Explorer l’optimisation de modèles de base dans Azure Machine Learning
Pour optimiser un modèle de base provenant du catalogue de modèles dans Azure Machine Learning, vous pouvez utiliser l’interface utilisateur fournie dans le studio, le SDK Python ou Azure CLI.
Préparer vos données et le calcul
Avant de pouvoir optimiser un modèle de base afin d’améliorer les performances du modèle, vous devez préparer vos données d’entraînement et créer un cluster de calcul GPU.
Conseil
Quand vous créez un cluster de calcul GPU dans Azure Machine Learning, une machine virtuelle optimisée pour GPU est créée pour vous. En savoir plus sur les tailles de machines virtuelles GPU disponibles dans Azure.
Les données d’entraînement peuvent être au format JSON Lines (JSONL), CSV ou TSV. Les spécifications pour vos données varient en fonction de la tâche spécifique pour laquelle vous voulez optimiser votre modèle.
| Tâche | Spécifications pour le jeu de données |
|---|---|
| Classification de texte | Deux colonnes : Sentence (chaîne) et Label (entier/chaîne) |
| Classification de jetons | Deux colonnes : Token (chaîne) et Tag (chaîne) |
| Réponses aux questions | Cinq colonnes : Question (chaîne), Context (chaîne), Answers (chaîne), Answers_start (entier) et Answers_text (chaîne) |
| Résumé | Deux colonnes : Document (chaîne) et Summary (chaîne) |
| Traduction | Deux colonnes : Source_language (chaîne) et Target_language (chaîne) |
Notes
