Expliquer les plans de requête estimés et les plans de requête réels
Les plans d’exécution réels et les plans d’exécution estimés peuvent être difficiles à distinguer. La différence réside dans le fait que le plan réel comprend des statistiques de runtime qui ne sont pas capturées dans le plan estimé. Les opérateurs utilisés et l’ordre d’exécution sont les mêmes qu’avec le plan estimé, dans presque tous les cas. En outre, pour capturer un plan d’exécution réel, la requête doit être exécutée, ce qui peut prendre du temps, voire être impossible. Par exemple, la requête peut être une instruction UPDATE qui ne peut être exécutée qu’une seule fois. Toutefois, si vous avez besoin de consulter les résultats et le plan d’une requête, vous devez utiliser l’une des options du plan réel.
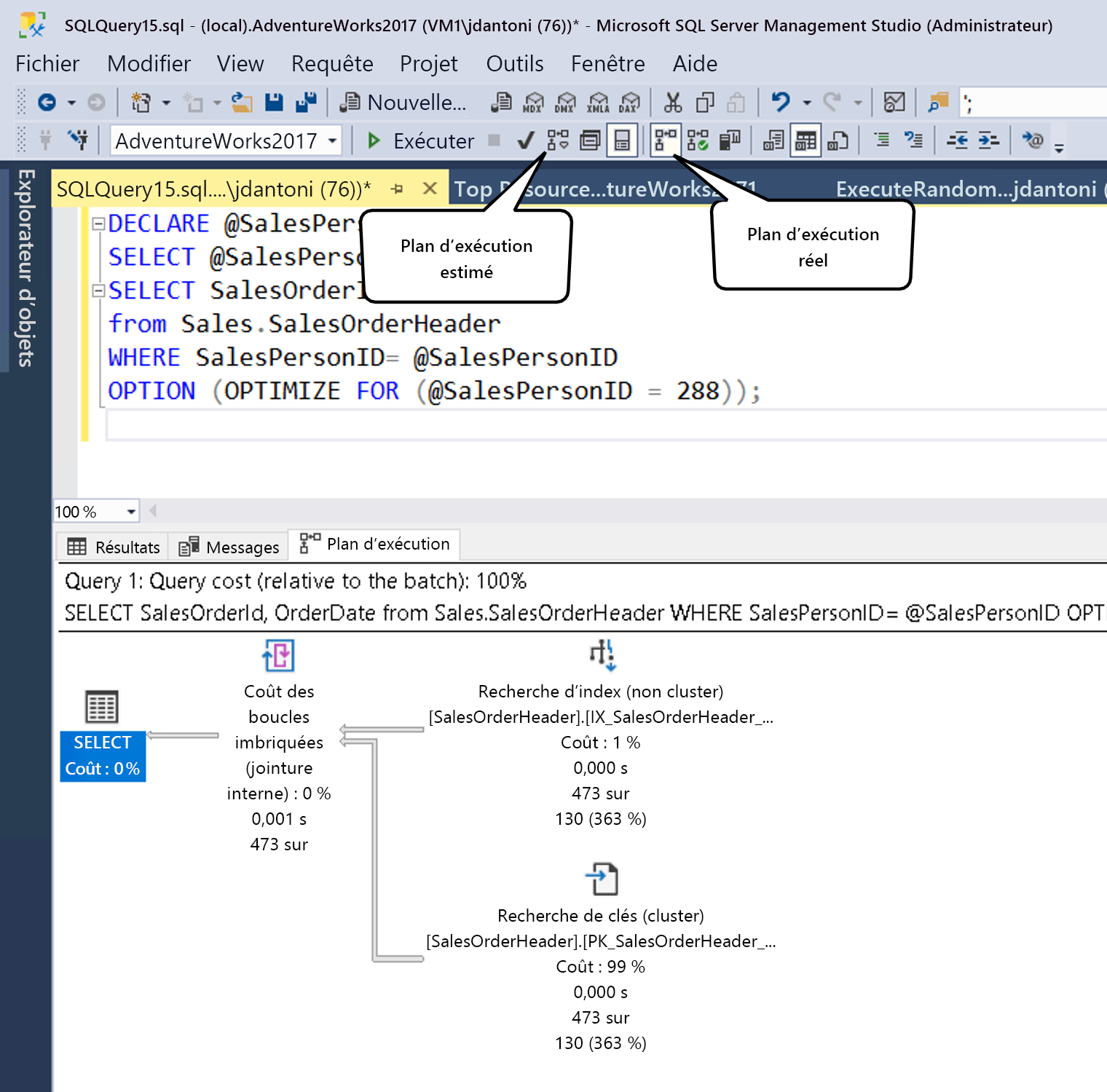
Comme indiqué ci-dessus, vous pouvez générer un plan estimé dans SSMS en cliquant sur le bouton désigné par la zone Plan de requête estimé (ou en utilisant la commande clavier Ctrl + L). Vous pouvez générer le plan réel en cliquant sur l’icône affichée (ou en utilisant le raccourci clavier Ctrl+M), puis en exécutant la requête. Les deux cases d’option fonctionnent un peu différemment. Le bouton Inclure le plan de requête estimé répond immédiatement à la requête sélectionnée (ou à la totalité de l’espace de travail, si rien n’est sélectionné), contrairement au bouton Inclure le plan de requête réel.
L’exécution d’une requête et la génération d’un plan d’exécution estimé impliquent des frais. Vous devez donc afficher les plans d’exécution avec précaution dans votre environnement de production.
