Concevoir un schéma d’entrepôt de données
Comme toutes les bases de données relationnelles, un entrepôt de données contient des tables dans lesquelles les données que vous souhaitez analyser sont stockées. Généralement, ces tables sont organisées dans un schéma optimisé pour la modélisation multidimensionnelle, dans lequel des mesures numériques associées aux événements, appelées faits, peuvent être agrégées par les attributs des entités associées à plusieurs dimensions. Par exemple, des mesures associées à une commande de vente (telles que le montant payé ou la quantité d’articles commandés) peuvent être agrégées selon des attributs comme la date d’achat, le client, le magasin, etc.
Tables d’un entrepôt de données
Un modèle courant pour les entrepôts de données relationnelles consiste à définir un schéma qui inclut deux types de tables : tables de dimension et tables de faits.
Tables de dimension
Les tables de dimension décrivent les entités métier, notamment les produits, les personnes, les lieux et les dates. Les tables de dimension contiennent des colonnes pour les attributs d’une entité. Par exemple, une entité client peut avoir un prénom, un nom, une adresse e-mail et une adresse postale (composée d’un nom de rue, d’une ville, d’un code postal et d’un pays ou d’une région). En plus des colonnes d’attribut, une table de dimension contient une colonne clé unique qui identifie de manière unique chaque ligne de la table. En fait, il est courant pour une table de dimension d’inclure deux colonnes clés :
- Une clé de substitution spécifique à l’entrepôt de données et qui identifie de manière unique chaque ligne de la table de dimension dans l’entrepôt de données (généralement, un nombre entier incrémenté).
- Une clé secondaire, souvent une clé naturelle ou métier, utilisée pour identifier une instance spécifique d’une entité dans le système source transactionnel à partir duquel l’enregistrement d’entité provient (par exemple, un code de produit ou un ID client).
Notes
Pourquoi utiliser deux clés ? Il existe plusieurs bonnes raisons :
- L’entrepôt de données peut être rempli avec des données provenant de plusieurs systèmes source, ce qui peut entraîner des doublons ou des clés métier incompatibles.
- Les clés numériques simples fonctionnent généralement mieux dans les requêtes qui joignent de nombreuses tables, une situation courante dans les entrepôts de données.
- Les attributs d’entités peuvent changer au fil du temps : par exemple, un client peut modifier son adresse. Comme l’entrepôt de données est utilisé pour prendre en charge les rapports historiques, vous pouvez conserver un enregistrement pour chaque instance d’une entité à plusieurs instants; de sorte que, par exemple, les commandes de vente d’un client spécifique sont comptabilisées pour la ville dans laquelle il résidait au moment où la commande a été passée. Dans ce cas, plusieurs enregistrements client auraient la même clé métier associée à ce client, mais différentes clés de substitution pour chaque adresse discrète où le client vivait à divers moments.
Un exemple de table de dimension pour le client peut contenir les données suivantes :
| CustomerKey | CustomerAltKey | Nom | Rue | Ville | PostalCode | CountryRegion | |
|---|---|---|---|---|---|---|---|
| 123 | I-543 | Navin Jones | navin1@contoso.com | 1 Main St. | Seattle | 90000 | États-Unis |
| 124 | R-589 | Mary Smith | mary2@contoso.com | 234 190th Ave | Buffalo | 50001 | États-Unis |
| 125 | I-321 | Antoine Dubois | antoine1@contoso.com | 2 Rue Jolie | Paris | 20098 | France |
| 126 | I-543 | Navin Jones | navin1@contoso.com | 24 125th Ave. | New York | 50000 | États-Unis |
| ... | ... | ... | ... | ... | ... | ... | ... |
Notes
Notez que la table contient deux enregistrements pour Navin Jones. Ces deux enregistrements utilisent la même clé secondaire pour identifier cette personne (I-543), mais chaque enregistrement a une clé de substitution différente. Vous pouvez ainsi en déduire que le client a déménagé de Seattle à New York. Les ventes effectuées au client pendant son séjour à Seattle sont associées à la clé 123, tandis que les achats effectués après son déménagement à New York sont consignés dans l’enregistrement 126.
Outre les tables de dimension qui représentent des entités métier, il est courant pour un entrepôt de données d’inclure une table de dimension qui représente le temps. Cette table permet aux analystes de données d’agréger des données sur des intervalles temporels. Selon le type de données que vous devez analyser, la granularité la plus faible (appelée grain) d’une dimension de temps peut représenter des heures (à l’heure, à la seconde, à la milliseconde, à la nanoseconde, ou encore moins), ou des dates.
Un exemple de table de dimension horaire avec un grain au niveau de la date peut contenir les données suivantes :
| DateKey | DateAltKey | DayOfWeek | DayOfMonth | Jour de la semaine | Month | MonthName | Quarter (Trimestre) | Year |
|---|---|---|---|---|---|---|---|---|
| 19990101 | 01-01-1999 | 6 | 1 | Vendredi | 1 | Janvier | 1 | 1999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20220101 | 01-01-2022 | 7 | 1 | Samedi | 1 | Janvier | 1 | 2022 |
| 20220102 | 02-01-2022 | 1 | 2 | Dimanche | 1 | Janvier | 1 | 2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20301231 | 31-12-2030 | 3 | 31 | Mardi | 12 | Décembre | 4 | 2030 |
L’intervalle de temps couvert par les enregistrements de la table doit inclure les points les plus anciens et les plus récents dans le temps pour tous les événements associés enregistrés dans une table de faits associée. En règle générale, il existe un enregistrement pour chaque intervalle au niveau du grain approprié entre ces deux éléments.
