Identifier les plans de requête problématiques
Pour résoudre les problèmes de performances des requêtes, la plupart des administrateurs de bases de données commencent par identifier la requête problématique (en général, la requête qui consomme la plus grande quantité de ressources système), puis ils récupèrent le plan d’exécution de cette requête. Il existe deux scénarios. Dans le premier, les performances de la requête sont systématiquement faibles. Des performances médiocres peuvent résulter de différents problèmes, notamment des contraintes de ressources matérielles (bien que cette situation n’affecte généralement pas les requêtes exécutées seules), une structure de requête non optimale, des paramètres de compatibilité de base de données, des index manquants ou un mauvais choix de plan par l’optimiseur de requête. Dans le deuxième scénario, la requête est performante pour certaines exécutions, mais pas pour d’autres. Ce problème peut être dû à un certain nombre d’autres facteurs, le plus courant étant l’asymétrie des données dans une requête paramétrable ayant un plan efficace pour certaines exécutions, et un plan inefficace pour d’autres. Les autres facteurs courants qui sont responsables de performances de requêtes incohérentes sont les blocages (lorsqu’une requête attend la fin d’une autre requête pour accéder à une table) et la contention matérielle.
Intéressons-nous de plus près à chacun de ces problèmes potentiels.
Contraintes matérielles
Généralement, les contraintes matérielles ne se manifesteront pas lors de l’exécution d’une seule requête. Toutefois, elles seront évidentes quand la charge de production est appliquée et qu’il y a un nombre limité de threads de processeur et une quantité limitée de mémoire à partager entre les requêtes. En cas de contention du processeur, elles sont généralement détectables grâce au compteur de l’Analyseur de performances « % du temps processeur », qui mesure l’utilisation du processeur du serveur. En regardant plus en détail SQL Server, vous verrez les types d’attentes SOS_SCHEDULER_YIELD et CXPACKET si le processeur du serveur est sursollicité. Toutefois, dans certains cas, lorsque les performances du système de stockage sont faibles, même l’exécution d’une requête seule peut être lente. Le mieux est de suivre les performances du système de stockage au niveau du système d’exploitation, à l’aide des compteurs de l’Analyseur de performances « Disque s/lecture » et « Disque s/écriture », qui mesurent le temps nécessaire à l’exécution d’une opération d’E/S. Si SQL Server détecte des performances de stockage faibles (si l’exécution d’une opération d’E/S prend plus de 15 secondes), il l’indiquera dans le journal des erreurs. Si vous voyez un pourcentage élevé d’attentes PAGEIOLATCH_SH dans les statistiques d’attentes SQL Server, vous avez peut-être un problème de performances au niveau du système de stockage. En règle générale, les performances matérielles font l’objet d’un examen général au début de la résolution des problèmes de performances, car elles sont relativement faciles à évaluer.
La plupart des problèmes de performances de base de données sont causés par des modèles de requête non optimaux. Toutefois, dans de nombreux cas, c’est l’exécution de requêtes inefficaces qui soumet votre matériel à une pression excessive. Par exemple, des index manquants peuvent entraîner une sursollicitation du processeur, du stockage et de la mémoire en récupérant plus de données que nécessaire pour traiter la requête. Il est recommandé de corriger les requêtes non optimales avant de résoudre les problèmes matériels. Nous aborderons le paramétrage des requêtes dans la section suivante.
Constructions de requêtes non optimales
Les bases de données relationnelles fonctionnent mieux lorsque vous exécutez des opérations basées sur des jeux de données. Les opérations basées sur des jeux de données effectuent une manipulation de données (INSERT, UPDATE, DELETE ou SELECT) au sein d’un jeu de données. Les opérations sont exécutées sur un ensemble de valeurs, et produisent une valeur unique ou un jeu de résultats. L’alternative aux opérations basées sur des jeux de données sont les opérations basées sur des lignes, qui sont effectuées à l’aide d’un curseur ou d’une boucle while. Ce type de traitement se nomme « traitement basé sur les lignes », et son coût augmente de façon linéaire avec le nombre de lignes impactées. Cette linéarité devient problématique à mesure que grandissent les volumes de données d’une application.
