tel que cp est tout ce dont vous avez besoin si vous transférez quelques fichiers d’une taille raisonnable vers une destination distante. Vous souhaiterez probablement utiliser scp à la place de cp si vous transférez des données via des réseaux qui ne sont pas sécurisés : scp fournit le chiffrement via une connexion Secure Shell (SSH).
Il existe de nombreuses approches pour optimiser les opérations de copie, selon l’endroit où vous avez l’intention de copier les données. Si vous copiez des fichiers directement sur chaque machine HPC, vous pouvez par exemple planifier des opérations de copie individuelles sur chaque nœud.
L’un des points à prendre en compte lorsque vous copiez des données via des liaisons WAN est la quantité de fichiers et de dossiers à copier. Si vous copiez un grand nombre de petits fichiers, vous voulez combiner l’utilisation de la copie avec un outil d’archivage comme tar afin de supprimer de la liaison WAN la surcharge liée aux métadonnées. Copiez le fichier .tar sur Azure, puis copiez les données sur les machines.
Un autre problème avec la copie concerne le risque d’interruption. Par exemple, si vous essayez de copier un grand fichier et que des erreurs de transmission se produisent, l’outil cp ne fonctionne pas, car il ne peut pas reprendre la copie là où elle s’est arrêtée.
Un dernier problème avec la copie de données est que votre copie peut devenir obsolète. Par exemple, vous pouvez copier un jeu de données dans Azure. Dans le même temps, un utilisateur local peut avoir mis à jour un ou plusieurs des fichiers sources. Vous devez déterminer un processus garantissant que vous utilisez les données correctes.
La synchronisation des données est une forme de copie, mais elle est plus sophistiquée. Des outils tels que rsync ajoutent la possibilité de synchroniser les données entre la source et la destination en plus de les copier à partir de la source. rsync garantit la mise à jour des fichiers en fonction de la taille des fichiers et des dates de modification. La synchronisation vous permet de réduire les risques d’utilisation de fichiers obsolètes.
rsync offre des fonctionnalités de récupération. Par exemple, si vous copiez un fichier volumineux et que vous rencontrez des problèmes de transmission, rsync peut reprendre là où il s’est arrêté.
rsync est gratuit et facile à implémenter. Ses fonctionnalités vont au-delà de celles que nous décrivons ici. Il vous permet d’établir dans Azure un système de fichiers synchronisé qui s’appuie sur vos données locales.
rsync présente également des limitations que nous devons mentionner. Tout d’abord, l’outil est monothread. Il ne peut exécuter qu’une seule opération à la fois et ne peut pas paralléliser l’accès aux données. L’utilitaire de copie cp est également monothread. Par conséquent, ces outils ne sont pas optimisés pour les opérations de copie/synchronisation à grande échelle impliquant de grandes quantités de données et une courte plage de temps. En outre, vous devez exécuter l’outil pour synchroniser les données. L’exécution de l’outil accroît la complexité de votre environnement, car vous devez vous assurer qu’il s’exécute conformément à vos exigences en termes de délai. Vous souhaiterez peut-être planifier un script comprenant rsync, par exemple. Cette approche exige que vous ajoutiez une journalisation de votre script, dans l’éventualité d’un problème. Cela signifie également que vous devez surveiller l’apparition de problèmes. Le niveau de complexité peut croître rapidement.
Si vous exécutez une solution NAS du commerce, vous pouvez acheter des outils de synchronisation au niveau du serveur qui sont plus sophistiqués et offrent des performances multithread. Une fois activés et configurés, ces outils fonctionnent en permanence et synchronisent les données entre une ou plusieurs sources et destinations.
La copie et la synchronisation transmettent des copies complètes des données sources. La transmission complète des fichiers peut convenir pour des jeux de données réduits ou de petites tailles de fichiers. Elle peut entraîner des délais importants si les données sources sont constituées de nombreux fichiers volumineux. Plus vous transférez de données, plus le transfert prend du temps. La synchronisation garantit que vous ajoutez seulement de nouveaux fichiers dans le cloud. Toutefois, ces fichiers doivent toujours être transmis dans leur intégralité. Dans certains cas, votre charge de travail HPC peut ne pas nécessiter la totalité d’un ensemble de fichiers donné. Elle peut nécessiter l’accès à des zones spécifiques de fichiers uniquement.
La mise en cache des données est une troisième approche de l’ajout de données dans Azure. La mise en cache fait référence à la récupération et à la présentation des données des fichiers via un cache. Le cache peut se trouver sur des clients locaux individuels ou être un cache distribué au service de toutes les machines HPC. Les caches sont normalement utilisés pour réduire au maximum la latence. Ainsi, le placement d’un cache à une limite de latence est une approche optimale pour délivrer les données. Par exemple, vous pouvez mettre en cache les demandes de données via une connexion WAN en plaçant un cache distribué dans les capacités de calcul Azure et en le connectant au stockage local via la liaison WAN.
Dans ce module, nous faisons spécifiquement référence à la mise en cache de fichiers, où le cache lui-même renseigne les demandes des machines. Il récupère les données à partir d’un environnement de stockage back-end (tel qu’un environnement NAS NFS) et présente ces données aux clients.
La puissance de la mise en cache est double. Tout d’abord, les caches ne récupèrent pas les fichiers entiers. Un cache récupère un sous-ensemble demandé, ou une plage d’octets, de fichiers, plutôt que des fichiers entiers. La récupération est basée sur les demandes des clients pour ces plages d’octets. Cette approche de la récupération réduit au maximum les baisses de performances liées à la récupération de l’intégralité d’un fichier volumineux quand seule une petite section du fichier est requise.
En outre, les caches optimisent les accès répétés aux données demandées fréquemment. Quand une plage d’octets est en cache, les demandes suivantes portant sur ces données sont rapides. La seule récupération lente est la récupération initiale. Vous pouvez bénéficier d’avantages significatifs quand vous exécutez un grand nombre de clients/threads HPC qui accèdent à un ensemble commun de fichiers.
La mise en cache offre un autre avantage pour les scénarios hybrides. Les données sont stockées dans Azure (dans le cache) uniquement de façon transitoire. Et elles sont stockées uniquement pendant le fonctionnement de la charge de travail HPC. Ainsi, vous pouvez réduire la surcharge logistique impliquée dans un déplacement de données plus concret vers Azure. Vous pouvez isoler les problèmes liés à la confidentialité et à la sécurité des données dans le cache et les machines HPC elles-mêmes.
Enfin, certaines solutions de mise en cache offrent ce qui s’appelle une vérification des attributs. De façon similaire à la synchronisation, le cache vérifie périodiquement les attributs du fichier à la source et récupère les plages d’octets quand la modification du fichier est plus importante à la source. Cette architecture garantit que votre environnement HPC fonctionne toujours avec les données les plus récentes.