Votre jeu de données doit respecter les spécifications nécessaires. Vous pouvez cependant utiliser des noms de colonnes différents et mapper la colonne à la spécification appropriée.
Quand votre jeu de données et votre cluster de calcul sont prêts, vous pouvez configurer un travail d’optimisation dans Azure Machine Learning.
Choisir un modèle de base
Quand vous accédez au catalogue de modèles dans Azure Machine Learning studio, vous pouvez explorer tous les modèles de base.
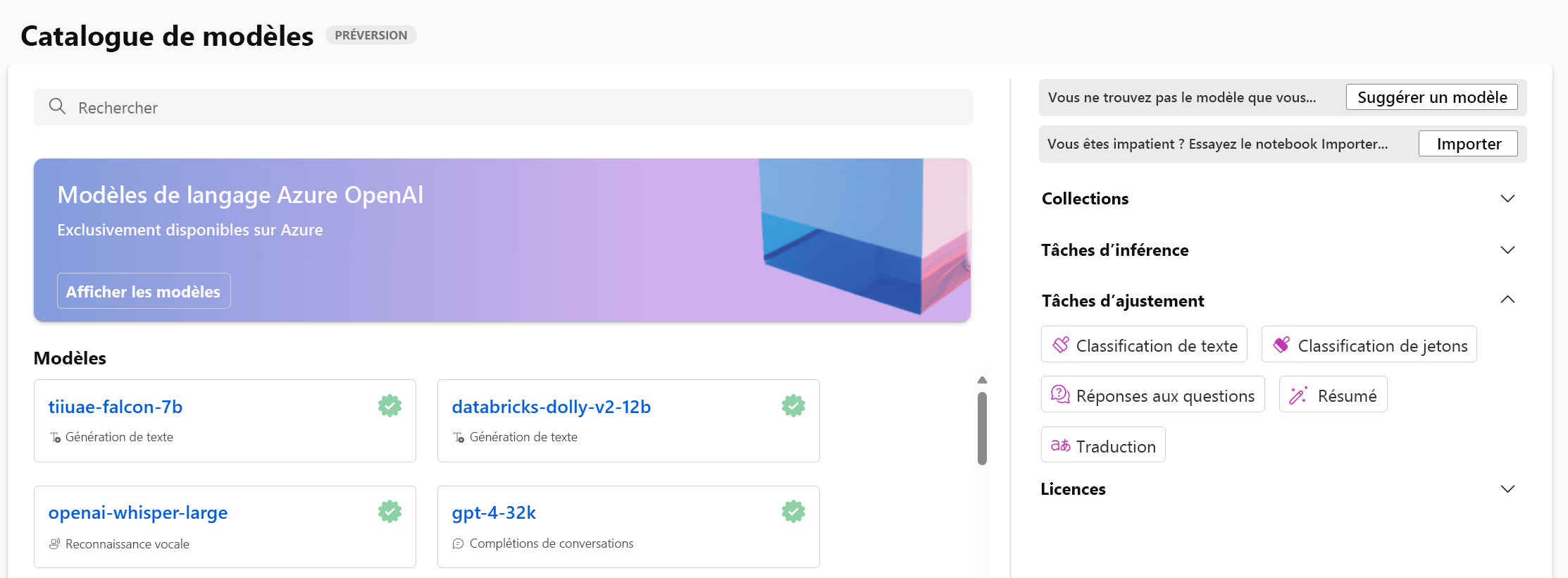
Vous pouvez filtrer les modèles disponibles en fonction de la tâche pour laquelle vous voulez optimiser un modèle. Pour chaque tâche, vous avez le choix entre plusieurs modèles de base. Quand vous choisissez entre plusieurs modèles de base pour une tâche, vous pouvez examiner la description du modèle et la carte du modèle référencé.
Voici quelques considérations que vous pouvez prendre en compte lors du choix d’un modèle de base avant l’optimisation :
- Capacités du modèle : évaluez les capacités du modèle de base et comment il s’aligne avec votre tâche. Par exemple, un modèle comme BERT est mieux adapté à la compréhension de textes courts.
- Données de préentraînement : considérez le jeu de données utilisé pour le préentraînement du modèle de base. Par exemple, GPT-2 est entraîné sur du contenu non filtré provenant d’Internet, ce qui peut entraîner des biais.
- Limitations et biais : tenez compte des limitations ou des biais qui peuvent être présents dans le modèle de base.
