Comprendre les principes de base d’un entrepôt de données
Le processus de création d’un entrepôt de données moderne se compose généralement des tâches suivantes :
- Ingestion des données : déplacement des données de systèmes sources vers un entrepôt de données.
- Stockage des données : stockage des données dans un format optimisé pour l’analytique.
- Traitement des données : transformation des données dans un format consommable par les outils analytiques.
- Analyse et remise des données : analyse des données pour obtenir des insights et remise de ces insights à l’entreprise.
Microsoft Fabric permet aux ingénieurs et aux analystes de données d’ingérer, de stocker, de transformer et de visualiser des données dans un seul outil en combinant expérience traditionnelle et « low-code ».
Comprendre l’expérience d’entrepôt de données de Fabric
L’entrepôt de données de Fabric est un entrepôt de données relationnel qui prend en charge toutes les fonctionnalités T-SQL transactionnelles que vous attendez d’un entrepôt de données d’entreprise. Complètement managé, scalable et hautement disponible, il peut être utilisé pour stocker et interroger des données dans le lakehouse. L’entrepôt de données vous permet de contrôler entièrement la création de tables ainsi que le chargement, la transformation et l’interrogation des données à l’aide du portail Fabric ou de commandes T-SQL. Vous pouvez utiliser soit SQL pour interroger et analyser les données, soit Spark pour traiter les données et créer des modèles Machine Learning.
Les entrepôts de données dans Fabric facilitent la collaboration entre les ingénieurs données et les analystes de données, qui partagent alors la même expérience. Les ingénieurs données créent, au-dessus des données dans le lakehouse, une couche relationnelle dans laquelle les analystes peuvent utiliser T-SQL et Power BI pour explorer les données.
Concevoir un entrepôt de données
Comme toutes les bases de données relationnelles, l’entrepôt de données de Fabric contient des tables pour stocker les données à des fins d’analytique. Le plus souvent, ces tables sont organisées dans un schéma optimisé pour la modélisation multidimensionnelle. Dans cette approche, les données numériques liées aux événements (par exemple, les commandes des clients) sont regroupées selon différents attributs (date, client, magasin, etc.). Par exemple, vous pouvez analyser le montant total payé pour les commandes passées à une date spécifique ou dans un magasin particulier.
Tables d’un entrepôt de données
Les tables d’un entrepôt de données sont généralement organisées de manière à analyser efficacement de grandes quantités de données. Cette organisation, souvent appelée « modélisation dimensionnelle », implique de structurer les tables en tables de faits et tables de dimension.
Les tables de faits contiennent les données numériques que vous souhaitez analyser. Les tables de faits comprennent généralement un grand nombre de lignes et constituent la principale source de données pour l’analyse. Par exemple, une table de faits peut contenir le montant total payé pour des commandes passées à une date spécifique ou dans un magasin particulier.
Les tables de dimension contiennent des informations descriptives sur les données contenues dans les tables de faits. Les tables de dimension comprennent généralement un petit nombre de lignes et fournissent le contexte des données des tables de faits. Par exemple, une table de dimension peut contenir des informations sur les clients qui ont passé des commandes.
En plus des colonnes d’attribut, une table de dimension contient une colonne clé unique qui identifie de manière unique chaque ligne de la table. En fait, il est courant pour une table de dimension d’inclure deux colonnes clés :
- Une clé de substitution est un identificateur unique pour chaque ligne de la table de dimension. Il s’agit souvent d’une valeur entière générée automatiquement par le système de gestion de base de données quand une nouvelle ligne est insérée dans la table.
- Une clé secondaire est souvent une clé naturelle ou métier qui identifie une instance spécifique d’une entité dans le système source transactionnel, comme un code produit ou un ID client.
Dans un entrepôt de données, les clés de substitution et les clés secondaires ont des finalités différentes. Vous avez donc besoin des deux. Les clés de substitution sont spécifiques à l’entrepôt de données et contribuent au maintien de la cohérence et de l’exactitude des données. Quant aux clés alternatives, elles sont spécifiques au système source et contribuent au maintien de la traçabilité entre l’entrepôt de données et le système source.