Généralement, vous pouvez utiliser le plan d’exécution estimé lors de l’écriture de votre requête, pour comprendre ses caractéristiques de performances, identifier les index manquants ou détecter les anomalies de requête. Le plan d’exécution réel est le mieux adapté pour comprendre les performances d’exécution de la requête et, plus important encore, les écarts de données statistiques qui obligent l’optimiseur de requête à effectuer des choix non optimaux en fonction des données disponibles.
Lire un plan de requête
Les plans d’exécution vous indiquent les tâches qu’effectue le moteur de base de données lorsqu’il récupère les données nécessaires pour répondre à une requête. Penchons-nous sur le plan.
Tout d’abord, voici la requête :
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItemHoldings] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox;
Cette requête joint la table StockItems à la table StockItemHoldings dans lesquelles les valeurs de la colonne StockItemID sont les mêmes. Le moteur de base de données doit d’abord identifier ces lignes avant de pouvoir traiter le reste de la requête.
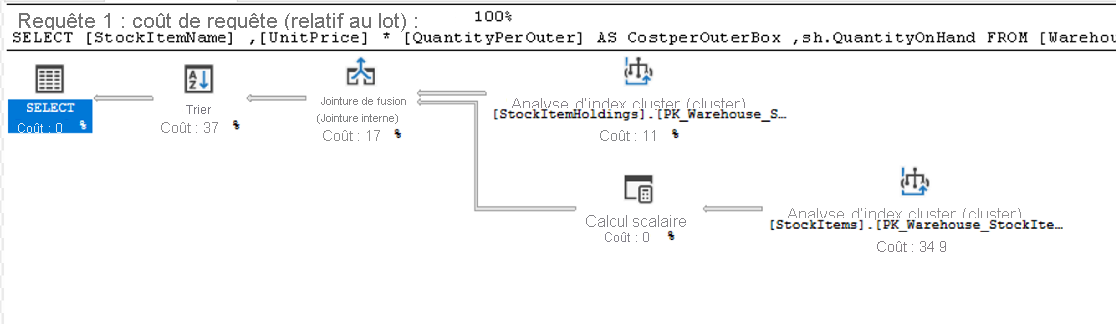
Chaque icône du plan présente une opération spécifique, qui représente les différentes actions et décisions qui composent un plan d’exécution. Le moteur de base de données SQL Server comprend plus de 100 opérateurs de requête qui peuvent créer un plan d’exécution. Vous remarquerez que sous chaque icône d’opérateur se trouve un pourcentage de coût relatif au coût total de la requête. Même une opération qui indique un coût de 0 % implique quand même un coût. En fait, la valeur 0 % est généralement le résultat d’un arrondi, car les coûts des plans graphiques sont toujours affichés comme des nombres entiers, et parce que le pourcentage réel est d’un peu moins de 0,5 %.
