Comprendre quand ajuster un modèle de langage
Avant de commencer à ajuster un modèle, vous devez vous assurer de bien comprendre ce qu’est l’ajustement, et quand il convient de l’utiliser.
Lorsque vous souhaitez développer une application de conversation avec Azure AI Foundry, vous pouvez utiliser le flux d'invites pour créer une application de chat intégrée à un modèle de langage pour générer des réponses. Pour améliorer la qualité des réponses générées par le modèle, vous pouvez essayer différentes stratégies. La stratégie la plus simple consiste à appliquer l’ingénierie de prompt. Vous pouvez modifier la façon dont vous mettez en forme votre question, mais vous pouvez également mettre à jour le message système envoyé avec le prompt au modèle de langage.
L’ingénierie de prompt est un moyen rapide et facile d’améliorer comment le modèle agit et ce que le modèle doit savoir. Lorsque vous souhaitez améliorer encore davantage la qualité du modèle, deux techniques courantes sont à votre disposition :
- Génération augmentée de récupération (RAG, Retrieval Augmented Generation) : ancrez vos données en récupérant d’abord le contexte à partir d’une source de données avant de générer une réponse.
- Ajustement : entraînez un modèle de langage de base sur un jeu de données avant de l’intégrer dans votre application.
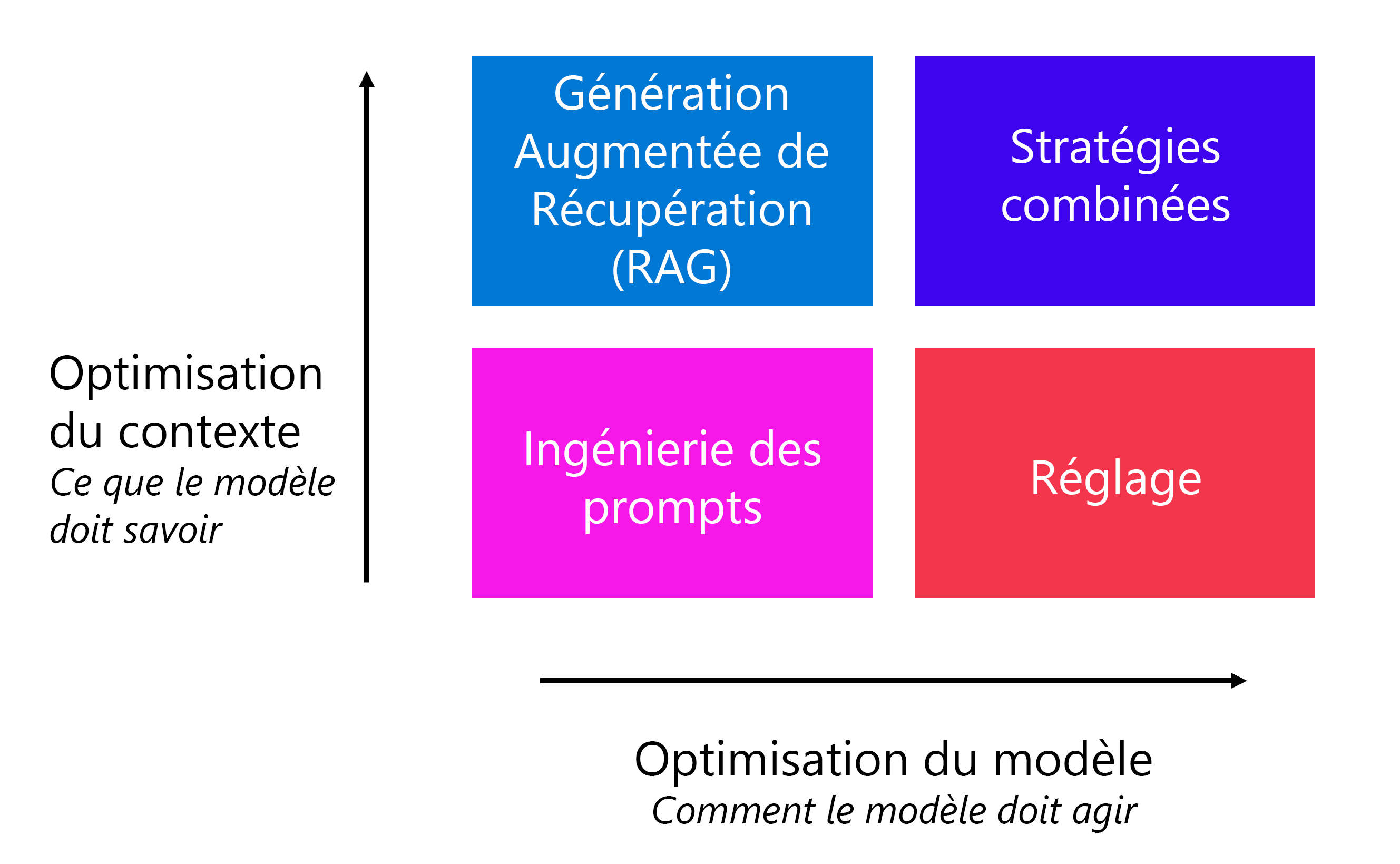
RAG est le plus souvent appliqué lorsque vous avez besoin que les réponses du modèle soient factuelles et ancrées dans des données spécifiques. Par exemple, vous souhaitez que les clients posent des questions sur les hôtels que vous proposez dans votre catalogue de réservations de voyages. En revanche, lorsque vous souhaitez que le modèle se comporte d’une certaine façon, l’ajustement peut vous aider à atteindre votre objectif. Vous pouvez également utiliser une combinaison de stratégies d’optimisation, telles que RAG et un modèle ajusté, pour améliorer votre application de langage.
La façon dont le modèle doit agir concerne principalement le style, le format et le ton des réponses générées par un modèle. Lorsque vous souhaitez que votre modèle respecte un style et un format spécifiques lors de la réponse, vous pouvez lui demander de le faire également par le biais de l’ingénierie de prompt. Toutefois, l’ingénierie de prompt peut parfois ne pas entraîner de résultats cohérents. Il peut toujours arriver qu’un modèle ignore vos instructions et se comporte différemment.
Au sein de l’ingénierie de prompt, une technique utilisée pour « forcer » le modèle à générer la sortie dans un format spécifique consiste à lui fournir différents exemples de ce à quoi la sortie souhaitée peut ressembler, une technique également appelée one-shot (un exemple) ou few-shot (quelques exemples). Toutefois, il peut arriver que votre modèle ne génère pas toujours la sortie dans le style et le format que vous avez spécifiés.
Pour optimiser la cohérence du comportement du modèle, vous pouvez ajuster un modèle de base avec vos propres données d’entraînement.