Explorer le hub Superviser
Utilisez le hub Superviser pour voir les exécutions de pipeline et de déclencheur, l’état des différents runtimes d’intégration en cours d’exécution ainsi que les travaux Apache Spark, demandes SQL et activités de débogage du flux de données.
Sélectionnez le hub Superviser.
Le hub Superviser est votre première source d’informations pour déboguer des problèmes et obtenir des insights sur l’utilisation des ressources. Vous pouvez voir un historique de toutes les activités qui se produisent dans l’espace de travail et celles qui sont actuellement actives.
Faites apparaître chacune des catégories de supervision regroupées sous Intégration et Activités.
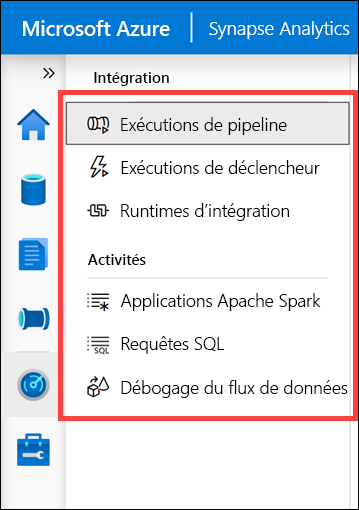
- Exécutions de pipeline présente toutes les activités liées aux exécutions de pipeline. Vous pouvez voir les détails des exécutions, notamment les entrées et sorties des activités, et les messages d’erreur qui se sont produits. Vous pouvez également venir ici pour arrêter un pipeline si nécessaire.
- Exécutions de déclencheur présente toutes les exécutions de pipeline provoquées par des déclencheurs automatisés. Vous pouvez créer des déclencheurs qui s’exécutent selon une planification récurrente ou une fenêtre bascule. Vous pouvez également créer des déclencheurs basés sur des événements qui exécutent un pipeline chaque fois qu’un objet blob est créé ou supprimé dans un conteneur de stockage.