Même s’il est important de détecter les utilisations non optimales d’opérations basées sur des lignes à l’aide de curseurs ou de boucles WHILE, il existe d’autres anti-modèles SQL Server que vous devez savoir reconnaître. Avant SQL Server 2017, les fonctions table (TVF), et en particulier les fonctions table à instructions multiples, entraînaient des modèles de plan d’exécution problématiques. De nombreux développeurs aiment utiliser des fonctions table à instructions multiples, car elles permettent d’exécuter plusieurs requêtes au sein d’une même fonction et d’agréger les résultats au sein d’une même table. Toutefois, toute personne qui écrit du code T-SQL doit être consciente des baisses de performances que peut entraîner l’utilisation de fonctions table.
SQL Server propose deux types de fonctions table : les fonctions table incluses et les fonctions table à instructions multiples. Si vous utilisez une fonction table incluse, le moteur de base de données la traitera comme une vue. Les fonctions table à instructions multiples sont traitées comme les autres tables lors du traitement d’une requête. Étant donné que les fonctions table sont dynamiques et que, par conséquent, SQL Server n’a pas de statistiques les concernant, il utilise un nombre fixe de lignes pour estimer le coût du plan de requête. Un nombre fixe peut convenir si les lignes sont peu nombreuses. Toutefois, si la fonction table retourne des milliers voire des millions de lignes, le plan d’exécution risque d’être inefficace.
Un autre anti-modèle est l’utilisation de fonctions scalaires, qui présentent des problèmes similaires au niveau de l’estimation et de l’exécution. Microsoft a considérablement amélioré les performances avec l’introduction du Traitement intelligent des requêtes, aux niveaux de compatibilité 140 et 150.
SARGability
Dans les bases de données relationnelles, le terme « SARGable » fait référence à un prédicat (clause WHERE) dans un format spécifique qui peut utiliser un index pour accélérer l’exécution d’une requête. Les prédicats qui sont au bon format sont appelés « arguments de recherche » ou SARG. Dans SQL Server, l’utilisation d’un SARG signifie que l’optimiseur effectuera une évaluation à l’aide d’un index non-cluster sur la colonne référencée dans le SARG pour une opération de recherche (SEEK), au lieu d’analyser la totalité de l’index (ou de la table) pour récupérer une valeur.
La présence d’un SARG ne garantit pas l’utilisation d’un index pour une opération SEEK. Les algorithmes d’évaluation des coûts de l’optimiseur peuvent toujours déterminer que l’index était trop coûteux. Cela peut être le cas si un SARG référence un grand pourcentage de lignes dans une table. Si aucun SARG n’est présent, l’optimiseur n’évaluera même pas une opération SEEK sur un index non-cluster.
Les expressions qui ne sont pas des SARG (parfois qualifiées de « non SARGable ») sont, par exemple, celles qui incluent une clause LIKE avec un caractère générique au début de la chaîne à trouver, par exemple : WHERE lastName LIKE ‘%SMITH%’. Les prédicats qui ne sont pas des SARG s’utilisent dans le cadre d’une utilisation de fonctions sur une colonne, par exemple, WHERE CONVERT(CHAR(10), CreateDate,121) = ‘2020-03-22’. Pour identifier les requêtes qui comprennent des expressions non SARGable, vous devez généralement rechercher des analyses d’index ou de table dans les plans d’exécution, là où des recherches (SEEK) sont normalement effectuées.
