Options de configuration HDInsight
HDInsight intègre un large éventail de technologies OSS, que vous pouvez utiliser pour gérer les scénarios de streaming et de données par lots (termes définis dans les architectures Lambda). Dans ce modèle d’architecture, il existe un chemin chaud de données et un chemin froid de données. Le chemin chaud des données est généré en temps réel par les appareils, les capteurs ou les applications, et l’analyse des données est effectuée quasiment en temps réel. On parle alors souvent de données de diffusion en continu. Un chemin de données froid correspond au déplacement de données par lots, généralement à partir d’autres magasins de données. On parle de données par lots.
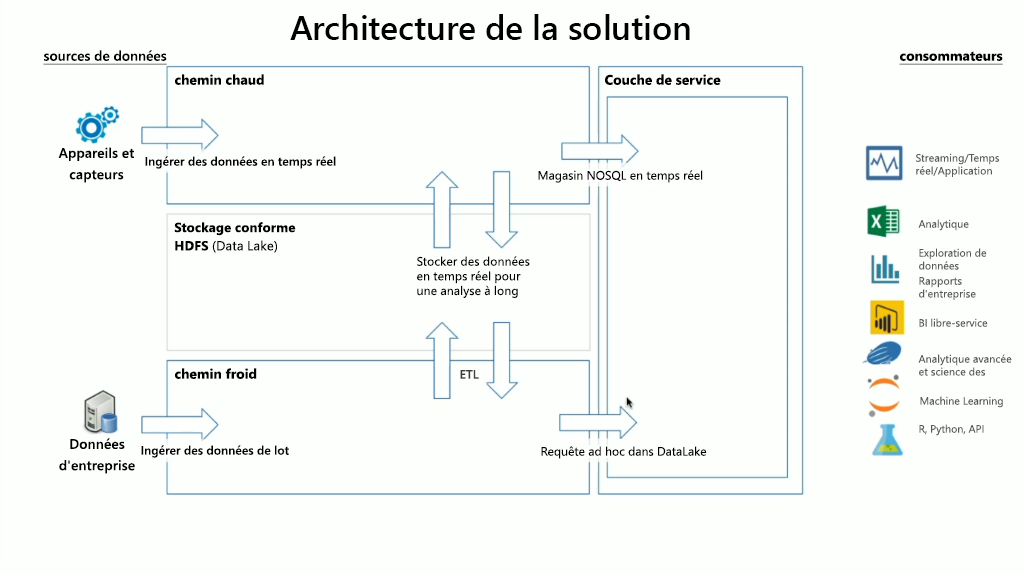
Lors de l’implémentation de HDInsight, le stockage des données est conservé dans un système de fichiers DFS Hadoop (HDFS) conforme. Dans Azure, Data Lake Gen2 est généralement utilisé en tant que magasin de données, car il est conforme à HDFS. Les données du chemin chaud et du chemin froid après traitement sont stockées dans un magasin de données centralisée appelée lac de données. Le lac de données peut être lui-même compartimenté pour contenir des données dans différents compartiments, lesquels peuvent être définis par l’état des données (zone d’atterrissage, zone de transformation, etc.), par les impératifs d’accès (chaud, modéré et froid) et par les groupes métier. La couche Service représente le dernier compartiment du lac de données. Elle contient les données dans un format prêt à être utilisé par différents types de consommateur.
Plus important encore, l’aspect calcul de HDInsight concerne le traitement des données en streaming ou par lots, et peut varier en fonction du type de cluster que vous sélectionnez quand vous provisionnez un cluster HDInsight. HDInsight offre des services dans des options de cluster individuelles, comme indiqué dans le tableau suivant.
| Type de cluster | Description |
|---|---|
| Apache Hadoop | Framework qui utilise HDFS et un simple modèle de programmation MapReduce pour traiter et analyser les données par lots. |
| Apache Spark | infrastructure de traitement parallèle open source qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analyse du Big Data. |
| hbase | base de données NoSQL basée sur Hadoop qui fournit un accès aléatoire et une forte cohérence pour de vastes quantités de données non structurées et semi-structurées (potentiellement, des milliards de lignes multipliées par des millions de colonnes). |
| Requête interactive Apache | mise en cache pour des requêtes Hive interactives et plus rapides. |
| Apache Kafka | plateforme open source utilisée pour créer des applications et des pipelines de données de diffusion en continu. Kafka fournit également une fonctionnalité de file d’attente de messages qui vous permet de publier des flux de données et de vous abonner à ces derniers. |
Il est donc important de sélectionner le type de cluster approprié pour respecter le cas que vous essayez de résoudre. Quel que soit le type de cluster sélectionné, des composants open source supplémentaires sont également ajoutés à l’intérieur du cluster pour offrir des fonctionnalités supplémentaires, notamment :
Gestion de Hadoop
HCatalog - Couche de gestion des tables et du stockage pour Hadoop
Apache Ambari - Facilite la gestion et le monitoring d’un cluster Apache Hadoop
Apache Oozie - Système de planification de workflow qui permet de gérer les travaux Apache Hadoop
Apache Hadoop YARN - Gère les ressources ainsi que la planification et le monitoring des travaux
Apache ZooKeeper - Service centralisé pour la gestion des informations de configuration, le nommage, la synchronisation distribuée et la fourniture de services de groupe.
Traitement des données
Apache Hadoop MapReduce - Framework qui permet d’écrire facilement des applications traitant de grandes quantités de données
Apache Tez - Framework d’application pour le traitement de données
Apache Hive - Facilite la gestion de jeux de données volumineux situés dans un stockage distribué à l’aide du langage SQL
Analyse des données
Apache Pig - Fournit une couche d’abstraction sur MapReduce pour analyser de grands jeux de données
Apache Phoenix - Active OLTP et l’analytique opérationnelle dans Hadoop
Apache Mahout - Framework d’algèbre pour créer vos propres algorithmes
Remarque
Au moment de la rédaction du présent contenu, Azure Data Lake Gen1 et le Stockage Blob Azure sont des couches de stockage de données prises en charge par HDInsight. Vous devez chercher à migrer ces données vers Azure Data Lake Gen2, car il s’agit de la plateforme de stockage recommandée pour Spark et Hadoop ainsi que du choix par défaut pour HBase.