Analyser le modèle
En tant que scientifique des données, vous souhaitez entraîner le meilleur modèle Machine Learning. Pour implémenter le modèle, vous souhaitez le déployer sur un point de terminaison et l’intégrer à une application.
Après un certain temps, vous souhaitez réentraîner le modèle. Par exemple, vous pouvez réentraîner le modèle lorsque vous avez plus de données d’entraînement.
En général, une fois que vous avez entraîné un modèle Machine Learning, vous souhaitez préparer le modèle pour un déploiement à l’échelle de l’entreprise. Pour préparer le modèle et l’opérationnaliser, vous souhaitez :
- Convertir l’entraînement du modèle en pipeline robuste et reproductible.
- Tester le code et le modèle dans un environnement de développement.
- Déployer le modèle dans un environnement de production.
- Automatiser le processus de bout en bout.
Concevoir une architecture MLOps
Faire passer un modèle en production signifie que vous devez mettre à l’échelle votre solution et collaborer avec d’autres équipes. Avec les autres scientifiques des données, les ingénieurs données et l’équipe d’infrastructure, vous pouvez choisir d’utiliser l’approche suivante :
- Stockez toutes les données dans un stockage Blob Azure, géré par l’ingénieur données.
- L’équipe d’infrastructure crée les ressources Azure nécessaires, comme l’espace de travail Azure Machine Learning.
- Les scientifiques des données se concentrent sur ce qu’ils font le mieux : développer et entraîner le modèle (boucle interne).
- Les ingénieurs Machine Learning déploient les modèles entraînés (boucle externe).
Par conséquent, votre architecture MLOps comprend les éléments suivants :
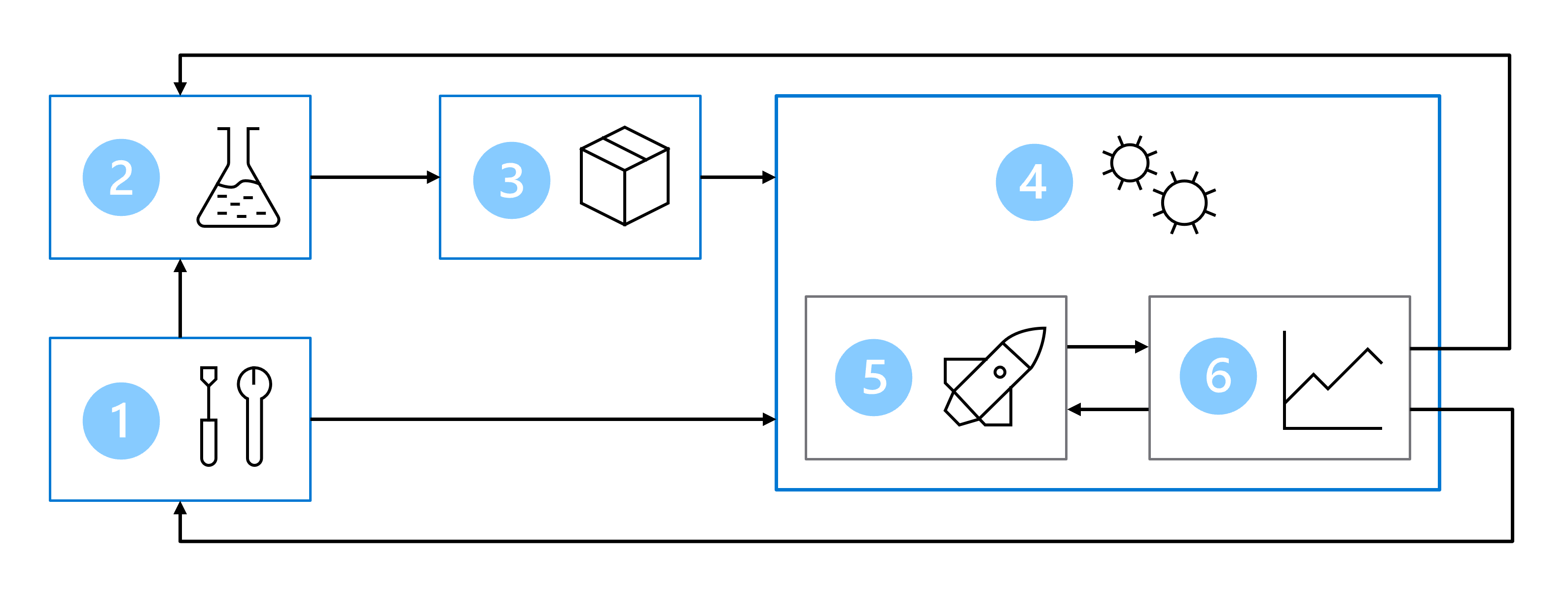
- Installation : créer toutes les ressources Azure nécessaires pour la solution.