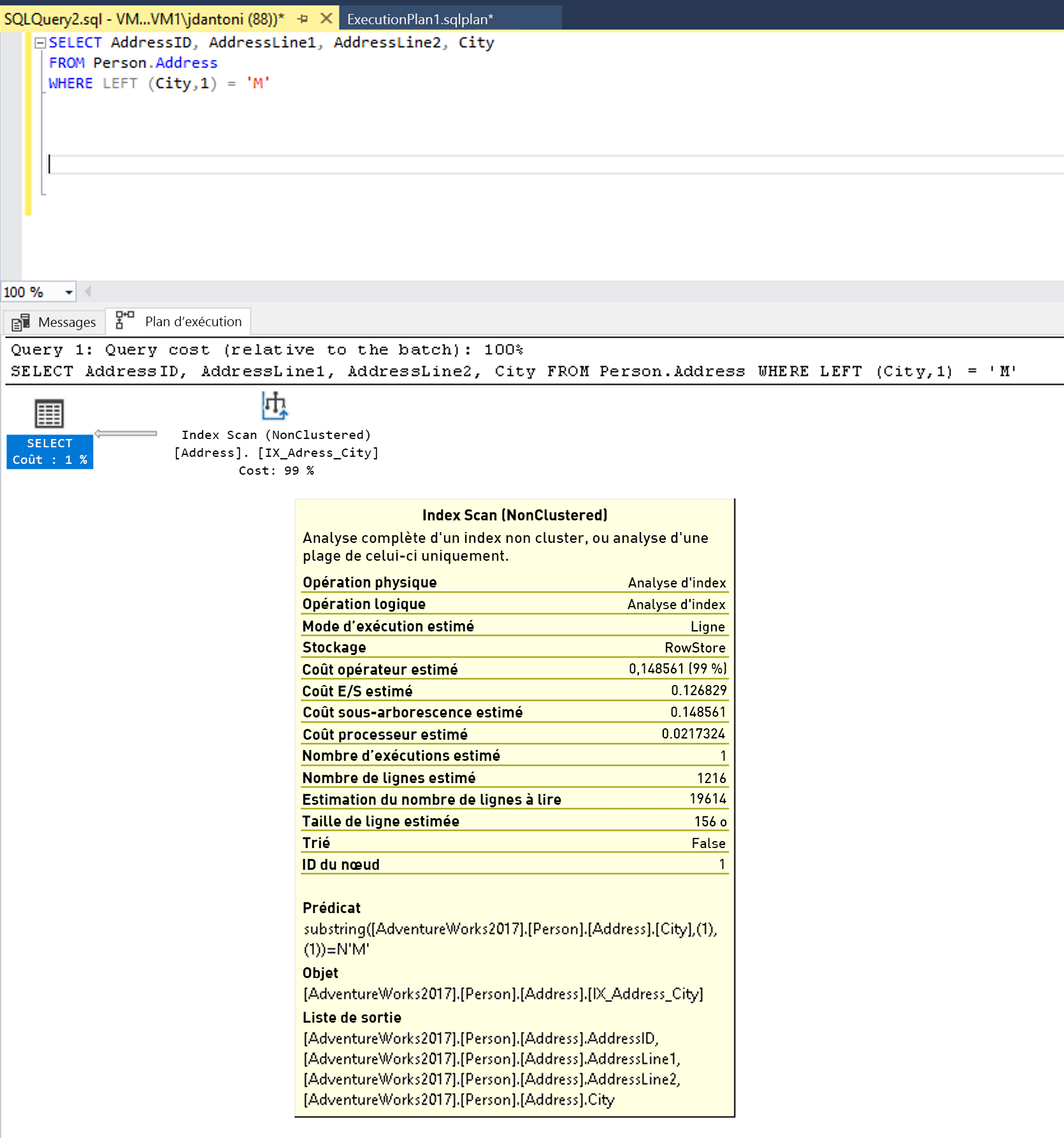
Un index de la colonne City est utilisé dans la clause WHERE de la requête. L’index est utilisé dans le plan d’exécution ci-dessus et vous pouvez voir qu’il est analysé, ce qui signifie qu’il est lu dans son intégralité. La fonction LEFT du prédicat rend cette expression non SARGable. L’optimiseur n’effectuera pas d’évaluation en effectuant une recherche d’index sur l’index de la colonne City.
Cette requête peut être écrite pour utiliser un prédicat SARGable. L’optimiseur évalue ensuite une recherche (SEEK) sur l’index de la colonne City. Un opérateur de recherche d’index lirait un ensemble de lignes bien plus petit, comme indiqué ci-dessous.
