Décrire l’architecture d’entreposage de données
L’architecture d’analytique de données à grande échelle peut varier, tout comme les technologies spécifiques utilisées pour l’implémenter. Toutefois, les éléments suivants sont généralement inclus :
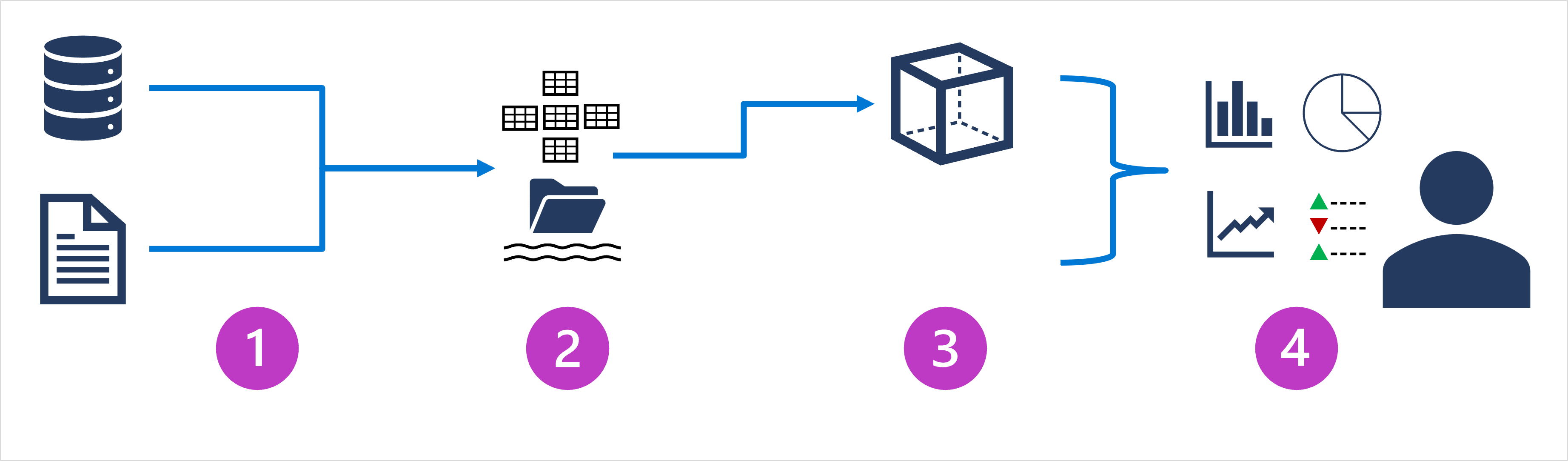
- Ingestion et traitement des données – Les données d’un ou de plusieurs magasins de données transactionnels, de fichiers, de flux en temps réel ou autres sources sont chargées dans un lac de données ou un entrepôt de données relationnelles. L’opération de chargement implique généralement un processus d’extraction, de transformation et de chargement (ETL) ou d’extraction, de chargement et de transformation (ELT) où les données sont nettoyées, filtrées et restructurées pour les analyser. Dans les processus ETL, les données sont transformées avant d’être chargées dans un magasin analytique, tandis que dans un processus ELT, les données sont copiées dans le magasin puis transformées. Dans les deux cas, la structure de données résultante est optimisée pour les requêtes analytiques. Le traitement des données est souvent effectué par des systèmes distribués qui peuvent traiter de grands volumes de données en parallèle à l’aide de clusters multinœuds. L’ingestion de données comprend le traitement par lots des données statiques et le traitement en temps réel des données de streaming.
- Magasin de données analytique – Les magasins de données pour l’analytique à grande échelle comprennent des entrepôts de données relationnelles, des lacs de données basés sur des systèmes de fichiers, ainsi que des architectures hybrides qui combinent les fonctionnalités des entrepôts de données et des lacs de données (parfois appelés lakehouses de données ou bases de données lac). Nous aborderons ces sujets plus en détail ultérieurement.
- Modèle de données analytiques – Alors que les analystes Données et les scientifiques des données peuvent travailler avec les données directement dans le magasin de données analytique, il est courant de créer un ou plusieurs modèles de données qui pré-agrègent les données pour faciliter la génération de rapports, de tableaux de bord et de visualisations interactives. Ces modèles de données sont souvent décrits comme des cubes, dans lesquels les valeurs de données numériques sont agrégées sur une ou plusieurs dimensions (par exemple, pour déterminer le total des ventes par produit et par région). Le modèle encapsule les relations entre les valeurs de données et les entités dimensionnelles pour prendre en charge une analyse à plusieurs niveaux.
- Visualisation des données – Les analystes Données utilisent les données à partir des modèles analytiques et directement à partir des magasins analytiques pour créer des rapports, des tableaux de bord et autres visualisations. De plus, les utilisateurs d’une organisation qui ne sont peut-être pas des professionnels des technologies peuvent faire des analyses et des rapports de données en libre-service. Les visualisations issues des données montrent les tendances, les comparaisons et les indicateurs de performance clés (KPI) d’une entreprise ou autre organisation, et peuvent prendre la forme de rapports imprimés, de graphiques et de diagrammes dans des documents ou des présentations PowerPoint, des tableaux de bord web et des environnements interactifs où les utilisateurs peuvent explorer les données visuellement.