Intégrer un modèle
Vous devez planifier la façon dont vous intégrez le modèle, car cela affecte la manière dont vous entraînez le modèle ou le type de données d’entraînement que vous utilisez. Pour intégrer le modèle, vous devez déployer un modèle sur un point de terminaison. Vous pouvez déployer un modèle sur un point de terminaison pour des prédictions en temps réel ou par lots.
Déployer un modèle sur un point de terminaison
Lorsque vous entraînez un modèle, l’objectif est souvent d’intégrer le modèle à une application.
Pour intégrer facilement un modèle à une application, vous pouvez utiliser des points de terminaison. En termes simples, un point de terminaison peut être une adresse web qu’une application peut appeler pour récupérer un message.
Lorsque vous déployez un modèle sur un point de terminaison, vous avez deux options :
- Obtenir des prédictions en temps réel
- Obtenir des prédictions par lots
Obtenir des prédictions en temps réel
Si vous souhaitez que le modèle attribue un score aux nouvelles données au fur et à mesure, vous avez besoin de prédictions en temps réel.
Des prédictions en temps réel sont souvent nécessaires lorsqu’un modèle est utilisé par une application telle qu’une application mobile ou un site web.
Imaginez que vous disposez d’un site web qui contient votre catalogue de produits :
- Un client sélectionne un produit sur votre site web, tel qu’une chemise.
- En fonction de la sélection du client, le modèle recommande immédiatement d’autres éléments du catalogue. Le site web affiche les recommandations du modèle.

Un client peut sélectionner un produit dans la boutique en ligne à tout moment. Vous souhaitez que le modèle trouve les recommandations presque immédiatement. Le temps nécessaire à la page web pour charger et afficher les détails de la chemise correspond au temps nécessaire pour obtenir les recommandations ou les prédictions. Par conséquent, lorsque la chemise est affichée, les recommandations peuvent également être affichées.
Obtenir des prédictions par lots
Si vous souhaitez que le modèle attribue un score aux nouvelles données par lots et enregistre les résultats sous la forme d’un fichier ou d’une base de données, vous avez besoin de prédictions par lots.
Par exemple, vous pouvez entraîner un modèle qui prédit les ventes de jus d’orange pour les semaines à venir. En prédisant les ventes de jus d’orange, vous pouvez vous assurer que l’offre est suffisante pour répondre à la demande attendue.
Imaginez que vous soyez en train d’examiner toutes les données historiques de ventes dans un rapport. Vous devez inclure les ventes prédites dans ce même rapport.
Même si le jus d’orange se vend tous les jours, vous ne voulez calculer la prévision qu’une fois par semaine. Vous pouvez collecter les données de ventes tout au long de la semaine et appeler le modèle uniquement lorsque vous disposez des données de ventes de la semaine entière. Une collection de points de données est appelée « lot ».
Choisir entre un déploiement en temps réel ou par lots
Pour choisir entre une solution de déploiement en temps réel ou par lots, vous devez vous poser les questions suivantes :
- À quelle fréquence les prédictions doivent-elles être générées ?
- À quel moment les résultats sont-ils nécessaires ?
- Les prédictions doivent-elles être générées individuellement ou par lots ?
- Quelle est la quantité de puissance de calcul nécessaire pour exécuter le modèle ?
Identifier la fréquence de scoring nécessaire
Parmi les scénarios courants figure l’utilisation d’un modèle pour attribuer un score à de nouvelles données. Avant de pouvoir obtenir des prédictions en temps réel ou par lots, vous devez d’abord collecter les nouvelles données.
Il existe différentes façons de générer ou de collecter des données. Les nouvelles données peuvent également être collectées à différents intervalles de temps.
Par exemple, vous pouvez collecter des données de température à partir d’un appareil IoT (Internet des objets) toutes les minutes. Vous pouvez obtenir des données transactionnelles chaque fois qu’un client achète un produit sur votre boutique en ligne. Vous pouvez également extraire des données financières d’une base de données tous les trois mois.
