Authentification et autorisation des systèmes de fichiers
Une fois que vous avez compris les caractéristiques générales des performances et du trafic de votre charge de travail, vous devez prendre en compte les aspects de la sécurité. Vos données peuvent être sensibles, comme des images radiologiques de patients. Vous souhaiterez peut-être restreindre l’accès aux données pour diverses raisons. Vous souhaiterez peut-être offrir à chacun de vos chercheurs un « répertoire de base » à partir duquel il pourra charger des données, et effectuer des analyses et des simulations HPC.
Quand vous sélectionnez votre stockage HPC cloud, vous devez savoir comment il s’intègre à votre posture de sécurité actuelle. Comprenez bien les méthodes par lesquelles votre système de fichiers authentifie et autorise l’accès aux fichiers. Déterminez si l’application de ces règles est locale ou distante (ou les deux), et d’où proviennent l’authentification et l’autorisation. Si vous utilisez un système de fichiers partagé distant, vous devez comprendre comment contrôler l’accès en utilisant des pratiques NAS standard. Enfin, si vous proposez des espaces de travail uniques pour les utilisateurs (répertoires de base), comprenez comment allouer ces espaces.
Dans cette unité, nous examinons les considérations sur la sécurité et la façon dont elles affectent votre architecture de stockage.
Vue d’ensemble de l’authentification et de l’autorisation
Authentification : lorsque vous fournissez un accès aux systèmes de fichiers, vous devez authentifier le demandeur en utilisant des informations d’identification approuvées. De nombreuses architectures client/serveur demandent ces informations d’identification, comme des comptes d’utilisateur ou d’ordinateur. Ces informations d’identification sont ensuite vérifiées pour garantir qu’elles sont valides pour l’environnement. Après authentification, le demandeur (l’utilisateur ou l’ordinateur/processus) est autorisé. Les protocoles d’accès nécessaires pour votre environnement peuvent limiter l’authentification pour votre solution. Par exemple, si vous avez un environnement Windows, vous utilisez probablement le protocole SMB (Server Message Block) comme protocole d’accès aux fichiers du réseau. Les exigences de l’authentification SMB ne sont pas les mêmes que celles de NFS.
Autorisation : permettre à un utilisateur ou à un ordinateur d’accéder à un environnement est une chose, mais avec quel niveau d’accès ? Par exemple, l’utilisateur A peut lire des fichiers sur un système de fichiers, alors que l’utilisateur B peut lire et écrire des fichiers. L’autorisation peut aller plus loin que la lecture et l’écriture. Par exemple, l’utilisateur C peut être autorisé à modifier des fichiers, mais pas à en créer de nouveaux dans un répertoire donné.
Le niveau d’autorisation est souvent exprimé sous la forme de permissions pour un fichier donné. Elles portent notamment sur la lecture, l’écriture et l’exécution.
Utilisateurs et groupes : accorder l’accès à un ensemble de ressources peut devenir fastidieux quand vous avez un grand nombre d’utilisateurs. Cela devient également compliqué si vous prévoyez d’accorder des niveaux d’accès différents à plusieurs ensembles d’utilisateurs. L’utilisation de groupes devient alors nécessaire. Vous pouvez affecter un utilisateur à un groupe ou à un ensemble de groupes spécifique. Vous pouvez ensuite autoriser l’accès à des ressources en fonction de cette identification de groupe.
Ensemble, l’authentification et l’autorisation représentent l’accès de niveau utilisateur, de niveau groupe et de niveau ordinateur que vous voulez accorder aux ressources, dans notre cas aux fichiers.
Le système d’exploitation Linux affecte un identificateur d’utilisateur (UID) aux comptes d’utilisateur individuels. L’UID est un entier. Le système l’utilise pour déterminer à quelles ressources du système, y compris à quels fichiers et dossiers, un utilisateur spécifique peut accéder.
Le système d’exploitation Linux utilise des identificateurs de groupe (GID) pour les affectations de groupe. Un utilisateur est associé à un seul groupe principal. Les utilisateurs peuvent être associés à quasiment n’importe quel nombre d’affectations de groupes supplémentaires, jusqu’à 65 536 sur les systèmes Linux les plus modernes.