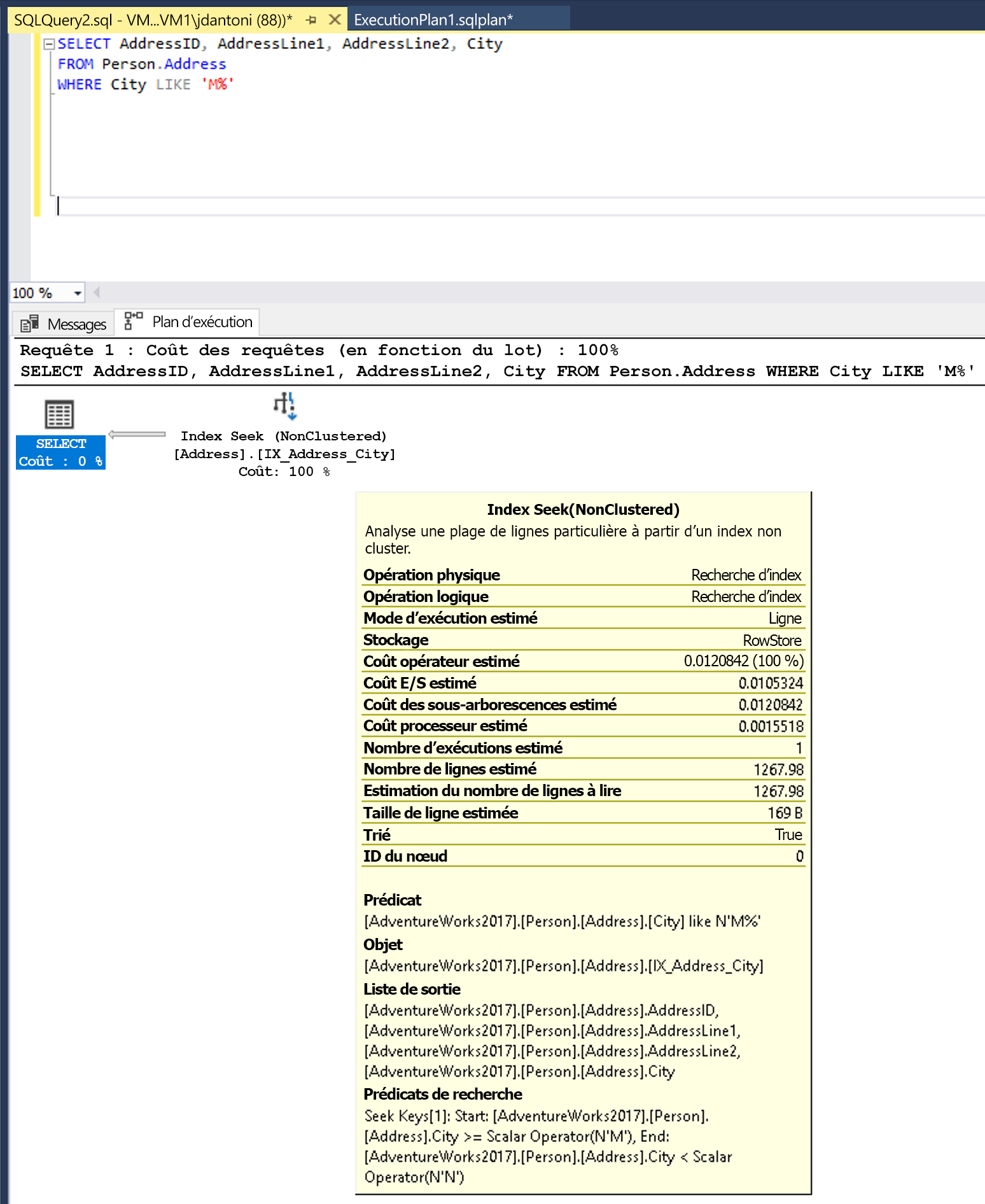
Modification de la fonction LEFT en résultats LIKE dans une recherche d’index.
Remarque
Ici, le mot clé LIKE n’a pas de caractère générique sur sa gauche. Il recherche donc des villes qui commencent par la lettre M. Si le prédicat avait deux côtés ou s’il commençait par un caractère générique (« %M% » ou « %M »), il ne serait pas SARGable. Il est estimé que l’opération SEEK retournera 1 267 lignes, soit environ 15 % de l’estimation de la requête avec le prédicat non SARGable.