Le flux d’exécution d’un plan d’exécution se lit de droite à gauche et de haut en bas. Par conséquent, dans le plan ci-dessus, l’opération d’analyse d’index cluster qui est exécutée sur l’index cluster StockItemHoldings.PK_Warehouse_StockItemHoldings est la première opération de la requête. Les largeurs des lignes qui connectent les opérateurs sont basées sur le nombre estimé de lignes de données qui passent à l’opérateur suivant. Une flèche épaisse indique un important transfert d’opérateur à opérateur, et peut indiquer la nécessité de paramétrer une requête. Vous pouvez également placer votre souris sur un opérateur pour afficher des informations supplémentaires dans une info-bulle, comme indiqué ci-dessous.
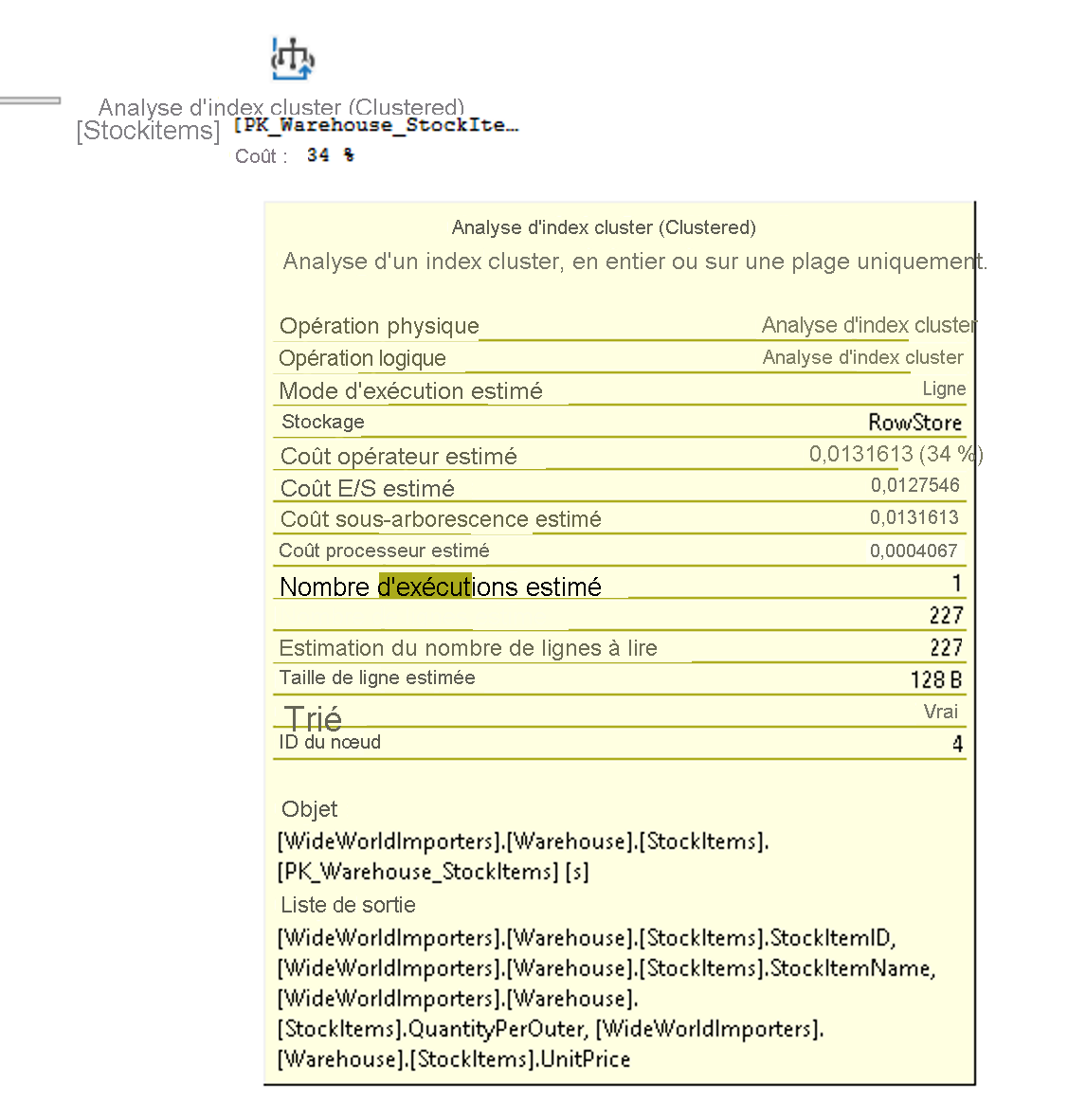
L’info-bulle met en évidence les coûts et les estimations du plan estimé. Pour un plan réel, elle montre la comparaison entre les lignes et les coûts réels, et les estimations. Chaque opérateur a également des propriétés qui sont plus informatives que l’info-bulle. Si vous cliquez avec le bouton droit sur un opérateur, vous pouvez sélectionner l’option