Évaluer les performances du modèle
Il est essentiel d’évaluer les performances de votre modèle à différentes phases pour garantir son efficacité et sa fiabilité. Avant d’explorer les différentes options, vous devez évaluer votre modèle, examinons les aspects de votre application que vous pouvez évaluer.
Lorsque vous développez une application d’IA générative personnalisée, vous utilisez un modèle de langage dans votre application de conversation pour générer une réponse. Pour vous aider à déterminer le modèle que vous souhaitez intégrer à votre application, vous pouvez évaluer les performances d’un modèle de langage individuel :
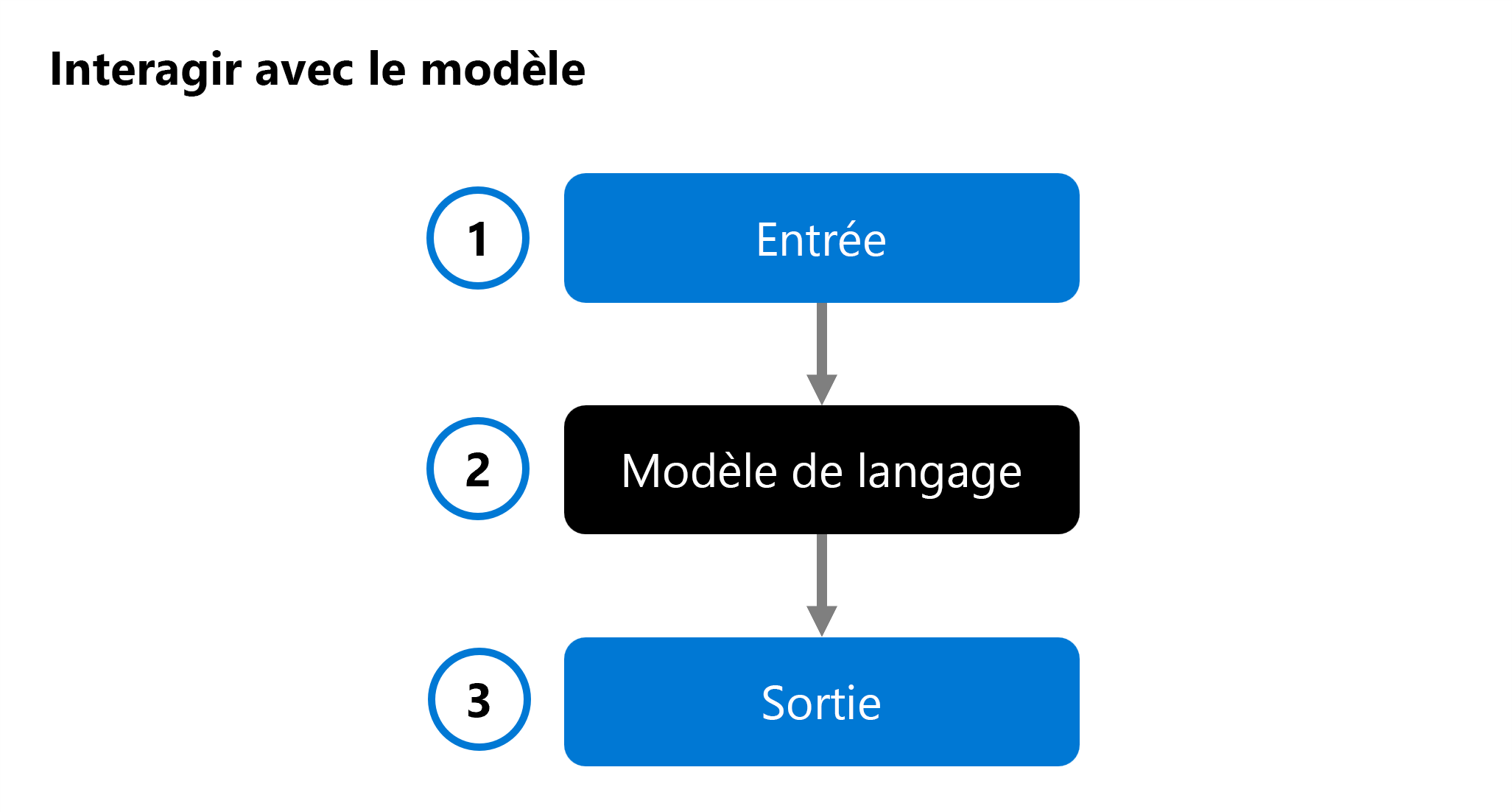
Une entrée (1) est fournie à un modèle de langage (2) et une réponse est générée en tant que sortie (3). Le modèle est ensuite évalué en analysant l’entrée, la sortie et éventuellement en la comparant à la sortie attendue prédéfinie.