- Prise en charge linguistique : recherchez quels modèles offrent la prise en charge linguistique spécifique ou les fonctionnalités multilingues dont vous avez besoin pour votre cas d’usage.
Conseil
Bien que Azure Machine Learning studio vous fournisse des descriptions pour chaque modèle de base dans le catalogue de modèles, vous pouvez également trouver plus d’informations sur chaque modèle via leurs cartes de modèle respectives. Les cartes de modèle sont référencées dans la vue d’ensemble de chaque modèle et hébergées sur le site web de Hugging Face
Configurer un travail d’optimisation
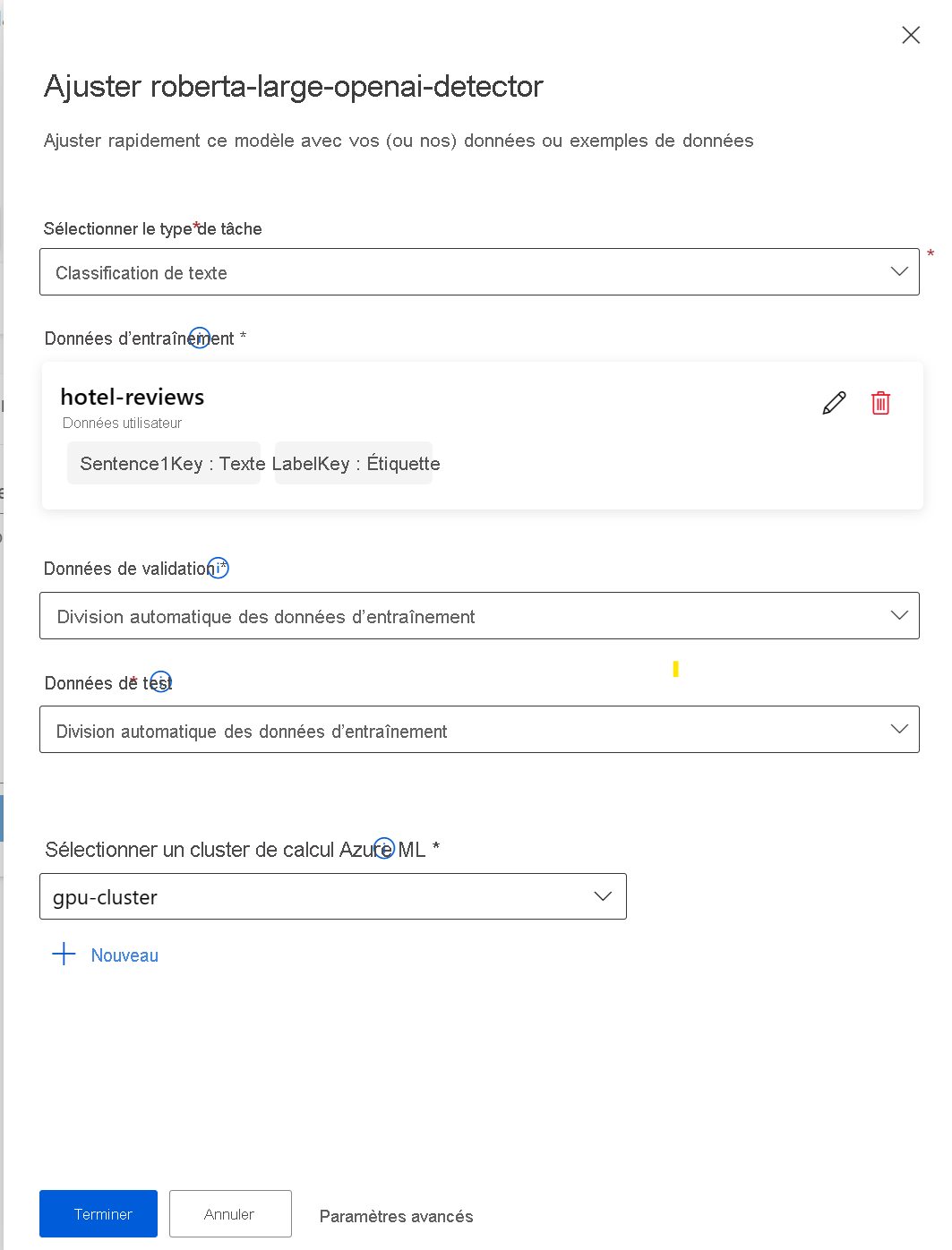
Pour configurer un travail d’optimisations en utilisant Azure Machine Learning studio, vous devez effectuer les étapes suivantes :
- Choisissez un modèle de base.
- Sélectionnez Optimiser pour ouvrir une fenêtre contextuelle qui vous aide à configurer le travail.
- Sélectionnez le type de tâche.
- Sélectionnez les données d’entraînement et mappez les colonnes de vos données d’entraînement aux spécifications du jeu de données.
- Laissez Azure Machine Learning fractionner automatiquement les données d’entraînement pour créer un jeu de données de validation et de test, ou fournissez le vôtre.
- Sélectionnez un cluster de calcul GPU géré par Azure Machine Learning.
- Sélectionnez Terminer pour soumettre le travail d’optimisation.
Conseil
Si vous le souhaitez, vous pouvez explorer les paramètres avancés pour changer des paramètres comme le nom du travail et les paramètres de la tâche d’optimisation (par exemple le taux d’apprentissage).