Tables de dimension de type spécial
Les dimensions de type spécial offrent un contexte supplémentaire et permettent une analyse des données plus complète.
Les dimensions de temps fournissent des informations sur la période au cours de laquelle un événement s’est produit. Cette table permet aux analystes de données d’agréger des données sur des intervalles temporels. Par exemple, une dimension de temps peut inclure les colonnes « année », « trimestre », « mois » et « jour » pour indiquer quand une commande a été passée.
Les dimensions à variation lente sont des tables de dimension qui font le suivi des modifications apportées aux attributs de dimension, comme l’adresse d’un client ou le prix d’un produit, au fil du temps. Elles occupent une place importante dans un entrepôt de données, car elles permettent aux utilisateurs d’analyser et de comprendre les modifications apportées aux données dans le temps. Les dimensions à variation lente garantissent que les données sont à jour et exactes, ce qui est primordial pour prendre de bonnes décisions commerciales.
Conceptions de schémas d’entrepôts de données
Dans la plupart des bases de données transactionnelles utilisées dans les applications métier, les données sont normalisées pour réduire la duplication. Mais dans un entrepôt de données, les données de dimension sont généralement dénormalisées pour réduire le nombre de jointures requises pour interroger les données.
Souvent, un entrepôt de données est organisé selon un schéma en étoile, dans lequel une table de faits est directement liée aux tables de dimension, comme le montre cet exemple :
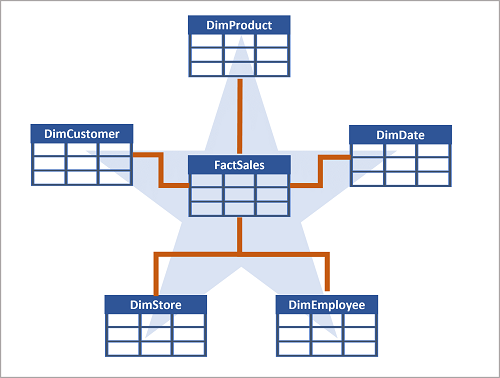
Vous pouvez utiliser les attributs d’un élément pour regrouper des nombres dans la table de faits à différents niveaux. Par exemple, vous pouvez trouver le chiffre d’affaires total d’une région entière ou d’un seul client. Les informations de chaque niveau peuvent être stockées dans la même table de dimension.
Conseil
Pour plus d’informations sur la conception de schémas en étoile pour Fabric, consultez Qu’est-ce qu’un schéma en étoile ?.
S’il existe de nombreux niveaux ou si certaines informations sont partagées par différents éléments, il peut être préférable d’opter pour un schéma en flocon. Voici un exemple :
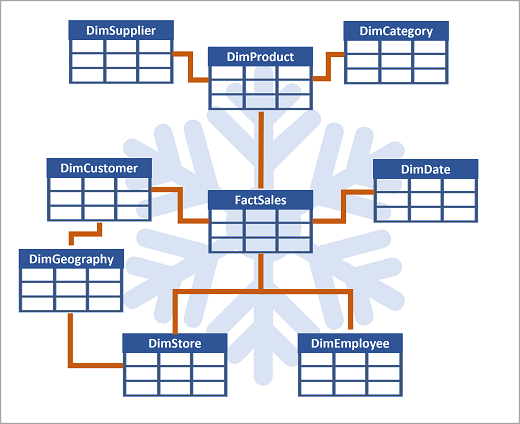
Dans ce cas, la table DimProduct a été fractionnée (normalisée) pour créer des tables de dimension distinctes pour les catégories de produits et les fournisseurs.
- Chaque ligne de la table DimProduct contient des valeurs de clé pour les lignes correspondantes dans les tables DimCategory et DimSupplier.
Une table DimGeography contenant des informations sur l’emplacement des clients et des magasins a été ajoutée.
- Chaque ligne des tables DimCustomer et DimStore contient une valeur de clé pour la ligne correspondante dans la table DimGeography.