Travailler avec des lacs de données Microsoft Fabric
Maintenant que vous comprenez les principales fonctionnalités des lakehouses Microsoft Fabric, nous allons apprendre à les utiliser.
Créer et explorer un lakehouse
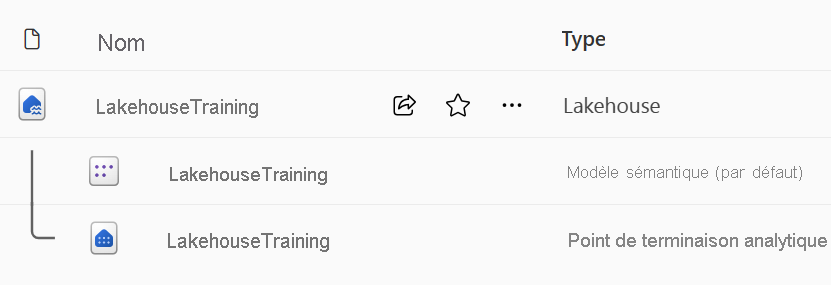
Lorsque vous créez un lakehouse, vous avez trois éléments de données différents créés automatiquement dans votre espace de travail.
- Le lakehouse contient des raccourcis, des dossiers, des fichiers et des tables.
- Le modèle sémantique (par défaut) fournit une source de données simple pour les développeurs de rapports Power BI.
- Le point de terminaison d’analytique SQL autorise l’accès en lecture seule aux données d’interrogation avec SQL.
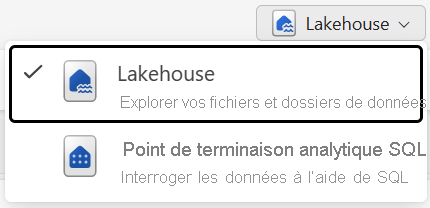
Vous pouvez utiliser les données du lakehouse dans deux modes :
- Le lakehouse vous permet d’ajouter et d’interagir avec des tables, des fichiers et des dossiers dans le lakehouse.
- Point de terminaison analytique SQL permet d’utiliser SQL pour interroger les tables du lakehouse et gérer son modèle de données relationnelles.
Ingérer des données dans un lakehouse
L’ingestion de données dans votre lakehouse est la première étape de votre processus ETL. Utilisez l’une des méthodes suivantes pour importer des données dans votre lakehouse.
- Charger : chargez des fichiers locaux.
- Flux de données (Gen2) : importez et transformez des données à l’aide de Power Query.
- Notebooks : utilisez Apache Spark pour ingérer, transformer et charger des données.
- Pipelines Data Factory : utilisez l’activité Copier les données.
Ces données peuvent ensuite être chargées directement dans des fichiers ou des tables. Prenez en compte votre modèle de chargement des données lors de l’ingestion de données pour déterminer si vous devez charger toutes les données brutes sous forme de fichiers avant de traiter ou d’utiliser des tables intermédiaires.
Les définitions de tâches Spark peuvent également être utilisées pour envoyer des tâches de traitement par lots/streaming à des clusters Spark. En téléchargeant les fichiers binaires à partir de la sortie de compilation de différents langages (par exemple, .jar de Java), vous pouvez appliquer différentes logiques de transformation aux données hébergées sur un Lakehouse. Outre le fichier binaire, vous pouvez personnaliser davantage le comportement du travail en téléchargeant davantage de bibliothèques et d'arguments de ligne de commande.
Remarque
Pour plus d’informations, consultez la documentation Créer une définition de tâche Apache Spark.
Accéder aux données à l’aide de raccourcis
Une autre façon d’accéder et d’utiliser des données dans Fabric consiste à utiliser des raccourcis. Les raccourcis vous permettent d’intégrer des données dans votre lakehouse tout en les conservant dans un stockage externe.
Les raccourcis sont utiles lorsque vous devez sourcer des données qui sont dans un autre compte de stockage ou même dans un autre fournisseur de cloud. Dans votre lakehouse, vous pouvez créer des raccourcis qui pointent vers différents comptes de stockage et d’autres éléments Fabric tels que des entrepôts de données, des bases de données KQL et autres lakehouses.
Les autorisations et les informations d’identification des données sources sont toutes gérées par OneLake. Lors de l’accès aux données via un raccourci vers un autre emplacement OneLake, l’identité de l’utilisateur appelant est utilisée pour autoriser l’accès aux données dans le chemin cible du raccourci. L’utilisateur doit disposer d’autorisations à l’emplacement cible pour lire les données.
Des raccourcis peuvent être créés dans des lakehouses et dans des bases de données KQL, et apparaître sous la forme d’un dossier dans le lac. Cela permet à Spark, SQL, intelligence en temps réel et Analysis Services d’utiliser tous les raccourcis lors de l’interrogation des données.
Remarque
Pour plus d’informations sur l’utilisation de raccourcis, consultez la documentation sur les raccourcis OneLake dans la documentation Microsoft Fabric.