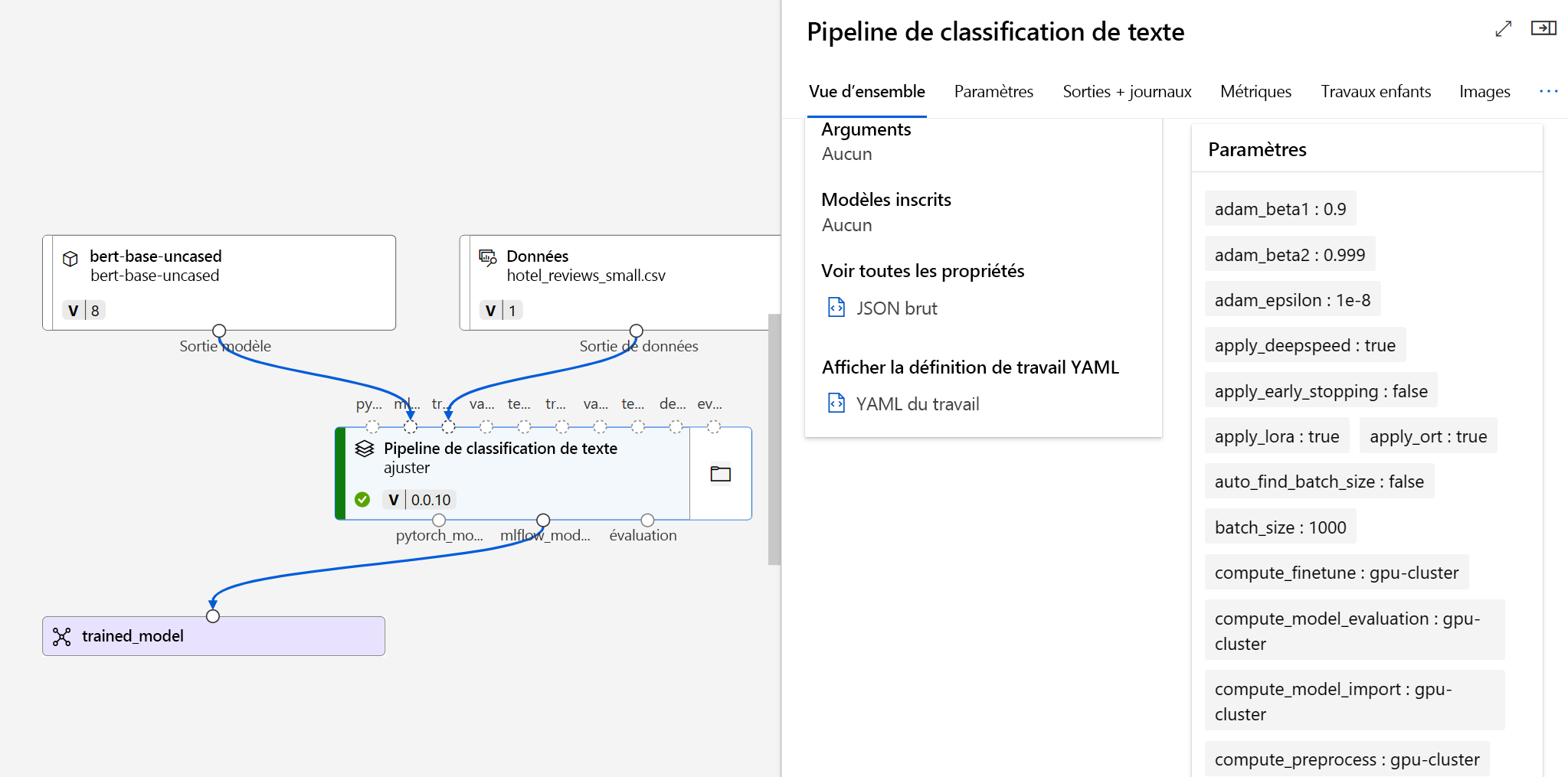
Une fois que vous avez soumis le travail d’optimisation, un travail de pipeline est créé pour entraîner votre modèle. Vous pouvez passer en revue toutes les entrées et collecter le modèle à partir des sorties du travail.