Tables de faits
Les tables de faits stockent des détails ou des événements, par exemple, des commandes client, des soldes de stock, des taux de change, ou des relevés de température. Une table de faits contient des colonnes pour les valeurs numériques qui peuvent être agrégées par dimensions. Outre les colonnes numériques, une table de faits contient des colonnes clés qui référencent des clés uniques dans les tables de dimension associées.
Par exemple, une table de faits contenant les détails des commandes client peut inclure les données suivantes :
| OrderDateKey | CustomerKey | StoreKey | ProductKey | OrderNo | LineItemNo | Quantité | UnitPrice | Taxe | ItemTotal |
|---|---|---|---|---|---|---|---|---|---|
| 20220101 | 123 | 5 | 701 | 1001 | 1 | 2 | 2,50 | 0,50 | 5.50 |
| 20220101 | 123 | 5 | 765 | 1001 | 2 | 1 | 2,00 | 0.20 | 2.20 |
| 20220102 | 125 | 2 | 723 | 1002 | 1 | 1 | 4.99 | 0,49 | 5.48 |
| 20220103 | 126 | 1 | 823 | 1003 | 1 | 1 | 7.99 | 0.80 | 8.79 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
Les colonnes clés de dimension d’une table de faits déterminent son grain. Par exemple, la table des faits commandes inclut des clés pour les dates, les clients, les magasins et les produits. Une commande peut inclure plusieurs produits, de sorte que le grain représente des éléments de ligne pour les produits individuels vendus dans les magasins aux clients à des jours spécifiques.
Conceptions de schémas d’entrepôts de données
Dans la plupart des bases de données transactionnelles utilisées dans les applications métier, les données sont normalisées pour réduire la duplication. Mais dans un entrepôt de données, les données de dimension sont généralement dénormalisées pour réduire le nombre de jointures requises pour interroger les données.
Souvent, un entrepôt de données est organisé selon un schéma en étoile, dans lequel une table de faits est directement liée aux tables de dimension, comme le montre cet exemple :
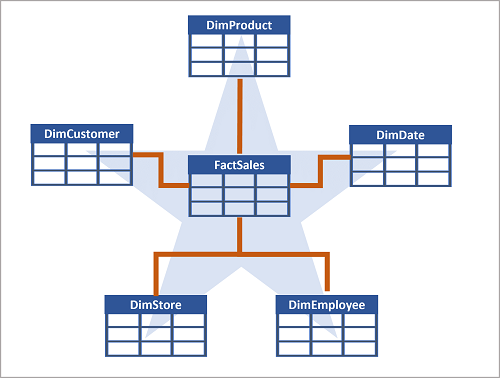
Les attributs d’une entité peuvent être utilisés pour agréger des mesures dans des tables de faits sur plusieurs niveaux hiérarchiques, par exemple pour rechercher le chiffre d’affaires total par pays ou région, ville, code postal ou client individuel. Les attributs de chaque niveau peuvent être stockés dans la même table de dimension. Mais lorsqu’une entité comporte un grand nombre de niveaux d’attribut hiérarchique ou que certains attributs peuvent être partagés par plusieurs dimensions (par exemple, les clients et les magasins ont une adresse géographique), il peut être judicieux d’appliquer une normalisation aux tables de dimension et de créer un schéma en flocon, comme illustré dans l’exemple suivant :
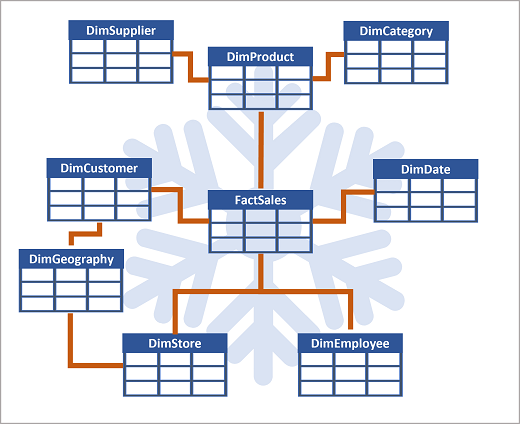
Dans ce cas, la table DimProduct a été normalisée afin de créer des tables de dimension distinctes pour les catégories de produits et les fournisseurs, et une table DimGeography a été ajoutée afin de représenter des attributs géographiques pour les clients et les magasins. Chaque ligne de la table DimProduct contient des valeurs clés pour les lignes correspondantes dans les tables DimCategory et DimSupplier, et chaque ligne des tables DimCustomer et DimStore contient une valeur clé pour la ligne correspondante dans la table DimGeography.