- Runtimes d’intégration présente l’état de tous les runtimes d’intégration Azure et auto-hébergés.
- Applications Apache Spark présente toutes les applications Spark qui sont en cours d’exécution ou qui ont été exécutées dans votre espace de travail.
- Demandes SQL présente tous les scripts SQL qui ont été exécutés soit directement par vous ou un autre utilisateur, soit d’une autre manière (par exemple, à partir d’une exécution de pipeline).
- Débogage du flux de données présente les sessions de débogage actives et précédentes. Quand vous créez un flux de données, vous pouvez activer le débogueur et exécuter le flux de données sans avoir besoin de l’ajouter à un pipeline et de déclencher une exécution. Le débogueur accélère et simplifie le processus de développement. Étant donné que le débogueur nécessite un cluster Spark actif, vous devrez peut-être attendre quelques minutes avant de pouvoir l’utiliser après son activation.
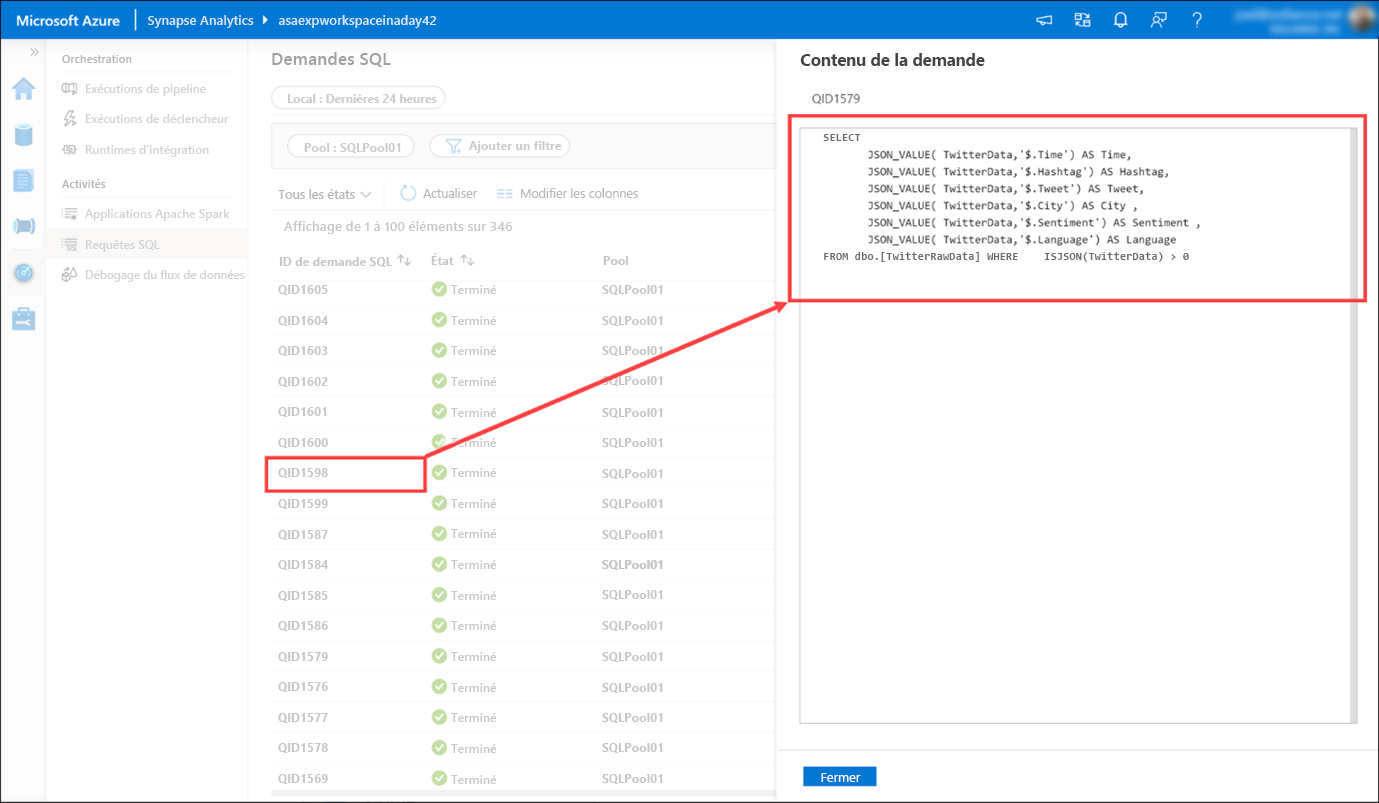
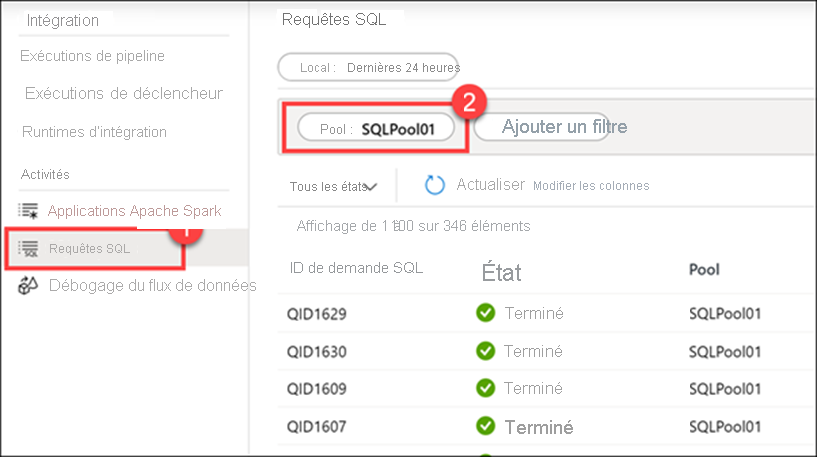
Sélectionnez Demandes SQL (1), puis passez au pool SQLPool01 (2) pour voir la liste des demandes SQL.
Pointez sur une demande SQL, puis sélectionnez l’icône Contenu de la demande pour afficher la demande SQL qui a été envoyée au pool SQL. Vous devrez peut-être en essayer quelques-unes avant d’en trouver une avec un contenu intéressant.
Vous pouvez afficher plus de détails.