Exploration de données avec NumPy et Pandas
Les scientifiques des données peuvent utiliser différents outils et appliquer différentes techniques pour explorer, visualiser et manipuler les données. L’une des méthodes les plus courantes pour les scientifiques de données de travailler avec les données est d’utiliser le langage Python et certains packages spécifiques pour le traitement des données.
Qu’est-ce que NumPy ?
NumPy est une bibliothèque Python qui offre des fonctionnalités comparables à celles d’outils mathématiques comme MATLAB et R. Bien que NumPy simplifie considérablement l’expérience utilisateur, il offre également des fonctions mathématiques complètes.
Qu’est-ce que Pandas ?
Pandas est une bibliothèque Python extrêmement populaire pour l’analyse et la manipulation de données. Pandas se présente comme une application de tableur pour Python. Elle fournit des fonctionnalités faciles à utiliser pour les tables de données.
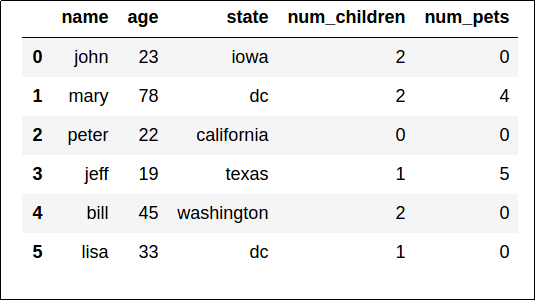
Explorer les données dans un Jupyter Notebook
Les notebooks Jupyter représentent un moyen courant d’exécuter des scripts de base avec un navigateur web. En règle générale, Ces notebooks sont une seule page Web, divisée en sections de texte et de code qui sont exécutées sur le serveur plutôt que sur votre machine locale. En exécutant du code dans les notebooks Jupyter sur un serveur, vous pouvez commencer rapidement sans avoir besoin d’installer Python ou d’autres outils sur votre ordinateur local.
Test des hypothèses
L’exploration et l’analyse des données désignent généralement des processus itératifs dans lesquels les scientifiques des données effectuent les types de tâches suivants pour analyser un échantillon de données et tester des hypothèses :
- Nettoyer les données pour résoudre les erreurs, les valeurs manquantes et d’autres problèmes
- Appliquer des techniques statistiques pour mieux comprendre les données et comment l’échantillon pourrait représenter la population réelle de données, en tenant compte d’une variation aléatoire.
- Visualiser les données pour déterminer les relations entre les variables et, dans le cas d’un projet de Machine Learning, identifier les caractéristiques potentiellement prédictives de l’étiquette
- Réviser l’hypothèse et répéter le processus.