Identifier les formats de données
Les données sont un ensemble de faits comme des chiffres, des descriptions et des observations utilisés pour enregistrer des informations. Les structures de données dans lesquelles ces données sont organisées représentent souvent des entités importantes pour une organisation (par exemple des clients, des produits, des commandes, etc.) Chaque entité a généralement un ou plusieurs attributs ou caractéristiques (par exemple, un client a probablement un nom, une adresse, un numéro de téléphone, etc.).
Vous pouvez classer les données en données structurées, semi-structurées ou non structurées.
Données structurées
Les données structurées sont des données qui respectent un schéma fixe. Toutes les données ont donc les mêmes champs ou propriétés. Le plus souvent, le schéma pour les entités de données structurées est tabulaire : en d’autres termes, les données sont représentées dans une ou plusieurs tables qui se composent de lignes pour représenter chaque instance d’une entité de données, et de colonnes pour représenter les attributs de l’entité. Par exemple, l’image suivante montre des représentations de données tabulaires pour les entités Client et Produit.
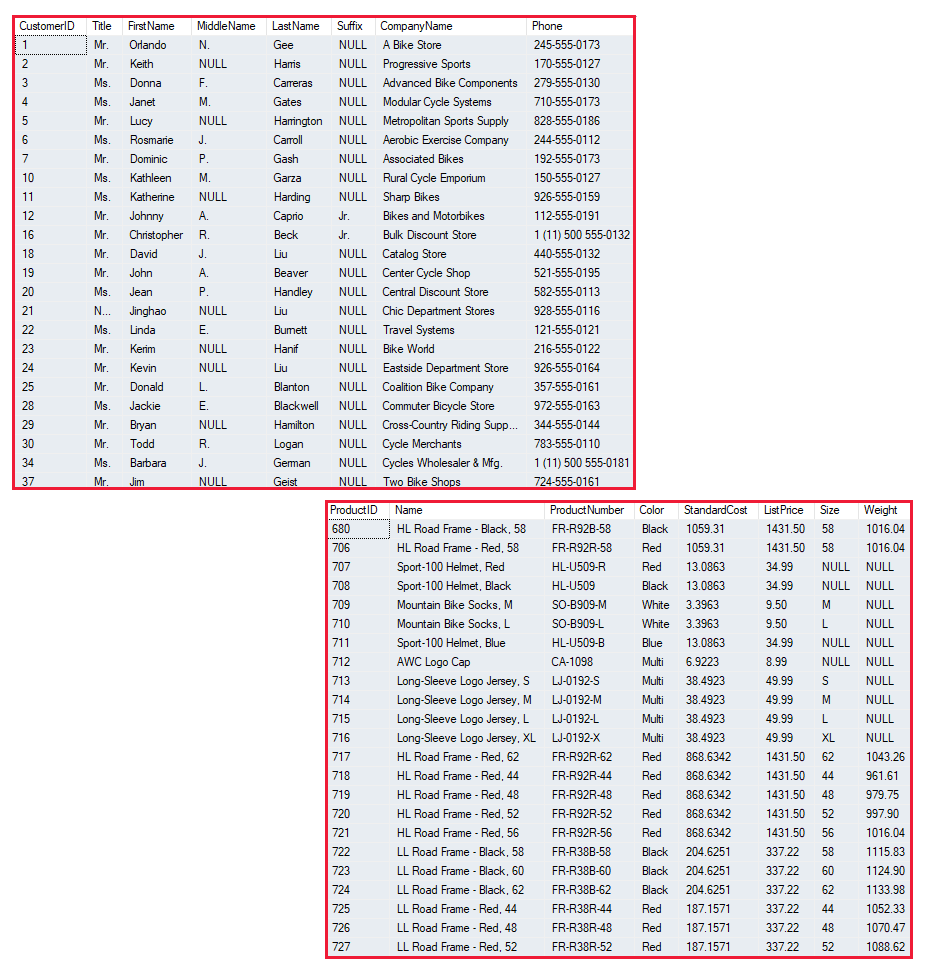
Les données structurées sont souvent stockées dans une base de données dans laquelle plusieurs tables peuvent se référencer les unes aux autres avec des valeurs clés dans un modèle relationnel, que nous explorerons plus en détail ultérieurement.
Données semi-structurées
Les données semi-structurées sont des informations qui ont une certaine structure, mais qui autorise une certaine variation entre les instances d’entité. Par exemple, même si la plupart des clients ont une adresse e-mail, certains peuvent en avoir plusieurs, tandis que d’autres peuvent en avoir aucune.
Un format commun pour les données semi-structurées est JavaScript Object Notation (JSON). L’exemple ci-dessous montre une paire de documents JSON représentant des informations sur les clients. Chaque document client comprend des informations d’adresse et de contact, mais les champs spécifiques varient d’un client à l’autre.
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
// Customer 2
{
"firstName": "Samir",
"lastName": "Nadoy",
"address":
{
"streetAddress": "123 Elm Pl.",
"unit": "500",
"city": "Seattle",
"state": "WA",
"postalCode": "98999"
},
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
Notes
JSON n’est qu’un des nombreux moyens de représenter les données semi-structurées. Le sujet ici n’est pas de fournir une étude détaillée de la syntaxe JSON, mais plutôt d’illustrer la nature flexible des représentations de données semi-structurées.
Les données non structurées
Les données ne sont pas toutes structurées ou même semi-structurées. Par exemple, les documents, les images, les données audio et vidéo et les fichiers binaires risquent de ne pas avoir de structure spécifique. Ce type de données est appelé données non structurées.

Magasins de données
En général, les organisations stockent des données au format structuré, semi-structuré ou non structuré pour enregistrer les détails des entités (par exemple, clients et produits), des événements spécifiques (comme les transactions commerciales) ou autres informations dans des documents, des images et autres formats. Les données stockées peuvent ensuite être récupérées pour l’analyse et le rapport ultérieurement.
Il existe deux grandes catégories de magasins de données couramment utilisés :
- Magasins de fichiers
- Bases de données
Nous allons explorer ces deux types de magasin de données dans les rubriques suivantes.