Lorsque vous développez une application IA générative, vous intégrez un modèle de langage dans un flux de conversation :
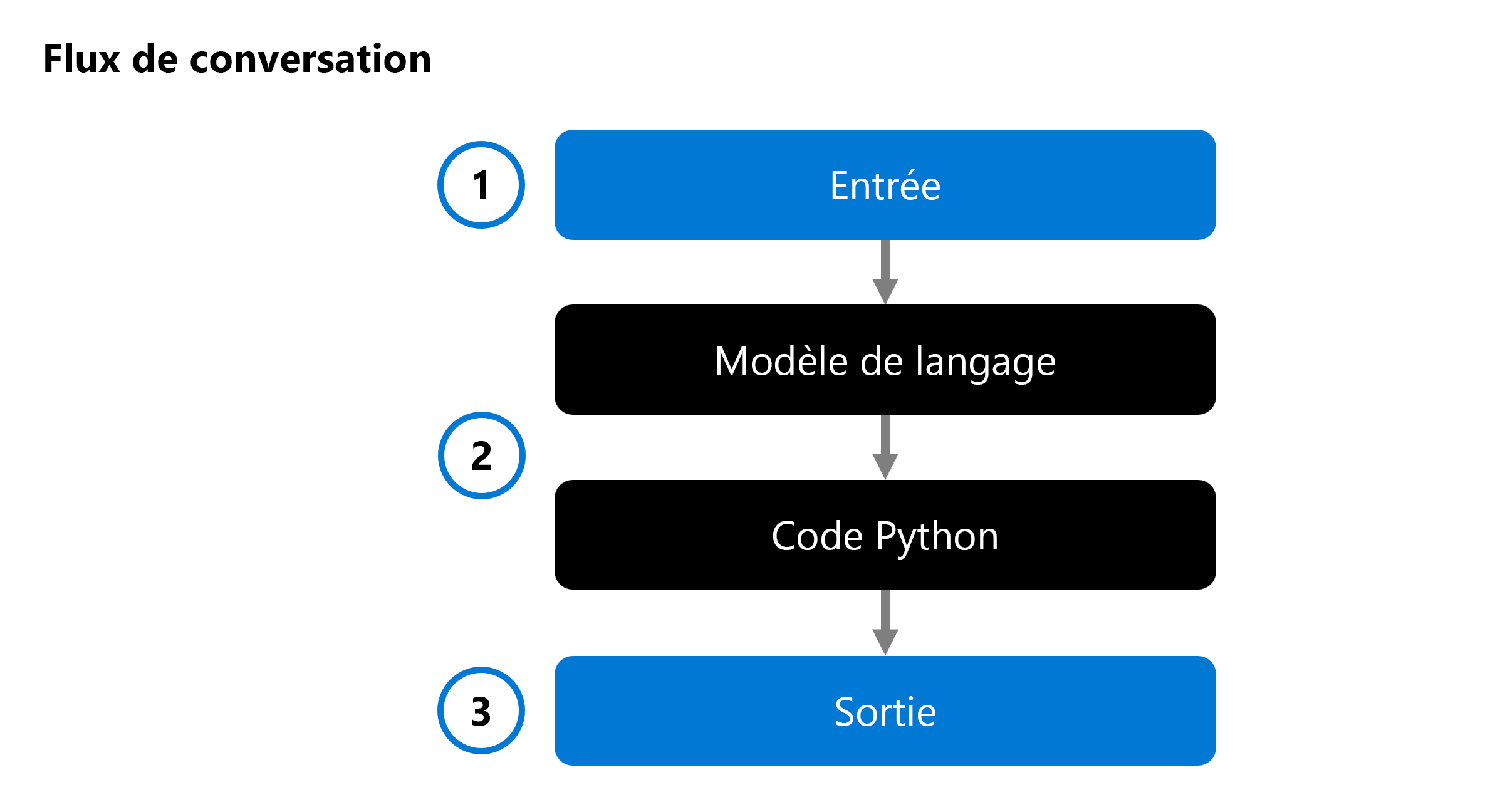
Un flux de conversation vous permet d’orchestrer des flux exécutables qui peuvent combiner plusieurs modèles de langage et de code Python. Le flux attend une entrée (1), la traite en exécutant différents nœuds (2) et génère une sortie (3). Vous pouvez évaluer un flux de conversation complet et ses composants individuels.
