Conception pour la surveillance
Dans le cadre d’une architecture d’opérations d’apprentissage automatique (MLOps), vous devez réfléchir à la façon de surveiller votre solution d’apprentissage automatique.
La surveillance est bénéfique dans n’importe quel environnement MLOps. Vous souhaiterez surveiller le modèle, les données et l’infrastructure pour collecter des métriques qui vous aideront à décider des étapes suivantes nécessaires.
Analyser le modèle
Le plus souvent, vous souhaitez surveiller les performances de votre modèle. Pendant le développement, vous utilisez MLflow pour entraîner et suivre vos modèles Machine Learning. Selon le modèle que vous entraînez, vous pouvez utiliser différentes métriques pour évaluer si le modèle fonctionne comme prévu.
Pour surveiller un modèle en production, vous pouvez utiliser le modèle entraîné pour générer des prédictions sur un petit sous-ensemble de nouvelles données entrantes. En générant les métriques de performances sur ces données de test, vous pouvez vérifier si le modèle atteint toujours son objectif.
En outre, vous pouvez également surveiller les problèmes liés à l’intelligence artificielle (IA) responsable. Par exemple, si le modèle effectue des prédictions équitables.
Avant de pouvoir surveiller un modèle, il est important de déterminer les métriques de performances que vous souhaitez surveiller et le point de référence pour chaque métrique. Quand devez-vous être averti que le modèle n’est plus précis ?
Surveiller les données
En général, vous formez un modèle de Machine Learning à l’aide d’un jeu de données historique qui est représentatif des nouvelles données que votre modèle recevra lors du déploiement. Toutefois, au fil du temps, des tendances peuvent modifier le profil des données, ce qui rend votre modèle moins précis.
Par exemple, supposons qu’un modèle soit formé pour prédire la consommation de gaz attendue d’une automobile en fonction du nombre de cylindres, de la taille du moteur, du poids et d’autres caractéristiques. Au fil du temps, à mesure que la fabrication et les technologies de moteur progressent, l’efficacité type des véhicules peut s’améliorer de façon spectaculaire, rendant les prédictions effectuées par le modèle formé sur des données plus anciennes moins précises.
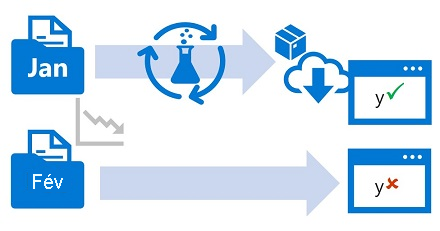
Cette modification des profils de données entre les données d’entraînement et actuelles est connue sous le nom de dérive de données, et cela peut être un problème important pour les modèles prédictifs utilisés en production. Il est donc important de pouvoir surveiller la dérive des données au fil du temps et de reformer les modèles en fonction des besoins afin de conserver une précision prédictive.
Surveiller l’infrastructure
Outre la surveillance du modèle et des données, vous devez également surveiller l’infrastructure pour réduire les coûts et optimiser les performances.
Tout au long du cycle de vie du Machine Learning, vous utilisez le calcul pour entraîner et déployer des modèles. Avec les projets Machine Learning dans le cloud, le calcul peut être l’une de vos dépenses les plus importantes. Vous souhaitez donc analyser votre calcul et savoir s’il est efficace.
Par exemple, vous pouvez surveiller l’utilisation de votre calcul pendant l’entraînement et pendant le déploiement. En examinant l’utilisation du calcul, vous savez si vous pouvez effectuer un scale-down de votre calcul provisionné, ou si vous devez effectuer un scale-out pour éviter les contraintes de capacité.
Conseil
En savoir plus sur la supervision de l’espace de travail Azure Machine Learning et de ses ressources.