Comment est générée une requête KQL
Maintenant que vous êtes familiarisé avec le fonctionnement des langages de requête et l’endroit où KQL peut être utilisé, nous allons explorer la façon dont une requête KQL est générée.
Structure de requête KQL
Une requête Kusto est une requête en lecture seule de traitement de données et de retour de résultats. La requête est formulée en texte brut en utilisant un modèle de flux de données facile à lire, à créer et à automatiser.
Les différents langages de requête ont souvent des structures différentes. KQL est organisé en fonction de la façon dont les données sont traitées. Chaque requête KQL commence par la source de données. Les données sont ensuite traitées en passant dans des conditions, puis triées et réduites avec un filtre.
Traitement des données
Imaginez que les données transitent par un entonnoir de traitement de données. L’entrée tabulaire est le début de l’entonnoir de données. Ces données sont canalisées vers la ligne suivante, et filtrées ou manipulées avec un opérateur. Les données survivantes sont dirigées vers la ligne suivante, et ainsi de suite jusqu’à ce qu’elles arrivent à la sortie de requête finale. Cette sortie de requête est renvoyée dans un format tabulaire.
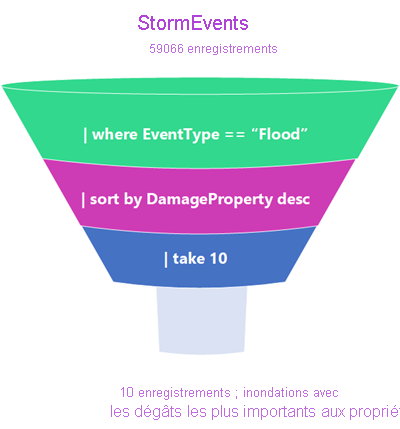
Vous pouvez voir d’après la forme du filtre que les données situées en haut de l’entonnoir ont une taille supérieure à celle des données en bas. Les étapes qui suppriment les plus grandes quantités de données sont généralement utilisées au début de la requête. De cette façon, les opérateurs suivants ont une plus petite quantité de données à traiter et le résultat de la requête est retourné rapidement. En fait, un des avantages de KQL est sa capacité à traiter rapidement d’énormes quantités de données très variées.