D’autres anti-modèles de développement de base de données traitent la base de données comme un service plutôt que comme un magasin de données. L’utilisation d’une base de données pour convertir des données au format JSON, manipuler des chaînes ou effectuer des calculs complexes peut entraîner une utilisation excessive du processeur et une latence accrue. Les requêtes qui tentent de récupérer tous les enregistrements, puis d’effectuer des calculs dans la base de données, peuvent entraîner une utilisation excessive des E/S et du processeur. Dans l’idéal, vous devriez utiliser la base de données pour les opérations d’accès aux données et pour les constructions de base de données optimisées, comme l’agrégation.
Index manquants
Les problèmes de performances les plus courants que nous observons en tant qu’administrateurs de base de données sont dus à un manque d’index utiles, qui oblige le moteur à lire beaucoup plus de pages que nécessaire pour retourner les résultats d’une requête. Même si les index ne sont pas gratuits en termes de ressources (l’ajout d’index à une table peut avoir un impact sur les performances d’écriture et consommer de l’espace), l’amélioration des performances qu’ils fournissent peuvent compenser largement les coûts supplémentaires liés à l’utilisation des ressources. Souvent, les plans d’exécution qui rencontrent des problèmes de performances peuvent être identifiés par l’opérateur de requête Analyse d’index cluster ou par la combinaison des opérateurs Recherche d’index non-cluster et Recherche de clé (qui indique davantage des colonnes manquantes dans un index existant).
Le moteur de base de données tente de résoudre ce problème en signalant les index qui sont manquants dans les plans d’exécution. Les noms et les détails des index recommandés sont disponibles via une vue de gestion dynamique appelée sys.dm_db_missing_index_details. Il existe également d’autres vues de gestion dynamique dans SQL Server comme sys.dm_db_index_usage_stats et sys.dm_db_index_operational_stats, qui mettent en évidence l’utilisation des index existants.
Il peut être judicieux de supprimer un index qui n’est utilisé par aucune requête dans la base de données. Les vues DMV et les avertissements de plan concernant des index manquants doivent être utilisés uniquement comme point de départ pour le paramétrage de vos requêtes. Il est important de savoir quelles sont vos requêtes clés, et de créer des index qui prennent en charge ces requêtes. Il n’est pas recommandé de créer tous les index manquants sans avoir d’abord évalué les index en contexte, les uns par rapport aux autres.
Statistiques manquantes et obsolètes
Vous avez découvert l’importance des statistiques de colonne et d’index pour l’optimiseur de requête. Il est également important de connaître les conditions qui peuvent entraîner des statistiques obsolètes, et savoir de quelle manière ce problème peut se manifester dans SQL Server. Les offres Azure SQL ont par défaut des statistiques de mise à jour automatique définies sur ACTIVÉ. Avant SQL Server 2016, le comportement par défaut de la mise à jour automatique des statistiques était de ne pas mettre à jour les statistiques tant que le nombre de modifications apportées aux colonnes de l’index n’avait pas atteint environ 20 % du nombre de lignes d’une table. En raison de ce comportement, vous pouviez avoir des modifications de données suffisamment importantes pour modifier les performances des requêtes, mais pas pour mettre à jour les statistiques. Les plans qui utilisaient la table avec les données modifiées se basaient sur des statistiques obsolètes et étaient donc souvent peu performants.
Avant SQL Server 2016, vous aviez la possibilité d’utiliser l’indicateur de trace 2371, qui remplaçait le nombre nécessaire de modifications par une valeur dynamique. De cette façon, lorsque la taille de votre table augmentait, le pourcentage de modifications de lignes nécessaire pour déclencher une mise à jour des statistiques était moins élevé. Les versions plus récentes de SQL Server, d’Azure SQL Database et d’Azure SQL Managed Instance prennent en charge ce comportement par défaut. Il existe également une fonction de gestion dynamique appelée sys.dm_db_stats_properties, qui indique la date de la dernière mise à jour des statistiques et le nombre de modifications apportées depuis la dernière mise à jour. De cette façon, vous pouvez identifier rapidement les statistiques qui nécessitent une mise à jour manuelle.
