Systèmes de fichiers parallèles
NFS est né du monde de l’entreprise. Il a été conçu pour gérer les accès concurrents aux fichiers à une échelle croissante. Cependant, les solutions NFS sont soumises à une limite maximale en termes de performances et d’échelle. Il existe également des classes de charges de travail qui nécessitent des accès parallèles beaucoup plus importants aux fichiers, avec la possibilité d’avoir plusieurs processus concurrents qui écrivent dans une certaine section d’un fichier.
La nécessité de lire et d’écrire à grande échelle a considérablement augmenté au cours des deux dernières décennies. Les solutions avec systèmes de fichiers parallèles constituent le choix principal pour accélérer les charges de travail hautes performances les plus importantes. Les systèmes de fichiers parallèles sont nés dans des centres exploitant des supercalculateurs. Ils sont maintenant largement déployés pour différents scénarios. Par exemple, des solutions de traitement et d’interprétation des données sismiques utilisées par les grandes compagnies pétrolières et gazières, et l’analyse secondaire/tertiaire des données génomiques.
Cette unité présente seulement des généralités sur les systèmes de fichiers parallèles. Si vous exécutez de telles charges de travail, vous connaissez probablement bien les pilotes, les besoins et l’architecture de ces solutions. Il existe une zone grise entre les solutions NAS distribuées au service des systèmes de fichiers NFS et parallèles. L’utilisation de systèmes de fichiers parallèles peut mieux répondre à vos besoins.
Une fois cette unité terminée, vous comprendrez mieux les principales fonctionnalités des systèmes de fichiers parallèles.
Les systèmes de fichiers parallèles étaient historiquement une classe complète de fonctionnalités nécessitant une connaissance approfondie des E/S des applications. Ces informations sont là pour vous aider à comprendre, et non pas à acquérir une expertise.
Système de fichiers NAS distribué (NFS) et système de fichiers parallèle
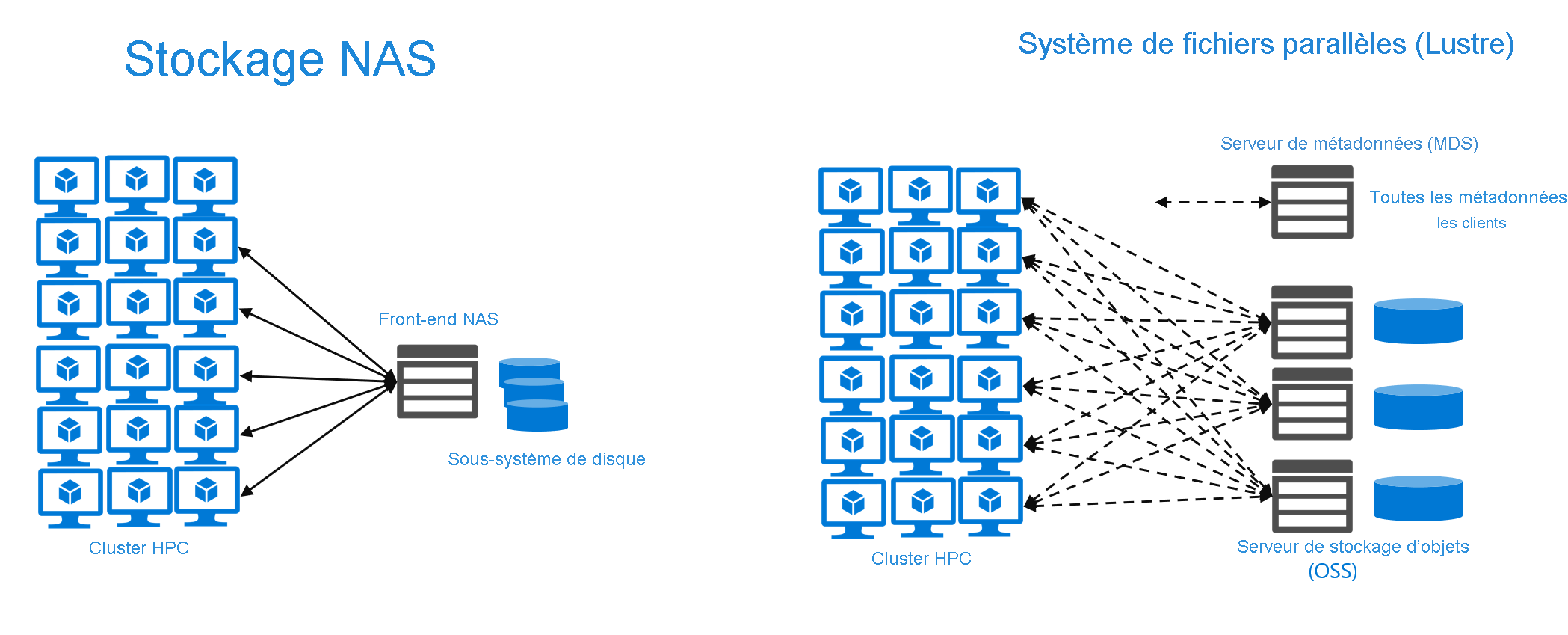
Le système de fichiers NAS distribué et le système de fichiers parallèle sont des systèmes de fichiers partagés. Plusieurs clients lisent des fichiers simultanément, les fichiers font l’objet d’écritures et verrouillés, les métadonnées peuvent être modifiées, etc.
