Accès aux fichiers pour les travaux HPC
L’accès au stockage est une partie importante de la planification des performances des charges de travail HPC. Vous devez garantir que les données nécessaires sont disponibles pour les machines du cluster HPC au bon moment. Vous devez également garantir que les résultats provenant de ces machines individuelles sont enregistrés rapidement et sont disponibles pour une analyse plus approfondie.
Les fichiers peuvent inclure différents types de données, notamment :
- Des données non structurées, comme des images, des documents ou des fichiers multimédias.
- Des données de séries chronologiques provenant de différentes sources.
- Des données de tarification (comme l’historique des cours boursiers).
- Des ressources utilisées pour une analyse basée sur le calcul, comme des données génomiques, de l’imagerie radiologique ou une simulation météorologique.
Les données sont supposées se trouver dans une ou plusieurs solutions de stockage dans votre environnement local. Dans ce contexte, les architectures de stockage incluent :
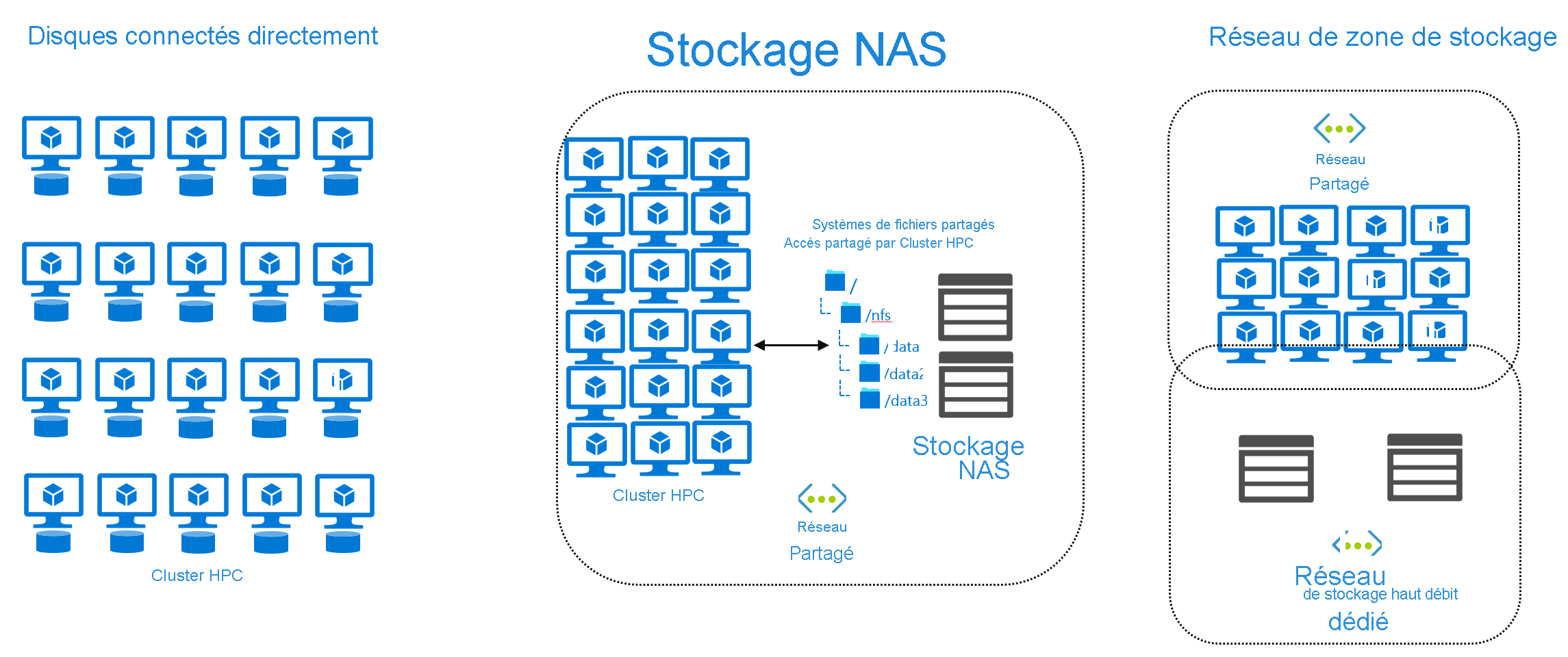
- Des disques directement attachés. Chaque machine du cluster HPC a ses propres disques de stockage locaux.
- Des solutions NAS (Network-Attached Storage)
- Des solutions SAN (Storage Area Network).
Les analystes, les artistes, les chercheurs ou les scientifiques peuvent créer les données localement. Les données peuvent aussi être acquises périodiquement auprès de tiers et déposées dans votre solution de stockage local.
Types d’accès aux fichiers
Les cas d’usage généraux d’accès aux fichiers que nous allons présenter dans ce module sont limités aux activités suivantes :
- Chargement et exécution du code des travaux, de bibliothèques et/ou de chaînes d’outils sur les machines du cluster HPC.
- Lecture de données sources pour une tâche. Par exemple, des données tarifaires quotidiennes, des données génomiques ou des données satellites.
- Des écritures intermédiaires ou de brouillon. Certaines tâches nécessitent le traitement des données initiales et que la sortie de ce traitement devienne une nouvelle entrée pour l’activité en aval.
- Écriture des résultats d’une tâche. Ce cas d’usage implique le placement des données à un emplacement choisi pour les consommer ultérieurement. Par exemple, le rendu d’une vidéo et le placement des résultats rendus dans un volume partagé à utiliser.
Comment les machines HPC obtiennent-elles des données de jeu de travail ?
Les machines du cluster HPC accèdent aux fichiers via un disque directement attaché, ou via une exportation ou un partage réseau. Dans les deux cas, les fichiers sont présentés dans un chemin local (par exemple, /mnt/data).
Le code et les scripts qui constituent la tâche HPC réelle supposent que les fichiers sont accessibles sur ce système de fichiers et utilisent les capacités d’accès aux fichiers de la machine pour obtenir les fichiers. Par exemple, une machine exécutant Linux qui doit accéder à un fichier situé sur un NAS utilise le protocole NFS (Network File System) et les packages clients NFS installés dans le cadre du système d’exploitation.
Comprendre les métadonnées de fichier
Un fichier stocke des données réelles (par exemple, une image ou des lignes de texte) et des informations supplémentaires connues sous le nom de métadonnées. Ces métadonnées existent dans les données du fichier ou dans un répertoire. Il est important de comprendre ces métadonnées dans le contexte des performances du système de fichiers HPC.
Les métadonnées sont un ensemble de valeurs qui décrivent les attributs des données, mais qui n’en font pas partie. Par exemple, les métadonnées vous indiquent quand un fichier a été créé et modifié, qui a créé le fichier et qui est autorisé à y accéder.
Quand un fichier est créé, des opérations de métadonnées allouent les structures et mettent à jour les entrées d’annuaire pour ce fichier. Ces opérations se produisent avant que les données soient écrites dans le fichier.