Propriétés dans le menu contextuel pour afficher la liste complète des propriétés. Cette option permet d’ouvrir un volet de propriétés distinct dans SQL Server Management Studio, qui est situé sur le côté droit par défaut. Une fois que le volet Propriétés est ouvert, le fait de cliquer sur un opérateur renseigne la liste Propriétés avec les propriétés de cet opérateur. Vous pouvez également ouvrir le volet Propriétés en cliquant sur Afficher dans le menu principal de SQL Server Management Studio, puis en choisissant Propriétés.
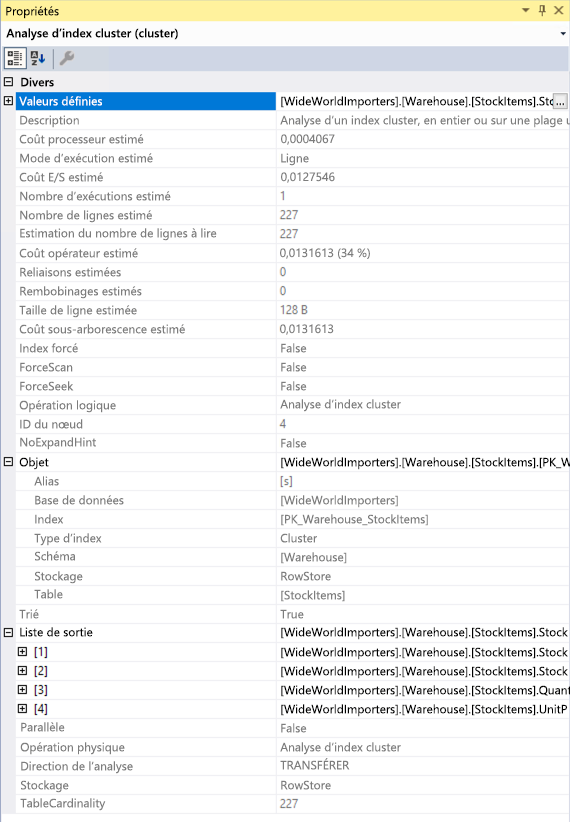
Le volet Propriétés inclut des informations supplémentaires et affiche la liste résultante qui fournit des détails sur les colonnes passées à l’opérateur suivant. Ces colonnes peuvent indiquer qu’un index non cluster est nécessaire pour améliorer les performances de requête lors de leur analyse via une analyse d’index cluster. Étant donné qu’une opération d’analyse d’index cluster lit l’intégralité de la table, dans ce scénario, l’utilisation d’un index non-cluster sur la colonne StockItemID de chaque table peut se révéler plus efficace.