Vous pouvez mettre à l’échelle ces deux systèmes en ajoutant ou en mettant à niveau les technologies matérielles de stockage, en ajoutant des serveurs front-end pour mettre à l’échelle l’accès des clients ou en améliorant la connectivité réseau.
E/S parallèles
Les systèmes de fichiers parallèles décomposent les fichiers en blocs ou bandes discrets, et distribuent ces fichiers entre plusieurs serveurs de stockage. Il existe des systèmes de fichiers distribués qui agrègent les données par bandes. La différence est que les systèmes de fichiers parallèles exposent les bandes directement aux clients, via une communication avec les serveurs de stockage d’hébergement eux-mêmes. L’agrégation par bandes permet d’obtenir des E/S parallèles importantes sur un système NAS distribué standard. Les clients NFS qui fonctionnent avec les environnements NAS en scale-out les plus courants doivent accéder à un fichier via un seul serveur. Quand les clients accèdent à un seul serveur, cela provoque des problèmes quand le nombre de demandes simultanées dépasse ce que le serveur peut gérer. De plus, l’approche des systèmes de fichiers parallèles en matière d’accès parallèle et d’agrégation par bandes fait d’eux une solution idéale pour les charges de travail qui doivent accéder à des fichiers volumineux avec un grand nombre de clients concurrents.
Voici trois principaux systèmes de fichiers parallèles :
- GPFS d’IBM, appelé Spectrum Scale
- Lustre, qui est proposé en open source mais aussi dans certaines implémentations commerciales
- BeeGFS
Ces systèmes réalisent des E/S parallèles de différentes façons. GPFS utilise des serveurs appelés périphériques de stockage réseau ou périphériques NSD (Network Storage Device), qui se connectent à un réseau SAN hautes performances. Ainsi, les serveurs GPFS ont des E/S de disque brutes comme stockage de sauvegarde. BeeGFS a un grand nombre de composants d’architecture identiques à ceux de Lustre, mais il a également une architecture robuste de métadonnées distribuées. BeeOND, qui est l’abréviation de BeeGFS On Demand, favorise des environnements BeeGFS à la demande qui utilisent du stockage sur chaque client. Ces environnements de système de fichiers temporaires peuvent être utilisés pour la mise en mémoire tampon en rafale.
Dans les deux cas cependant, les systèmes de fichiers parallèles peuvent être mis à l’échelle via l’ajout de serveurs de stockage, qui offrent à leur tour plus d’E/S parallèles aux clients. Le nombre total de clients peut être important, de l’ordre de plusieurs dizaines de milliers.
Métadonnées
Les clients NFS interagissent directement avec un serveur NFS, qui fournit des informations de métadonnées et récupère les données pour les clients. Vous devez dimensionner le composant serveur en fonction de la quantité de clients et du taux de trafic attendu. Ce composant peut devenir un goulot d’étranglement. Les fournisseurs de solutions NAS peuvent implémenter certaines optimisations des métadonnées, mais la plupart des implémentations de NFS ne reconnaissent pas un service de métadonnées distinct.
En comparaison, les systèmes de fichiers parallèles implémentent généralement des stratégies permettant une meilleure mise à l’échelle de l’accès aux données des clients. Par exemple, Lustre implémente un serveur de métadonnées distinct (MDS). Les clients récupèrent toutes les métadonnées de ce système. De plus, les clients Lustre peuvent accéder directement au serveur de stockage où se trouve un fichier donné et peuvent lire/écrire plusieurs threads parallèles. Cette approche permet à l’architecture de mettre à l’échelle la bande passante en fonction du nombre de serveurs de stockage déployés.
Taille de bloc
Nous avons présenté la taille de bloc précédemment dans le contexte de NFS. Les tailles de bloc des systèmes de fichiers parallèles peuvent être plus grandes que celles de NFS. La valeur par défaut de rsize/wsize pour les clients NFS est généralement de 64 000. Par exemple, Lustre a des tailles de bloc de plusieurs Mo. Cette taille plus grande a deux effets. D’abord, la lecture et l’écriture de grands fichiers sont plus rapides dans un système de fichiers parallèle. Les systèmes de fichiers parallèles offrent cependant peu d’avantages quand les tailles de fichiers sont petites et qu’il y a un grand nombre de fichiers.
Complexité
Les solutions avec des systèmes de fichiers distribués exécutant NFS sont faciles à configurer et à exécuter pour les cas d’utilisation courants. Comme n’importe quel système, ils peuvent être optimisés pour les performances, y compris la manipulation des tailles de bloc client-serveur (rsize/wsize) en fonction des charges de travail.
Les systèmes de fichiers parallèles fonctionnent généralement sur des charges de travail complexes dans des environnements avec mise à l’échelle. Ils sont plus susceptibles de nécessiter une configuration et un réglage pour garantir des performances et une évolutivité suffisantes.
Points à prendre en considération pour le déploiement
Azure propose plusieurs offres de système de fichiers parallèle au choix de l’utilisateur. Vous pouvez accéder à la Place de marché Azure pour voir les options, qui incluent BeeGFS et Lustre. (Recherchez Whamcloud.) Vous pouvez également installer Lustre sur des machines virtuelles Linux standard ou vous pouvez utiliser les modèles Azure Resource Manager (ARM) disponibles sur le site de modèles de démarrage rapide Azure.