En règle générale, il existe deux types de cas d’usage :
- Vous avez besoin du modèle pour attribuer un score aux nouvelles données dès qu’elles arrivent.
- Vous pouvez planifier ou déclencher le modèle pour attribuer un score aux nouvelles données que vous avez collectées au fil du temps.
Le fait que vous souhaitiez des prédictions en temps réel ou par lots ne dépend pas nécessairement de la fréquence à laquelle les nouvelles données sont collectées. En effet, cela dépend de la fréquence et de la rapidité de génération des prédictions.
Si vous avez besoin des prédictions du modèle dès que de nouvelles données sont collectées, choisissez les prédictions en temps réel. Si les prédictions du modèle ne sont consommées qu’à certains moments, utilisez les prédictions par lots.
Choisir le nombre de prédictions
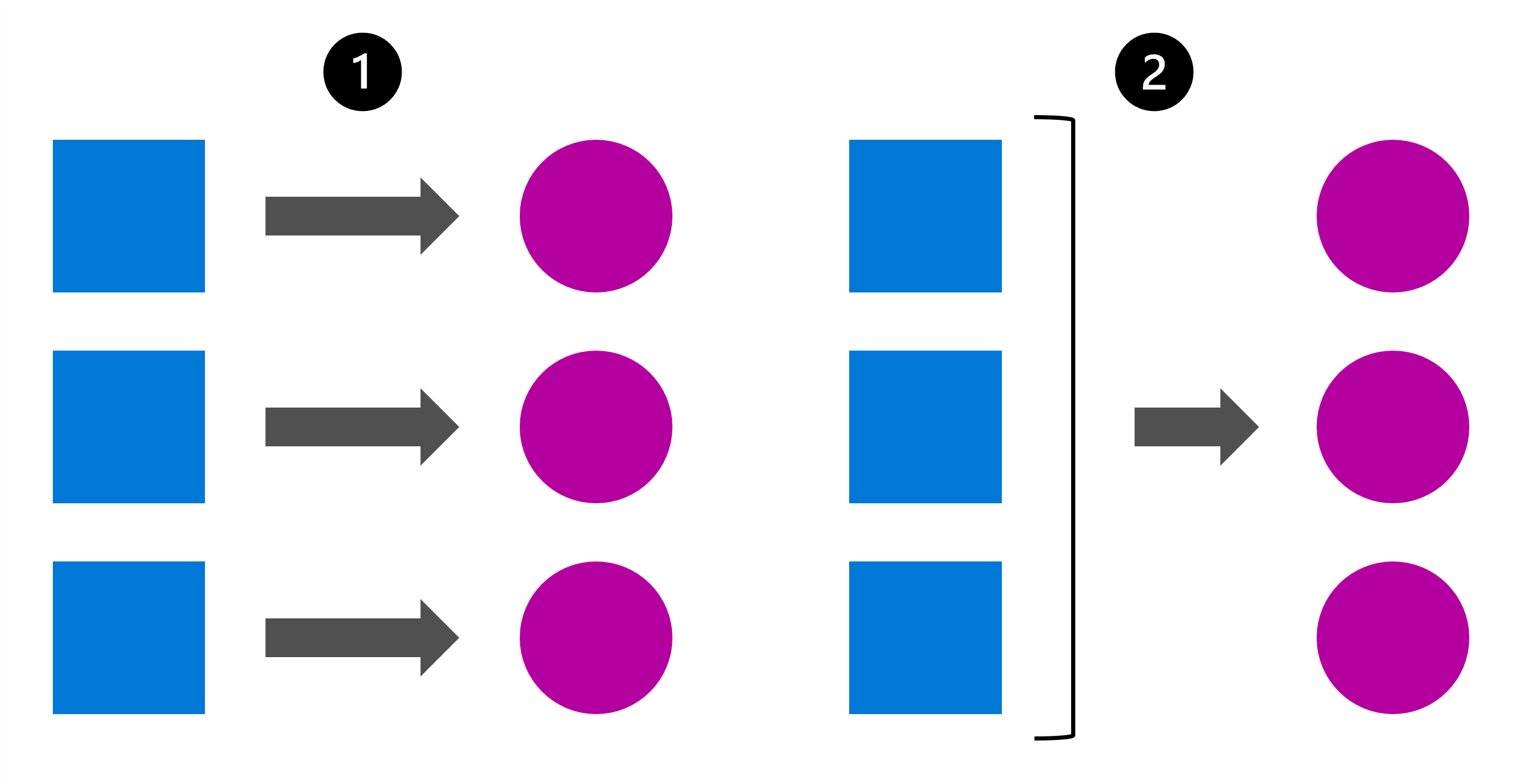
Une autre question importante à se poser est de savoir si les prédictions doivent être générées individuellement ou par lots.