Profilage de requête léger
Comme indiqué ci-dessus, la capture des plans d’exécution réels, qu’il s’agisse d’utiliser SSMS ou l’infrastructure de supervision des événements étendus, peut impliquer des frais importants et n’est généralement effectuée que dans le cadre de la résolution de problèmes concernant des sites actifs. Ces frais, appelés « frais d’observateur », désignent le coût qu’implique la supervision d’une application en cours d’exécution. Dans certains scénarios, ce coût peut se limiter à quelques points de pourcentage en plus concernant l’utilisation du processeur, mais dans d’autres cas, comme la capture de plans d’exécution réels, cela peut ralentir considérablement les performances des requêtes. L’infrastructure de profilage héritée du moteur SQL Server peut engendrer une hausse des frais pouvant aller jusqu’à 75 % pour la capture des informations de requête, tandis que l’infrastructure de profilage légère engendre une hausse maximale de 2 % environ.
Dans la première version de profilage léger collectait le nombre de lignes et les informations relatives à l’utilisation des E/S (le nombre de lectures et d’écritures logiques et physiques effectuées par le moteur de base de données pour satisfaire une requête donnée). En outre, un nouvel événement étendu appelé query_thread_profile a été ajouté pour permettre l’inspection des données de chaque opérateur dans un plan de requête. Dans la version initiale du profilage léger, l’utilisation de cette fonctionnalité nécessitait l’activation globale de l’indicateur de trace 7412.
Dans les versions plus récentes (SQL Server 2016 SP2 CU3, SQL Server 2017 CU11 et SQL Server 2019), si le profilage léger n’est pas activé globalement, vous pouvez utiliser l’indicateur de requête USE HINT avec QUERY_PLAN_PROFILE pour activer le profilage léger au niveau de la requête. Lorsque l’exécution d’une requête ayant cet indicateur est terminée, un événement étendu query_plan_profile est généré, ce qui fournit un plan d’exécution réel. Voici un exemple de requête avec cet indicateur :
SELECT [stockItemName]
,[UnitPrice] * [QuantityPerOuter] AS CostPerOuterBox
,[ QuantityonHand]
FROM [Warehouse].[StockItems] s