Mauvais choix de l’optimiseur
Même si l’optimiseur de requête optimise correctement la plupart des requêtes, il existe des cas limites où l’optimiseur basé sur les coûts peut prendre des décisions avec un fort impact qui ne sont pas entièrement comprises. Il existe de nombreuses méthodes pour remédier à cela, notamment l’utilisation d’indicateurs de requête ou d’indicateurs de trace, le forçage de plan d’exécution et d’autres ajustements permettant d’obtenir un plan de requête stable et optimal. Microsoft dispose d’une équipe de support qui peut vous aider dans de tels scénarios.
Dans l’exemple ci-dessous issu de la base de données AdventureWorks2017, un indicateur de requête est utilisé pour indiquer à l’optimiseur de base de données qu’il doit toujours utiliser le nom de ville « Seattle ». Ce conseil ne garantira pas le meilleur plan d’exécution pour toutes les valeurs de villes, mais il sera prévisible. La valeur « Seattle » pour @city_name sera utilisée uniquement pendant l’optimisation. Pendant l’exécution, la valeur fournie ((‘Ascheim’)) sera utilisée.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Comme le montre l’exemple, la requête utilise un indicateur (la clause OPTION) pour indiquer à l’optimiseur qu’il doit utiliser une valeur de variable spécifique afin de générer son plan d’exécution.
Détection des paramètres
SQL Server met en cache les plans d’exécution des requêtes en vue d’une utilisation ultérieure. Étant donné que le processus de récupération des plans d’exécution est basé sur la valeur de hachage d’une requête, le texte de la requête doit être identique à chaque exécution pour que le plan mis en cache soit utilisé. Afin de prendre en charge plusieurs valeurs dans une même requête, de nombreux développeurs utilisent des paramètres, passés par le biais de procédures stockées, comme illustré dans l’exemple ci-dessous :
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Les requêtes peuvent également être paramétrées explicitement à l’aide de la procédure sp_executesql. Toutefois, le paramétrage explicite de chaque requête est généralement effectué par le biais de l’application, avec (selon l’API) une forme quelconque de PREPARE et EXECUTE. Lorsque le moteur de base de données exécute cette requête pour la première fois, il optimise la requête en fonction de la valeur initiale du paramètre, dans ce cas 42. Ce comportement appelé « détection des paramètres » permet de réduire la charge de travail globale qui consiste à compiler les requêtes sur le serveur. Toutefois, s’il existe une asymétrie des données, les performances des requêtes pourraient largement varier.
Prenons par exemple une table contenant 10 millions d’enregistrements. Si 99 % de ces enregistrements ont un ID de 1, et si 1 % sont des nombres uniques, les performances seront basées sur l’ID initialement utilisé pour optimiser la requête. Des performances qui fluctuent de manière importante indiquent une asymétrie des données et n’est pas un problème inhérent à la détection des paramètres. Ce comportement est un problème de performances assez courant que vous devez connaître. Vous devez connaître les options qui permettent d’atténuer le problème. Il existe plusieurs façons de résoudre ce problème. Cela dit, chacune présente des inconvénients :
- Utilisez l’indicateur
RECOMPILEdans votre requête ou l’option d’exécutionWITH RECOMPILEdans vos procédures stockées. Cet indicateur entraîne la recompilation de la requête ou de la procédure chaque fois qu’elle est exécutée, ce qui augmente l’utilisation du processeur sur le serveur. Toutefois, la valeur de paramètre actuelle sera toujours utilisée. - Vous pouvez utiliser l’indicateur de requête
OPTIMIZE FOR UNKNOWN. Avec cet indicateur, l’optimiseur peut choisir de ne pas détecter les paramètres et de comparer la valeur à l’histogramme des données de colonne. Cette option ne vous permettra pas d’obtenir le meilleur plan possible, mais elle permet d’avoir un plan d’exécution cohérent. - Réécrivez votre procédure ou vos requêtes en ajoutant une logique autour des valeurs de paramètre de manière à recompiler uniquement pour les paramètres qui sont connus pour causer des problèmes. Dans l’exemple ci-dessous, si le paramètre SalesPersonID est NULL, la requête est exécutée avec
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
L’exemple ci-dessus est une bonne solution, mais il nécessite un effort de développement assez important et une très bonne compréhension de la distribution de vos données. Il peut également nécessiter une maintenance à mesure que les données changent.