Un moyen simple d’illustrer la différence entre les prédictions individuelles et par lots consiste à imaginer un tableau. Supposons que vous ayez un tableau de données client où chaque ligne représente un client. Pour chaque client, vous disposez de données démographiques et de données comportementales, telles que le nombre de produits qu’il a achetés dans votre boutique en ligne et la date de son dernier achat.
Sur la base de ces données, vous pouvez prédire l’attrition clients, c’est-à-dire si un client achètera à nouveau sur votre boutique en ligne.
Une fois que vous avez entraîné le modèle, vous pouvez décider de générer des prédictions :
- Individuellement : le modèle reçoit une seule ligne de données et retourne un résultat indiquant si ce client va ou non acheter à nouveau.
- Par lots : le modèle reçoit plusieurs lignes de données d’un tableau et retourne un résultat indiquant pour chaque client s’il va ou non acheter à nouveau. Les résultats sont rassemblés dans un tableau qui contient toutes les prédictions.
Vous pouvez également générer des prédictions individuelles ou par lots lorsque vous utilisez des fichiers. Par exemple, lorsque vous utilisez un modèle de vision par ordinateur, vous devrez peut-être attribuer un score à une seule image ou à un lot d’images.
Prendre en compte le coût du calcul
En plus du calcul utilisé pour l’entraînement d’un modèle, vous avez également besoin de calcul pour le déploiement du modèle. Vous utiliserez différents types de calcul, selon que vous déployez le modèle sur un point de terminaison en temps réel ou par lots. Pour choisir entre un déploiement sur un point de terminaison en temps réel ou par lots, vous devez prendre en compte le coût de chaque type de calcul.
Si vous avez besoin de prédictions en temps réel, vous aurez besoin d’un calcul toujours disponible et capable de retourner les résultats (quasi) immédiatement. Les technologies de conteneur comme Azure Container Instance (ACI) et Azure Kubernetes Service (AKS) sont idéales pour ces scénarios, car elles fournissent une infrastructure légère pour votre modèle déployé.
Toutefois, lorsque vous déployez un modèle sur un point de terminaison en temps réel et utilisez cette technologie de conteneur, le calcul est constamment exécuté. Une fois qu’un modèle est déployé, vous payez en continu pour le calcul. En effet, vous ne pouvez pas suspendre ni arrêter le calcul puisque le modèle doit toujours être disponible pour des prédictions immédiates.
Sinon, si vous avez besoin de prédictions par lots, vous aurez besoin d’un calcul capable de gérer une charge de travail volumineuse. Dans l’idéal, vous devrez utiliser un cluster de calcul qui peut attribuer un score aux données dans des lots parallèles à l’aide de plusieurs nœuds.
Lorsque vous utilisez des clusters de calcul qui peuvent traiter des données dans des lots parallèles, le calcul est provisionné par l’espace de travail lorsque le scoring par lots est déclenché, et revu à la baisse à 0 nœud lorsqu’il n’y a pas de nouvelles données à traiter. En permettant à l’espace de travail d’effectuer un scale-down sur un cluster de calcul inactif, vous pouvez faire des économies substantielles.