JOIN [Warehouse].[StockItems] sh ON s.StockItemID = sh.StockItemID
ORDER BY CostPerOuterBox
OPTION(USE HINT ('QUERY_PLAN_PROFILE'));
Statistiques des derniers plans de requête
SQL Server 2019 et Azure SQL Database prennent en charge deux autres améliorations qui ont été apportées à l’infrastructure de profilage des requêtes. Tout d’abord, le profilage léger est activé par défaut dans SQL Server 2019 et Azure SQL Database Managed Instance. Le profilage léger est également disponible comme une option de configuration étendue à la base de données, appelée LIGHTWEIGHT_QUERY_PROFILING. L’option étendue à la base de données vous permet de désactiver la fonctionnalité pour chaque base de données utilisateur de façon indépendante.
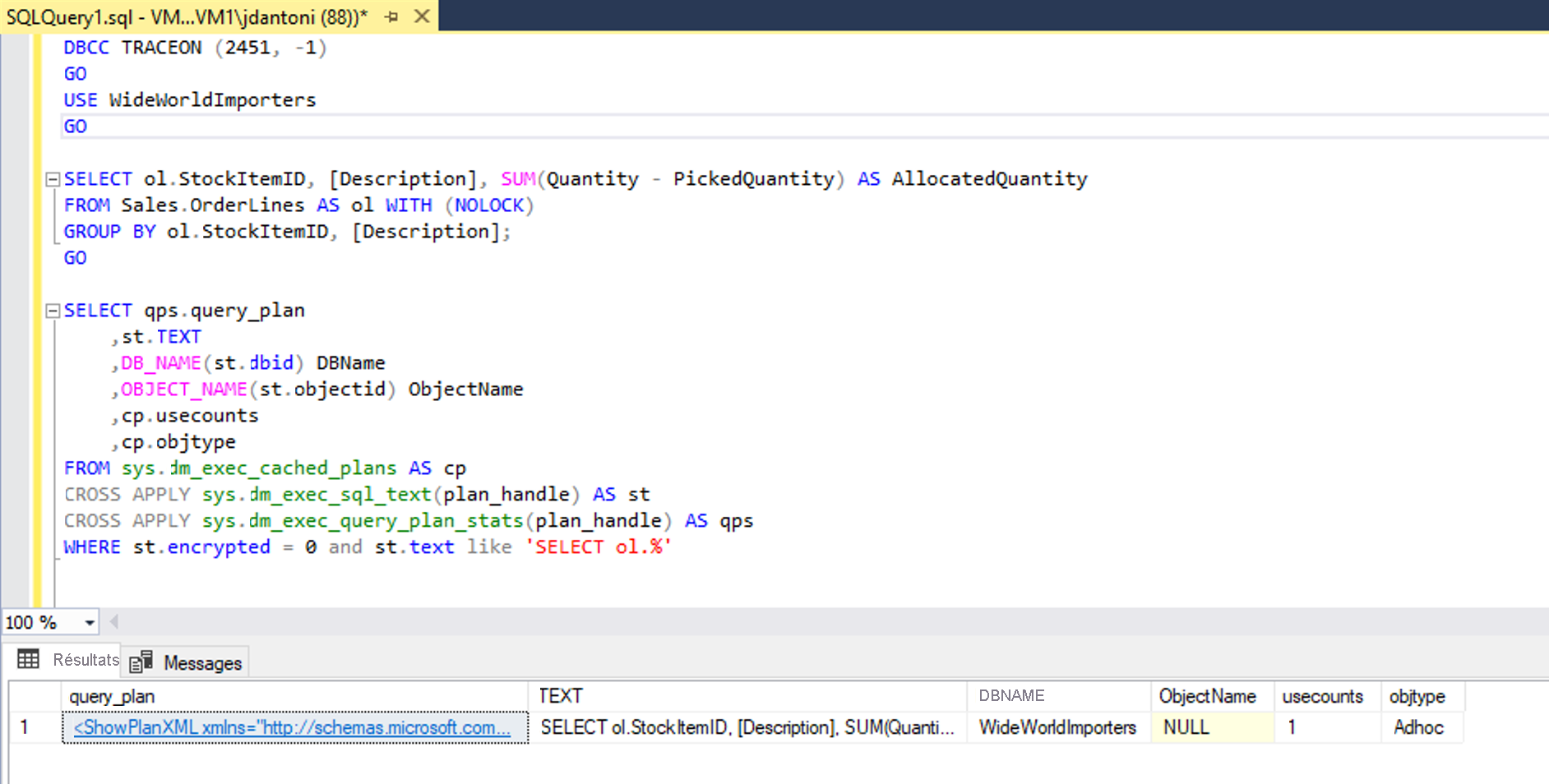
En outre, il existe une nouvelle fonction de gestion dynamique appelée sys.dm_exec_query_plan_stats, qui peut vous indiquer le dernier plan d’exécution de requête réel connu pour un handle de plan donné. Pour afficher le dernier plan de requête réel connu par le biais de la fonction, vous pouvez activer l’indicateur de trace 2451 à l’échelle du serveur. Vous pouvez également activer cette fonctionnalité à l’aide d’une option de configuration étendue à la base de données appelée LAST_QUERY_PLAN_STATS.
Vous pouvez combiner cette fonction avec d’autres objets afin d’obtenir le dernier plan d’exécution pour toutes les requêtes mises en cache, comme indiqué ci-dessous :
SELECT *
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
CROSS APPLY sys.dm_exec_query_plan_stats(plan_handle) AS qps;
GO
Cette fonctionnalité vous permet d’identifier rapidement les statistiques d’exécution de la dernière exécution d’une requête dans votre système, en engendrant que très peu de frais. L’image ci-dessous montre comment récupérer le plan. Si vous sélectionnez le code XML du plan d’exécution, qui se trouve dans la première colonne de résultats, cela affichera le plan d’exécution de la deuxième image ci-dessous.
Comme vous pouvez le voir dans les propriétés de l’Analyse d’index de columnstore, le plan qui a été récupéré dans le cache comprend le nombre réel de lignes extraites de la requête.