- Développement de modèle (boucle interne) : explorer et traiter les données pour entraîner et évaluer le modèle.
- Intégration continue : empaqueter et inscrire le modèle.
- Déploiement de modèle (boucle externe) : déployer le modèle.
- Déploiement continu : tester le modèle et le promouvoir dans un environnement de production.
- Monitoring : superviser les performances du modèle et du point de terminaison.
Lorsque vous travaillez avec des équipes plus importantes, vous n’êtes pas censé être responsable de toutes les parties de l’architecture MLOps en tant que scientifique des données. En tant que scientifique des données, pour préparer votre modèle pour MLOps, vous devez réfléchir à la conception des processus de monitoring et de réentraînement.
Surveiller le niveau de performance du modèle
Si vous souhaitez réentraîner le modèle uniquement si nécessaire, vous pouvez surveiller le niveau de performance du modèle et tout ce qui peut l’influencer :
- Suivre le niveau de performance : Surveillez les métriques clés de votre modèle, telles que la précision et le score F1, pour évaluer son efficacité.
- Détecter une dérive de données : La dérive de données se produit lorsque les propriétés statistiques des données d’entrée changent au fil du temps. La détection de la dérive de données implique de surveiller les distributions des fonctionnalités d’entrée ou des variables cibles pour identifier toute modification importante susceptible d’affecter les performances du modèle.
- Identifier une dérive de concept : La dérive de concept fait référence aux modifications de la relation entre les fonctionnalités d’entrée et la variable cible. La dérive de concept peut se produire lorsque les modèles sous-jacents dans les données évoluent. L’identification de la dérive de concept implique de suivre les performances du modèle sur les nouvelles données et de rechercher des changements dans les relations d’étiquette de fonctionnalité.
Recycler le modèle
En règle générale, il existe deux approches pour réentraîner un modèle :
- En fonction d’une planification : lorsque vous savez que vous avez toujours besoin de la dernière version du modèle, vous pouvez décider de réentraîner votre modèle chaque semaine, ou tous les mois, en suivant une planification.
- En fonction de métriques : si vous souhaitez réentraîner votre modèle quand cela devient nécessaire, vous pouvez surveiller les performances et la dérive des données du modèle pour déterminer quand vous devez réentraîner le modèle.
Dans les deux cas, vous devez concevoir pour le réentraînement. Pour réentraîner facilement votre modèle, vous devez préparer votre code pour l’automatisation.
Préparer votre code
Dans l’idéal, vous devez entraîner des modèles avec des scripts plutôt que des notebooks. Les scripts sont mieux adaptés à l’automatisation. Vous pouvez ajouter des paramètres à un script et modifier les paramètres d’entrée, comme les données d’apprentissage ou les valeurs d’hyperparamètres. Lorsque vous paramétrez vos scripts, vous pouvez facilement réentraîner le modèle sur de nouvelles données si nécessaire.
Une autre chose importante pour préparer votre code consiste à héberger le code dans un référentiel central. Un référentiel fait référence à l’emplacement où tous les fichiers pertinents d’un projet peuvent être stockés. Avec les projets Machine Learning, les référentiels basés sur Git sont idéaux pour obtenir un contrôle de code source.
Lorsque vous appliquez le contrôle de code source à votre projet, vous pouvez facilement collaborer dessus. Vous pouvez affecter une personne pour améliorer le modèle en mettant à jour le code. Vous pouvez explorer les modifications passées et examiner les modifications avant qu’elles ne soient validées dans le référentiel principal.
Automatiser votre code
Lorsque vous souhaitez exécuter automatiquement votre code, vous pouvez configurer des travaux Azure Machine Learning pour exécuter des scripts. Dans Azure Machine Learning, vous pouvez également créer et planifier des pipelines pour exécuter des scripts.
Si vous souhaitez que les scripts s’exécutent en fonction d’un déclencheur ou d’un événement se produisant en dehors d’Azure Machine Learning, vous déclenchez le travail Azure Machine Learning à partir d’un autre outil.
Deux outils couramment utilisés dans les projets MLOps sont Azure DevOps et GitHub (Actions). Ces deux outils vous permettent de créer des pipelines d’automatisation et peuvent déclencher des pipelines Azure Machine Learning.
En tant que scientifique des données, vous préférez peut-être travailler avec le Kit de développement logiciel (SDK) Python Azure Machine Learning. Toutefois, lorsque vous utilisez des outils tels qu’Azure DevOps et GitHub, vous pouvez préférer configurer les ressources et les travaux nécessaires avec l’extension CLI Azure Machine Learning. Azure CLI est conçu pour automatiser les tâches et s’intègre bien à Azure DevOps et GitHub.
Conseil
Si vous souhaitez en savoir plus sur MLOps, explorez la Présentation des opérations d’apprentissage automatique (MLOps) ou essayez de créer votre premier Pipeline d’automatisation MLOps avec GitHub Actions