Authentification et autorisation locales et distantes
L’authentification et l’autorisation locales font référence à l’accès à un système de fichiers local par un compte d’utilisateur/d’ordinateur qui est également local pour l’ordinateur. Par exemple, je peux créer un compte d’utilisateur, puis lui accorder l’accès au répertoire /data situé sur mon système de fichiers local. Ce compte d’utilisateur est local, tout comme l’octroi de l’accès au répertoire. Je peux aussi utiliser l’affectation de groupe pour contrôler l’accès. La combinaison de l’autorisation de l’utilisateur et du groupe donne à un utilisateur des autorisations effectives sur un fichier ou un dossier.
Si vous examinez une sortie standard de la commande de répertoire ls -al, vous voyez un résultat similaire à ceci :
drwxr-xr-x 4 root root 4096 Dec 31 19:43.
drwxr-xr-x 13 root root 4096 Dec 11 05:53 ..
drwxr-xr-x 6 root root 4096 Dec 31 19:43 microsoft
drwxr-xr-x 8 root root 4096 Dec 31 19:43 omi
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
Les caractères drwxr-xr-x représentent le niveau d’accès autorisé des utilisateurs et groupes au fichier ou au répertoire. Le caractère d indique que l’entrée est un répertoire. (Si la première valeur est -, il s’agit d’une entrée de fichier.) Les caractères restants représentent l’autorisation du groupe d’autorisations de lecture (r), d’écriture (w) et d’exécution (x). Les trois premières valeurs indiquent le « propriétaire » du fichier ou du répertoire. Les trois valeurs suivantes représentent les autorisations de groupe affectées au fichier ou au répertoire. Les trois dernières valeurs indiquent les autorisations accordées à tous les autres utilisateurs sur le système.
Voici un exemple :
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
-indique que cette ressource est un fichier.rw-indique que le propriétaire dispose des autorisations de lecture et d’écriture.r--indique que le groupe affecté a uniquement des autorisations de lecture.r--indique que les utilisateurs restants ont uniquement des autorisations de lecture.- Notez également que l’utilisateur propriétaire et le groupe affecté sont représentés par les deux colonnes
root.
Un UID et des GID principaux et complémentaires représentent un utilisateur authentifié sur un ordinateur local. Ces valeurs sont locales pour cet ordinateur. Que se passe-t-il si vous avez 5 ou même 50 ordinateurs ? Vous devriez répliquer les affectations d’UID et de GID sur chacun de ces ordinateurs. Le niveau de complexité lié à la gestion des utilisateurs augmente, tout comme la possibilité d’accorder par erreur l’accès à des fichiers ou dossiers au mauvais utilisateur.
Accès aux fichiers à distance via NFS
L’affectation d’UID et de GID locaux fonctionne correctement si vous gérez tout sous la forme d’une seule affectation d’utilisateur/groupe. Que se passe-t-il si plusieurs parties prenantes consomment le cluster HPC que vous exécutez, et que chaque partie prenante a des données sensibles et plusieurs consommateurs des données ?
