Explorer les éléments courants de l’architecture de traitement par flux
Il existe de nombreuses technologies que vous pouvez utiliser pour implémenter une solution de traitement par flux de données. Bien que des détails d’implémentation spécifiques puissent varier, il y a des éléments communs à la plupart des architectures de diffusion en continu.
Architecture générale pour le traitement par flux
Dans sa forme la plus simple, une architecture de haut niveau pour le traitement par flux ressemble à ceci :
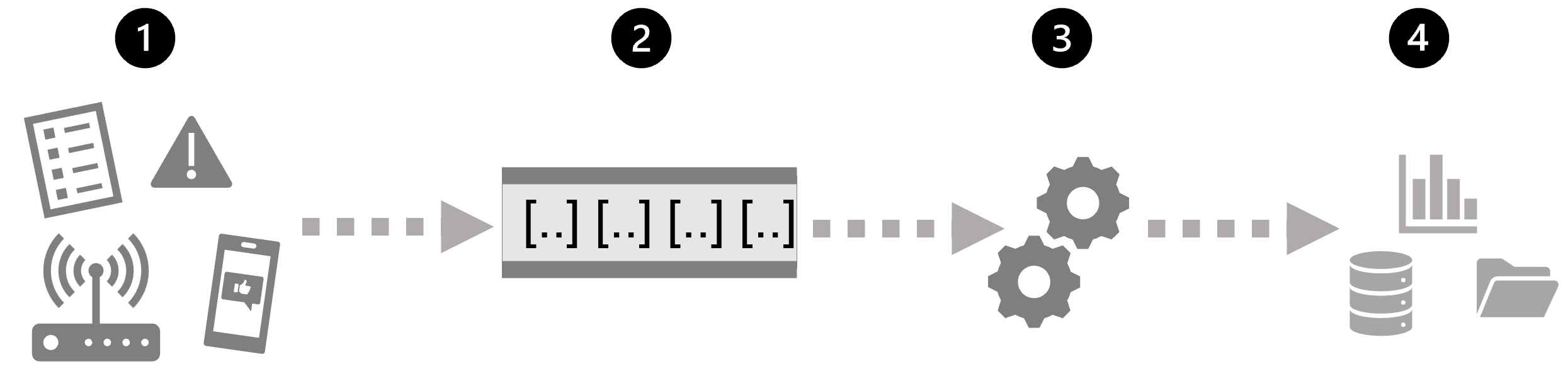
- Un événement génère des données. Il peut s’agir d’un signal émis par un capteur, d’une publication sur les réseaux sociaux, d’une entrée de fichier journal en cours d’écriture ou de toute autre occurrence qui produit des données numériques.
- Les données générées sont capturées dans une source de diffusion en continu pour être traitées. Dans les cas simples, la source peut être un dossier au sein d’un magasin de données Cloud ou une table dans une base de données. Dans les solutions de diffusion en continu plus robustes, la source peut être une « file d’attente » qui encapsule la logique pour s’assurer que les données d’événement sont traitées dans l’ordre et que chaque événement n’est traité qu’une seule fois.
- Les données d’événement sont traitées, souvent par une requête perpétuelle qui opère sur les données d’événement pour sélectionner des données pour des types spécifiques d’événements, des valeurs de données de projet ou des valeurs de données agrégées sur des périodes (ou Windows), par exemple en comptant le nombre d’émissions de capteurs par minute.
- Les résultats de l’opération de traitement par flux sont écrits dans une sortie (ou un récepteur), qui peut être un fichier, une table de base de données, un tableau de bord visuel en temps réel ou une autre file d’attente pour un traitement ultérieur par une requête en aval suivante.
Services d’analyse en temps réel
Microsoft prend en charge plusieurs technologies que vous pouvez utiliser pour implémenter l’analyse en temps réel de données de diffusion en continu, notamment :
- Azure Stream Analytics : Une solution PaaS (Platform-as-a-service) que vous pouvez utiliser pour définir des travaux de diffusion en continu qui ingèrent des données depuis une source de diffusion en continu, appliquent une requête perpétuelle et écrivent les résultats dans une sortie.
- Spark Structured Streaming : bibliothèque open source qui vous permet de développer des solutions de diffusion en continu complexes sur des services Apache Spark, notamment Microsoft Fabric et Azure Databricks.
- Microsoft Fabric : plateforme d’analytique et de base de données hautes performances qui comprend l’engineering données, la fabrique de données, la science des données, l’analyse en temps réel, l’entrepôt de données et les bases de données.
Sources pour le traitement par flux
Les services suivants sont couramment utilisés afin d’ingérer des données pour le traitement par flux dans Azure :
- Azure Event Hubs : Un service d’ingestion de données que vous pouvez utiliser pour gérer des files d’attente de données d’événement, garantissant que chaque événement est traité dans l’ordre, exactement une seule fois.
- Azure IoT Hub : Un service d’ingestion de données qui est similaire à Azure Event Hubs, mais qui est optimisé pour la gestion des données d’événement provenant d’appareils IoT (Internet des objets).
- Azure Data Lake Store Gen 2 : Un service de stockage hautement évolutif qui est souvent utilisé dans les scénarios de traitement par lots, mais qui peut également être utilisé comme source de données de diffusion en continu.
- Apache Kafka : Une solution d’ingestion de données open source couramment utilisée avec Apache Spark.
Récepteurs pour le traitement par flux
La sortie du traitement par flux est souvent envoyée aux services suivants :
- Azure Event Hubs : utilisé pour la mise en file d’attente des données traitées pour un traitement en aval supplémentaire.
- Azure Data Lake Store Gen 2, Microsoft OneLake ou Stockage Blob Azure : Utilisé pour conserver les résultats traités sous forme de fichier.
- Azure SQL Database, Azure Databricks ou Microsoft Fabric : Utilisé pour conserver les résultats traités dans une table pour permettre l’interrogation et l’analyse.
- Microsoft Power BI : permet de générer des visualisations de données en temps réel dans les rapports et les tableaux de bord.