Lors de l’évaluation de votre solution, vous pouvez commencer par tester un modèle individuel et éventuellement tester un flux de conversation complet pour vérifier si votre application d’IA générative fonctionne comme prévu.
Examinons plusieurs approches pour évaluer votre modèle et votre flux de conversation, ou application d’IA générative.
Points de référence de modèle
Les benchmarks de modèles sont des métriques disponibles publiquement entre les modèles et les jeux de données. Ces benchmarks vous aident à comprendre comment votre modèle fonctionne par rapport à d’autres. Voici quelques-uns des benchmarks couramment utilisés :
- Justesse : Compare le texte généré par le modèle avec une réponse correcte en fonction du jeu de données. Le résultat est de « un » si le texte généré correspond exactement à la réponse, sinon il est de « zéro ».
- Cohérence : Mesure si la sortie du modèle est harmonieuse, se lit naturellement et ressemble à un langage semblable à celui de l’homme
- Fluidité : Évalue la façon dont le texte généré respecte les règles grammaticales, les structures syntaxiques et l’utilisation appropriée du vocabulaire, ce qui aboutit à des réponses linguistiquement correctes et naturelles.
- Similarité à GPT : Quantifie la similarité sémantique entre une phrase de vérité de base (ou un document) et la phrase de prédiction générée par un modèle IA.
Dans le portail Azure AI Foundry, vous pouvez explorer les benchmarks de modèles pour tous les modèles disponibles avant de déployer un modèle :

Évaluations manuelles
Les évaluations manuelles impliquent des noteurs humains qui évaluent la qualité des réponses du modèle. Cette approche fournit des aperçus sur les aspects que les mesures automatisées peuvent manquer, telles que la pertinence du contexte et la satisfaction des utilisateurs. Les évaluateurs humains peuvent évaluer les réponses en fonction de critères tels que la pertinence, la valeur informative et l’engagement.
Métriques d’apprentissage automatique traditionnel
Les mesures d’apprentissage automatique traditionnelles sont également précieuses pour évaluer les performances du modèle. L’une de ces mesures est le Score F1, qui mesure la proportion du nombre de mots partagés entre les réponses de vérité générées et de base. Le score F1 est utile pour les tâches telles que la classification de texte et la récupération des informations, où la précision et le rappel sont importants.
Métriques assistées par IA
Les mesures assistées par l’IA utilisent des techniques avancées pour évaluer les performances du modèle. Ces mesures peuvent inclure :
- Mesures de risque et de sécurité : Ces mesures évaluent les risques potentiels et les problèmes de sécurité associés aux sorties du modèle. Elles permettent de s’assurer que le modèle ne génère pas de contenu nuisible ou biaisé.
- Mesures de qualité de génération : Ces mesures évaluent la qualité globale du texte généré, en prenant en compte des facteurs tels que la créativité, la cohérence et l’adhésion au style ou au ton souhaités.