Le fait de placer les données sur un serveur de fichiers ou dans un environnement NAS permet l’accès à distance de ces données. Cette approche permet de réduire le coût des disques locaux, de garantir que les données sont à jour pour tous les utilisateurs et de réduire la gestion globale des utilisateurs et des groupes.
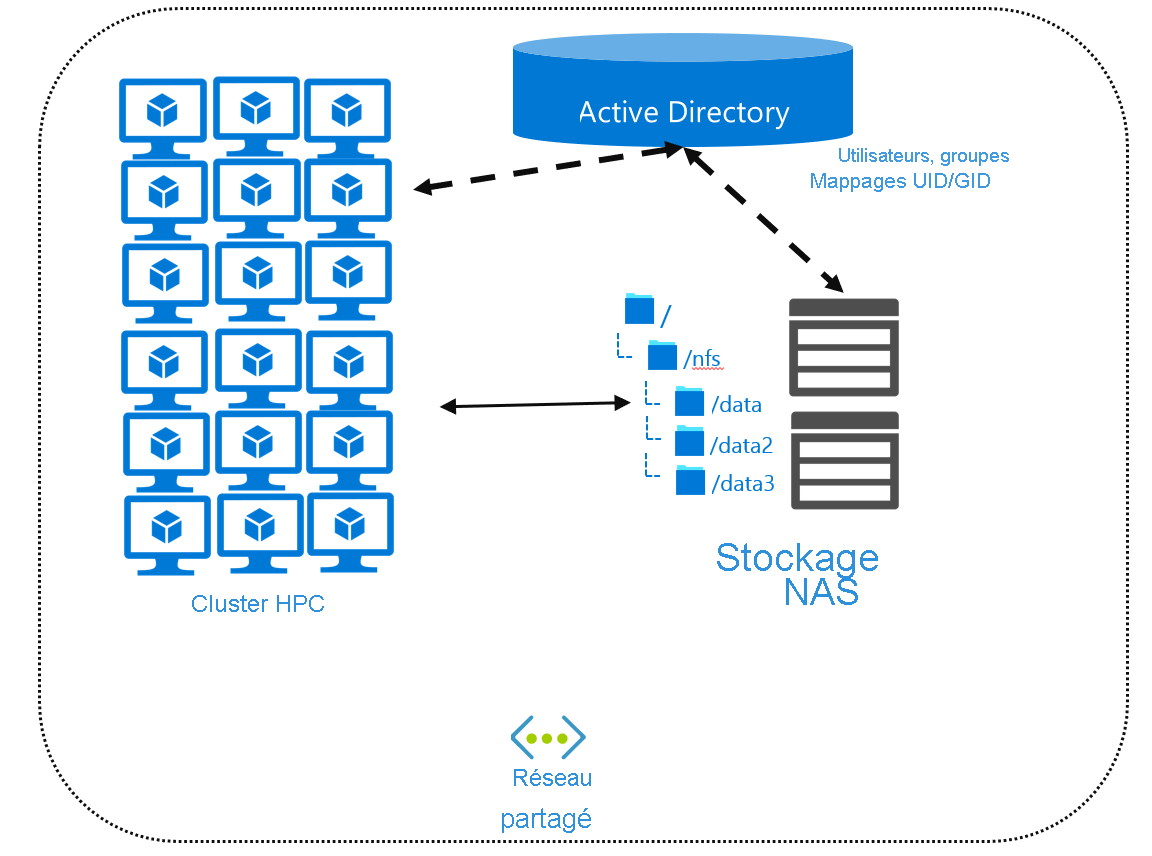
Si vous recherchez des fichiers de manière centralisée, vous pouvez avoir besoin d’un service d’annuaire contenant la configuration des utilisateurs et des groupes. Les services d’annuaire, comme Active Directory ou Lightweight Directory Access Protocol (LDAP), vous permettent de créer un mappage des utilisateurs/groupes utilisable par tous les systèmes distants. Vous configurez vos ordinateurs distants et votre environnement NAS en tant que clients de ce service d’annuaire. Vous pouvez également utiliser des mappages Active Directory entre vos comptes d’utilisateur Windows et une combinaison spécifique d’UID et de GID.
La méthode standard permettant d’accéder à des fichiers à distance consiste à utiliser un système de fichiers réseau comme NFS ou SMB, ou un système de fichiers parallèle comme Lustre. Ces protocoles définissent l’API client-serveur pour l’accès aux données. Nous avons présenté les opérations NFS dans l’unité « Considérations sur les performances des systèmes de fichiers ». Nous présenterons en détail l’utilisation de NFS dans l’unité suivante.
Notes
Un service d’annuaire n’est pas requis lorsque vous utilisez NFS. Toutefois, si vous n’en utilisez pas, la gestion des UID et GID s’avérera difficile si vous avez un grand nombre d’utilisateurs et de systèmes.
Répertoires de base
Imaginons que vous avez un environnement HPC utilisé par plusieurs chercheurs, mais que leurs données propres doivent être gardées séparées. Imaginons que ces chercheurs modifient continuellement leurs propres données et ajoutent de nouvelles données. Fournir aux chercheurs leurs propres répertoires de base est un moyen efficace d’isoler leurs propres données.
Chaque utilisateur effectuant des recherches va gérer des autorisations au sein du répertoire personnel, ce qui va lui permettre de collaborer s’il le souhaite.
Une des principales problématiques de cet environnement est l’espace de stockage. Imaginons que vous avez un environnement NAS de 500 To. Qu’est-ce qui empêche un chercheur de l’utiliser entièrement ?
Vous pouvez affecter un quota à un répertoire individuel. Le quota reflète la quantité maximale de données autorisée. Une fois le quota atteint, il peut rejeter les données supplémentaires ou avertir les administrateurs que le chercheur a dépassé la limite. Par exemple, si vous avez un système NAS, vous pouvez affecter un quota à chaque chercheur. Si vous isolez l’accès des chercheurs au répertoire de base, il est aisé de configurer et de surveiller leur utilisation.